
DeepSpeed简介和使用说明
本文简述深度学习中的主流分布式加速计算框架: DeepSpeed 并介绍其使用方法.
何为 DeepSpeed
在人工智能浪潮下, 涌现出了大量训练和部署大型语言模型的需求. 大模型的训练和部署对硬件的需求极高, 往往需要昂贵且调度复杂的多机多卡GPU集群. 现有的开源机器学习框架在单机多卡, 多机多卡平台上存在训练效率低, 训练速度慢等显著缺点, 而 DeepSpeed 框架的目的是在分布式模型训练和部署的业务场景中高效, 便捷和充分地利用硬件资源.
DeepSpeed 由微软开发, 基于 PyTorch 构建, 使用了模型并行化, 梯度累积等加速技术, 属于基于深度学习训练框架和深度学习模型之间的 模型训练优化框架.
DeepSpeed 的软件架构包括了 APIs, Runtime 和内核组件三个部分.
APIs 为暴露给用户的简单 API 接口, 用户通过调用这些借口, 在 ds_config.json 中明确框架配置即可轻松地进行模型的训练和推理.
Runtime 为 DeepSpeed 的核心运行时组件, 承担将模型训练任务分布式地部署到不同设备上的功能, 具体任务包括数据分区, 模型分区, 系统优化, 故障检测, 模型 CheckPoint 的保存和加载等.
底层内核组件则使用 C++ 和 CUDA 实现, 最高程度地优化计算和设备间的通信过程.
使用方法: 以 LLaMA-Factory为例
下面以大语言模型训练和推理框架 LLaMA-Factory 为例介绍如何使用 DeepSpeed 执行分布式模型训练.
使用DeepSpeed加速分布式模型训练
以在双4090开发机上使用 qLoRA 微调 Qwen-14b 模型为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
NCCL_P2P_DISABLE="1" NCCL_IB_DISABLE="1" deepspeed --num_gpus 2 --master_port=9901 src/train_bash.py \
--deepspeed ds_config.json \
--stage sft \
--do_train True \
--model_name_or_path /home/tomlu/LLM_experiment/models/Qwen-14B-Chat \
--finetuning_type lora \
--template qwen \
--dataset extra_tone_240,knowledge_qa_60,self_cognition,training_tone_200 \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 20.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 200 \
--lora_rank 12 \
--lora_dropout 0.4 \
--lora_target c_attn \
--output_dir saves/Qwen-14B-Chat/lora/train_5e-5_epoch_20_lora_rank_12_random_dropout_4e-1 \
--quantization_bit 4 \
--plot_loss True
我们下面详细解释此命令中各参数的含义.
NCCL 为 NVIDIA Collective Communications Library 的缩写, 它是 NVIDIA 开发的多卡通信框架. 常见参数如下:
| 参数名 | 参数意义 | 参数解释 |
|---|---|---|
NCCL_P2P_DISABLE |
禁用P2P(Peer to Peer)传输 | P2P传输使用CUDA, NVLink或PCI直接实现GPU之间的数据传输和访问. |
NCCL_IB_DISABLE |
禁用IB/RoCE传输 | IB (Infinity Band) 为一种用于高性能计算的网络通信标准. |
由于 RTX 4090 不支持上述两种技术, 在使用 DeepSpeed 进行单机双卡分布式训练时需声明对应的环境变量值, 禁用上述两种通信方法.
--num_gpus 2 参数声明参与计算的 GPU 数量为 $2$. 默认情况下, 该参数等价于声明 CUDA_VISIBLE_DEVICES=”0,1“.
--naster_port=0991 参数声明参与计算的主节点端口号. 由于本例中只有一个节点参与分布式计算, 因此无需继续声明 主节点IP地址, 节点数 等参数.
--deepspeed ds_config.json 声明了 DeepSpeed 框架推理配置文件的路径. 我们将在下面一节中描述该 json 配置文件的编写方法.
除此以外, 其他的参数均是传递给 LLaMA-Factory 封装好的 PEFT 模型训练框架的, 此处不再过多介绍参数的用途和赋值含义.
编写 json 配置文件
DeepSpeed 的配置文件允许用户简单便捷地调整和选择框架的加速等级和不同加速算法/功能的启用与否.
DeepSpeed 实现了 ZeRO-DP技术, 允许我们设定三种不同的加速等级, 分别为 ZeRO Tier1(优化器状态切分), ZeRO Tier2(在Tier1基础上叠加梯度切分) 和 ZeRO Tier3(在Tier2基础上叠加参数切分):
-
优化器状态切分($P_{\text{os}}$,
Optimizer State Partitioning): 该等级将优化器的状态 (如动量) 切分并分布在所有的计算卡上. 这样可以减少每张计算卡需要存储的优化器状态的大小, 从而降低内存使用量. -
梯度切分 ($P_{\text{g}}$,
Gradient Partitioning): 该等级将计算出的梯度切分并分布在所有的计算卡上. 这样可以减少每张计算卡需要存储的梯度的大小, 从而降低内存使用量. -
参数切分($P_{\text{p}}$,
Parameter Partitioning): 该等级将模型的参数切分并分布在所有的计算卡上, 减少每张计算卡需要存储的参数的大小, 从而降低内存使用量.
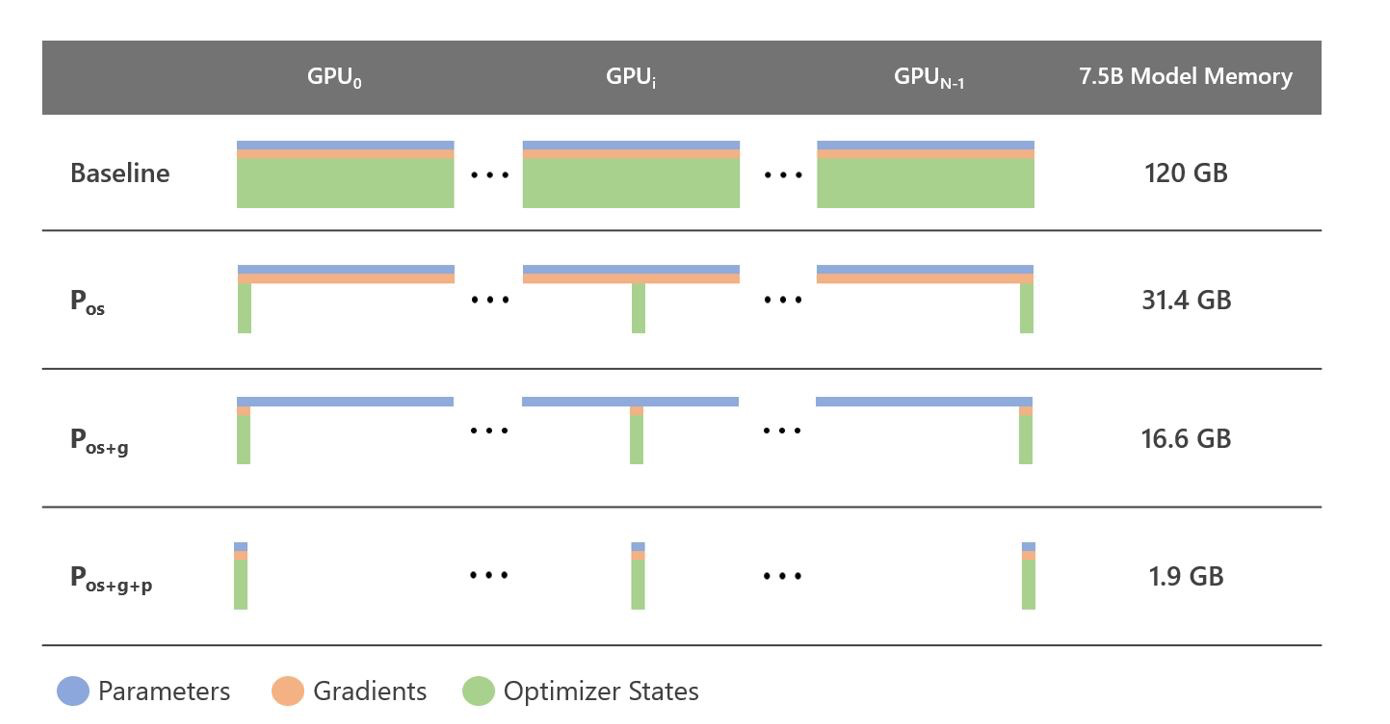
由此有下列的 json 参数配置示例:
-
ZeRO-Tier 0等级不使用任何状态切分策略, 等同于DDP(分布式数据并行, Distributed Data Parallel): 复制模型到每个处理器, 并将训练数据切分到不同的处理器上进行训练, 然后同步各个处理器的梯度来实现模型的并行训练, 存在通信开销大, 负载不均衡, 显存占用高 (每个处理器都需完整存储模型和优化器状态) 等多种劣势.1 2 3
"zero_optimization": { "stage": 0 }
-
ZeRO-Tier 1等级使用 $P_{\text{os}}$ 切分策略, 将优化器的状态进行切分:1 2 3
"zero_optimization": { "stage": 1 }
-
ZeRO-Tier 2等级使用 $P_{\text{os+g}}$ 切分策略, 将优化器的状态和梯度进行切分:1 2 3 4 5 6 7 8 9
"zero_optimization": { "stage": 2, "allgather_partitions": true, "allgather_bucket_size": 3e8, "overlap_comm": true, "reduce_scatter": true, "reduce_bucket_size": 3e8, "contiguous_gradients": true }
其中:
-
allgather_partitions: 在每个步骤结束时, 从所有GPU中选择使用allgather集体操作或一系列广播集体操作之间的方式,以收集更新后的参数. -
allgather_bucket_size: 调节Allgather操作的分桶大小. -
overlap_comm: 该参数决定是否在计算和通信之间进行重叠. 若设置为true, 则在计算梯度时也会进行梯度的通信, 可以提高训练的效率. -
reduce_scatter: 该参数决定是否在所有的处理器上进行梯度的下降和分散. -
reduce_bucket_size: 该参数类似于allgather_bucket_size, 用于控制Allreduce操作的分桶大小. Allreduce操作是将所有进程的某个张量进行规约(如求和), 并将结果广播回所有进程. 将张量划分为较大的桶可以更高效地传输数据, 但显存占用也更大. -
contiguous_gradients: 该参数决定是否使梯度在内存中连续: 在梯度产生时是否将其复制到某个连续的缓冲区中从而避免内存碎片化.
-
-
ZeRO-Tier 3等级使用 $P_{\text{os+g+p}}$ 切分策略, 将优化器的状态, 梯度和参数进行切分:1 2 3 4 5 6 7 8 9 10 11 12 13 14
{ "zero_optimization": { "stage": 3, "overlap_comm": true, "reduce_bucket_size": "auto", "contiguous_gradients": true, "sub_group_size": 1e9, "stage3_prefetch_bucket_size": "auto", "stage3_param_persistence_threshold": "auto", "stage3_max_live_parameters": 1e9, "stage3_max_reuse_distance": 1e9, "stage3_gather_16bit_weights_on_model_save": true } }
其中:
-
sub_group_size控制每一个epoch中, 优化器参数更新的粒度: 参数会被分组到大小为sub_group_size的桶中, 每个桶依次执行一次更新. -
stage3_prefetch_bucket_size: 设置预取参数的固定缓冲区大小. -
stage3_max_live_parameters: 保留在GPU上的完整参数数量的上限. -
stage3_max_reuse_distance: 根据参数在未来何时再次使用的指标来决定是舍弃还是保留参数. 如果一个参数在不久的将来会再次被使用 (小于stage3_max_reuse_distance), 则会保留该参数以减少通信开销. -
stage3_gather_16bit_weights_on_model_save: 在保存模型时是否启用模型FP16权重合并.
-
下面讨论 DeepSpeed 的混合精度训练:
使用 fp16 低精度训练时, 需在 ds_config.json 中加入下列设置:
1
2
3
4
5
6
7
8
"fp16": {
"enabled": "true",
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
-
loss_scale: 控制FP16训练的损失缩放值, 若设为 $0$ 则启用动态损失缩放. -
initial_scale_power: 控制初始动态损失比例值的幂. -
loss_scale_window: 控制动态损失缩放值增加/减少的窗口范围. -
hysteresis: 控制动态损失缩放中的延迟位移. -
min_loss_scale: 控制最小的动态损失比例值.
加入下列的配置可启用更快的 BF16 浮点计算:
1
2
3
"bf16": {
"enabled": true
}
参考:
- https://zhuanlan.zhihu.com/p/650824387
- https://blog.csdn.net/qq_40859560/article/details/133749655
- https://zhuanlan.zhihu.com/p/624412809
- https://zhuanlan.zhihu.com/p/660815629
- https://www.microsoft.com/en-us/research/blog/zero-infinity-and-deepspeed-unlocking-unprecedented-model-scale-for-deep-learning-training/