
注意力机制长文
注意力机制源于对自然语言处理领域解决 Seq2seq 问题的经典神经网络结构: RNN (循环神经网络) 的改进, 因其接近直觉的 “基于注意力和重要性对数据中元素和其他元素之间的相关性” 的逻辑设计, 在包括了自然语言处理, 计算机视觉任务, 多模态视觉语言模型等不同领域均展现出了强大的潜力和泛用性.
本文将尝试对注意力机制的起源和主流使用场景进行简要的总结, 并对其基本原理和发展沿革进行谨慎的解释和描述.
我们首先可以从直觉上体会认知任务中 “注意力” 的有效性和重要性. 我们的 视觉注意力 使我们事实上以 “高关注度” 的模式观察图片的特定区域, 而对其他区域的感知则是 “低关注度” 的: 我们在看到图像时会本能地分配大脑有限的注意力资源, 将视线聚焦在更重要的目标上. 如下图所示, 人们的注意力会更多地投入到截图中的人脸, 文本标题和段落首句等关键的位置上.

同样地, 如果将图像抠掉一块, 我们也可以根据图片中剩余的信息 “脑补” 出被扣除的内容可能是什么. 以上图为例, 我们可以基于耳朵, 头发和下颚等关键信息推测出图中婴儿被遮盖的部分显然是他的侧脸, 而尿布, 四肢等元素则无助于我们对婴儿脸部内容的预测.
除了图像信息外, 我们也能在文本处理任务中观察到 文本注意力 的关键作用. 在给定的句子中, 单词之间的关系存在明显的差异, 且这样的差异往往由其语义信息所决定. 在下图的例子中, “green” 和 “apple” 这一对单词之间的 相关性 就要显著高于 “eating” 和 ”green“. 在我们看到这句话时, 我们会本能地预测和把握高相关性的单词对, 并通过这种方式正确地理解句子的含义:
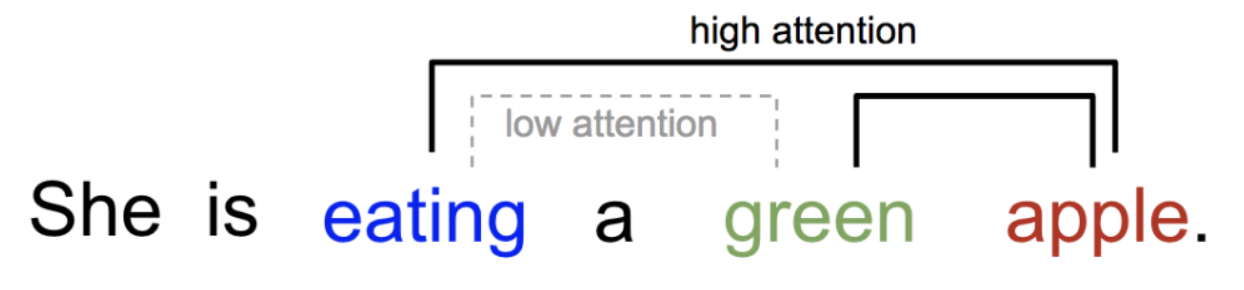
显然, 在上面的例子中, 如果计算机视觉/自然语言处理深度学习神经网络具备了理解和区分输入信息中不同区域 重要性 或 相关性 的能力, 则它们更有可能准确理想地完成 图片补全, 目标检测, 内容理解 等任务.
深度学习中的注意力机制在本质上被广义地理解为 描述输入数据中不同区域重要性的权重向量. 它可以 定量 地描述输入数据中 目标元素 和 其他元素 之间 相关性的强弱.
其基本思想为: 在处理 序列化 的数据时, 每个元素都与给定序列中的 其他所所有元素 而非相邻元素 建立相关性的关联, 由此通过计算元素之间的相对重要性来 自适应 地捕捉元素之间的 长距离依赖关系.
下面, 我们从注意力机制的起源开始, 逐步描述注意力机制的发展演变和主要使用场景.
Bahdanau 注意力机制 (Additive Attention)
在讨论注意力机制的原始形式前, 首先我们需要再向前回溯一步, 回顾自然语言处理领域的一个经典问题: Seq2Seq (序列到序列) 问题.
Seq2Seq 模型于 $2014$ 年在论文: Sequence to Sequence Learning with Neural Networks 和 Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation 中提出, 将自然语言处理问题建模为 从任意长度的输入序列 (源序列) 转换为新的输出序列 (目标序列) 的过程, 在机器翻译, 对话问答, 内容理解等任务上都取得了在当时优秀的表现.
一般地, Seq2Seq 模型均由 编码器 (Encoder) 和 解码器 (Decoder) 两部分组成:
-
前者负责处理输入序列, 将其中包含的信息压缩为 固定长度 的 上下文向量 (
Context Vector), 由此实现对输入信息的总结和抽象化表示. -
后者负责对上下文向量进行 变换 并生成输出序列, 也就是 解码:
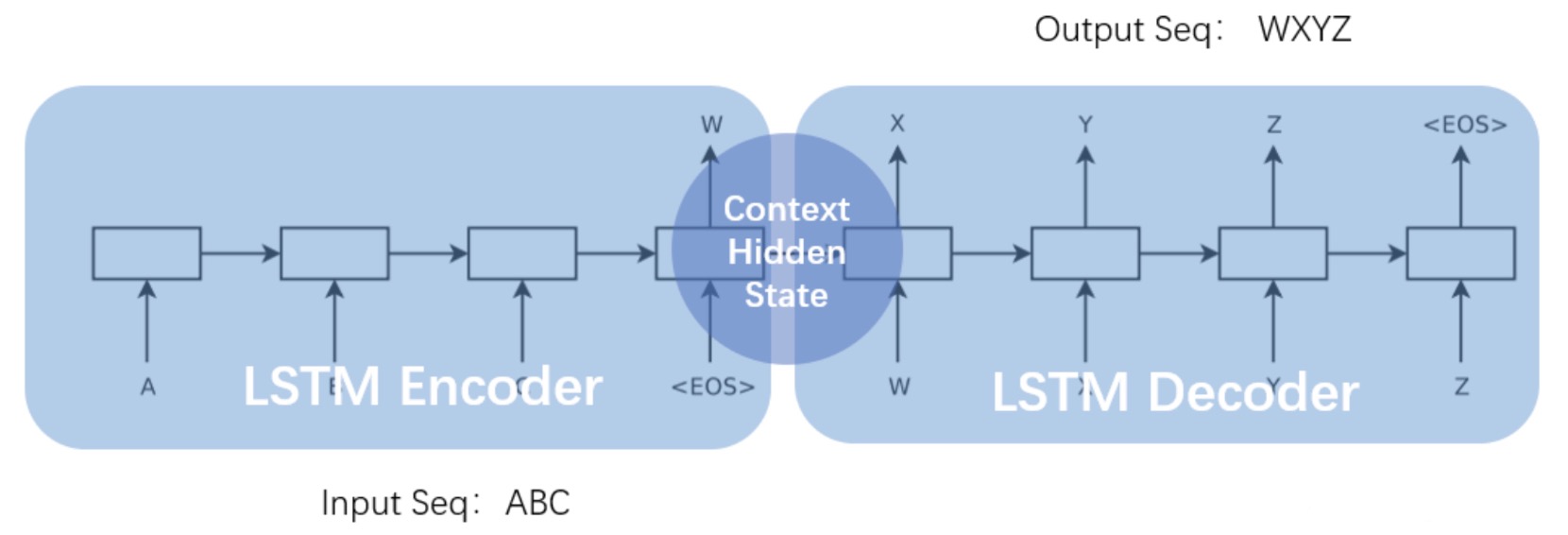
数学上, 可以将编码-解码的流程视为:
给定输入
\[X = < x_1, \cdots, x_m>\]目标输出 $Y$ 记为
\[Y = <y_1, \cdots, y_n>\]则编码器将输入通过非线性变换转化为上下文向量 $C$:
\[C = \mathscr{F}(x_1, x_2, \cdots, x_m)\]而解码器则根据输入序列 $X$ 的中间表示 $C$ 以及 之前已经生成的历史信息 $<y_1, \cdots, y_{i-1}>$ 生成第 $i$ 时刻要得出的输出序列元素 $y_i$:
\[y_i = \mathscr{G}(C, y_1, \cdots, y_{i-1})\]换言之, 生成目标输出序列中每个元素的过程形式为:
\[y_1 = \mathscr{G}(C) \\ y_2 = \mathscr{G}(C, y_1) \\ y_3 = \mathscr{G}(C, y_1, y_2) \\ \cdots\]起源
被设计用于解决 Seq2Seq 任务, 以 编码器 - 固定长度上下文向量 - 解码器 为架构的神经网络模型存在 Encoding Bottleneck, Gradient Exploding/Vanishing 等致命缺点: 由于在编码过程中序列信息在每一步中都会被总结编码并作为下一状态编码器的输入.
对较长的时序信息而言, 序列中较早的信息更有可能在整个编码过程中被逐步丢失, 这也就是 长时依赖 问题. 为了解决该问题, 注意力机制由 Bahdanau 等人于 Neural Machine Translation by Jointly Learning to Align and Translate 中提出.
在上面的 Encoder-Decoder 模型中我们不难看出, 该架构在生成目标序列时, 无论生成什么元素, 都使用了 相同 的 输入隐表示 $C$. 这意味着, 无论解码器生成输出序列中的哪个元素, 输入序列中的元素对它的 影响力 都是等同的.
解释
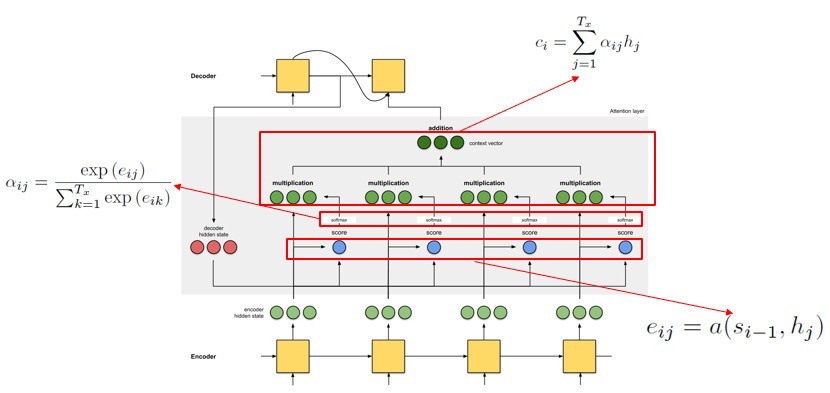
通过将编码器生成的中间表示 $C$ 替换为根据当前解码器生成元素 $y_i$ 而 不断变化 的可变 $C_i$, 就可以为 Encoder-C-Decoder 模型引入注意力机制. 也就是说, 生成目标序列中元素的过程可被表示为:
其中, 每个可变 $C_i$ 都表示输入序列中每个元素的 注意力分配概率分布.
在本篇论文中, $C_i$ 被定义为
\[C_i = \sum_{j=1}^{T_x}\alpha_{ij} \cdot h_j\]其本质是 输入序列中每个元素在RNN编码器对应模块的隐表示 和 每个输入元素关于输出序列的第 $i$ 个元素之间相关性概率值 的 加权和.
其中, $T_x$ 是输入序列中元素的数量 (也就是输入序列的长度), 对每个编号 $j \leqslant T_x \in \mathbb{N}$, $h_j$ 即为编码器中对应RNN块的 隐表示 (Hidden Representation).
而 $\alpha_{ij}$ 则为 输入序列 关于 输出序列 中第 $i$ 个元素的 注意力分配概率分布值, 计算方式为
\[\alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{k=1}^{T_x} \exp(e_{ik})}\]也就是通过 softmax 函数计算得来. 其中 $e_{i, k}$ 为 输入序列中第 $k$ 个元素和输出序列中第 $i$ 个元素之间的 相关性打分 (score), 评估它们之间的匹配性 (match).
在本论文中, 相关性打分形式化为
\[e_{ij} = a(s_{i-1}, h_j)\]以:
- 输入序列的第 $j$ 个元素关于编码器RNN模块的隐表示: $h_j$
- 解码器从输出序列的第 $i-1$ 位置的RNN模块所计算出来的, 给第 $i$ 位置处的RNN模块作为输入的一部分的隐表示: $s_{i-1}$
作为参数, 通过 对齐模型 (alignment model): $a()$ 计算得出.
在本论文中, 对齐模型被设计为一个简单的 前馈神经网络:
\[e_{i, j} = a(s_{i-1}, h_j) = v^{\intercal} \cdot \tanh(W \cdot s_{i-1} + U\cdot h_j)\]其中 $W \in \mathbb{R}^{n \times n}$, $U \in \mathbb{R}^{n \times 2n}$, $v \in \mathbb{R}^{n}$, 均为权重矩阵.
对齐模型的输入参数为: 输入和输出序列的隐表示层状态. 它和编码器, 解码器等模型的其余部分一同参与模型训练, 学习输入和输出序列之间的对齐关系 (注意力权重).
实现
参照 Seq2Seq Learning & Neural Machine Translation 基于 PyTorch 重新进行了实现, 下面进行简要解释;
首先进行数据处理. 给定的数据为用 \t 分列, 用 \n 换行的 txt 文件. 首先将 txt 文件按行读入, 然后对中文一列和英文一列分别进行预处理.
在预处理过程中, 将 Unicode 字符全部转换为 ASCII 字符, 并分别清除中文/英文列中的所有非中文/英文字符, 并对英文按单词, 对中文按汉字用空格分割.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
def unicode_to_ascii(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
def preprocess_eng(w):
w = unicode_to_ascii(w.lower().strip())
# creating a space between a word and the punctuation following it
# eg: "he is a boy." => "he is a boy ."
# Reference:- https://stackoverflow.com/questions/3645931/
# python-padding-punctuation-with-white-spaces-keeping-punctuation
w = re.sub(r"([?.!,])", r" \1 ", w)
# replace several spaces with one space
w = re.sub(r'[" "]+', " ", w)
# replacing everything with space except (a-z, A-Z, ".", "?", "!", ",")
w = re.sub(r"[^a-zA-Z?.!,]+", " ", w)
w = w.rstrip().strip()
# adding a start and an end token to the sentence
# so that the model know when to start and stop predicting.
w = '<start> ' + w + ' <end>'
return w
def preprocess_chinese(w):
w = unicode_to_ascii(w.lower().strip())
w = re.sub(r'[" "]+', "", w)
w = w.rstrip().strip()
w = " ".join(list(w)) # add the space between words
w = '<start> ' + w + ' <end>'
return w
# 1. Remove the accents
# 2. Clean the sentences
# 3. Return word pairs in the format: [ENGLISH, CHINESE]
def create_dataset(path, num_examples=None):
lines = open(path, encoding='UTF-8').read().strip().split('\n')
word_pairs = [[w for w in l.split('\t')] for l in lines[:num_examples]]
word_pairs = [[preprocess_eng(w[0]), preprocess_chinese(w[1])]
for w in word_pairs]
# return two tuple: one tuple includes all English sentenses, and
# another tuple includes all Chinese sentenses
return word_pairs
经过处理后的中英文本形式如下:
1
2
3
<start> if a person has not had a chance to acquire his target language by the time he s an adult , he s unlikely to be able to reach native speaker level in that language . <end>
<start> 如 果 一 個 人 在 成 人 前 沒 有 機 會 習 得 目 標 語 言 , 他 對 該 語 言 的 認 識 達 到 母 語 者 程 度 的 機 會 是 相 當 小 的 。 <end>
Size: 20289
随后对中文和英文训练数据分别进行 tokenize 和 padding 处理. 此处调用 tensorflow 内置的 tokenizer, 实际功能是对英文符号/中文汉字/句子起始和终止符从 $1$ 开始编号.
最后使用 tf.keras.preprocessing.sequence.pad_sequences 分别对中文列和英文列在每一行的后面填充 $0$, 直到所有中文/英文行的长度都达到最长的中文/英文句子长度.
然后加载数据集, 并返回索引化的中文和英文训练语料, 以及对应的中英文 tokenizer, 留作模型推理过程中备用.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
def max_length(tensor):
return max(len(t) for t in tensor)
def tokenize(lang):
# “lang”: a tuple of strings, in the string each token is separated using spaces
# 1. for each string in the tuple, separate all tokens
# 2. add "<start>", "<end>" as the 1st and 2nd token in the token dictionary
# 3. convert each sentence in the tuples into tensor arrays utilizing tokenizers
# 3. pad each sentence using "0" backwards for each sentence tensor array
lang_tokenizer = tf.keras.preprocessing.text.Tokenizer(
filters='')
# generate a dictionary, e.g. word -> index(of the dictionary)
lang_tokenizer.fit_on_texts(lang)
# output the vector sequences, e.g. [1, 7, 237, 3, 2]
tensor = lang_tokenizer.texts_to_sequences(lang)
# padding sentences to the same length
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor,
padding='post')
return tensor, lang_tokenizer
def load_dataset(path, num_examples=None):
# creating cleaned input, output pairs
# regard Chinese as source sentence, regard English as target sentence
targ_lang, inp_lang = zip(*create_dataset(path, num_examples))
print(type(inp_lang))
print(inp_lang[:5])
input_tensor, inp_lang_tokenizer = tokenize(inp_lang)
target_tensor, targ_lang_tokenizer = tokenize(targ_lang)
return input_tensor, target_tensor, inp_lang_tokenizer, targ_lang_tokenizer
随后构建数据集并声明相关变量:
1
2
3
4
5
6
7
8
9
10
11
12
BUFFER_SIZE = len(input_tensor_train)
BATCH_SIZE = 128
steps_per_epoch = len(input_tensor_train)//BATCH_SIZE
embedding_dim = 256
units = 1024
# 0 is a reserved index that won't be assigned to any word, so the size of vocabulary should add 1
vocab_inp_size = len(inp_lang.word_index) + 1
vocab_tar_size = len(targ_lang.word_index) + 1
dataset = tf.data.Dataset.from_tensor_slices(
(input_tensor_train, target_tensor_train)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)
此处的 unit 指 GRU unit 输出隐表示向量的维度.
然后分别定义 Encoder, BahdanauAttention 和 Decoder:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
from torch import nn
import torch.nn.functional as F
class Encoder(nn.Module):
def __init__(self, vocab_size, embedding_dim, enc_units, batch_sz):
super(Encoder, self).__init__()
self.batch_sz = batch_sz
self.enc_units = enc_units
self.embedding = nn.Embedding(
vocab_size,
embedding_dim
)
# pytorch use tanh as activation function for GRU units
# and initialize them using uniform distribution
self.gru = nn.GRU(
embedding_dim,
enc_units,
batch_first = True
)
def forward(self, x, hidden):
# x: training data with shape (batch_size, max_length) -> (128, 46)
# hidden: hidden states with shape (batch_size, units) -> (128, 1024)
# after embedding, the input batch's shape is converted into (batch_size, max_length, embedding_dim) -> (128, 46, 256)
x = self.embedding(x) # convert the input sentence into hidden representations
# Now perform computation through GRU units
# output contains the state(in GRU, the hidden state and the output are same) from all timestamps,
# output shape == (batch_size, max_length, units) -> (128, 46, 1024)
# state is the hidden state of the last timestamp, shape == (batch_size, units) -> (128, 1024)
output, state = self.gru(x, hidden)
return output, state
def initialize_hidden_state(self):
return torch.zeros((1, self.batch_sz, self.enc_units))
class BahdanauAttention(nn.Module):
def __init__(self, units):
super(BahdanauAttention, self).__init__()
self.W1 = nn.Linear(1024, units) # fully connected layer: 1024*units matrix; input_dim = 1024, output_dim = `units`
self.W2 = nn.Linear(1024, units) # fully connected layer: 1024*units matrix; input_dim = 1024, output_dim = `units`
self.V = nn.Linear(units, 1) # fully connected layer: input_dim = 1024, output_dim = 1
def forward(self, query, values):
# query shape: (1, batch_size, hidden_size) -> (1, 128, 1024)
# values shape: (batch size, sequence length, units) -> (128, 46, 1024)
# (values) hidden_with_time_axis shape: (batch_size, hidden_size)
query_with_time_axis = query.permute(1, 0, 2) # from [1, 128, 1024] to [128, 1, 1024]
# score shape: (batch_size, max_length, 1)
# acording to paper: v * tanh(W1*values + W2 * query)
# score: [10x1] * [128*10] => [128x46x1]
score = self.V(
# [128x46x10] + [128x1x10] (broadcast along 2nd dimension)
torch.tanh(self.W1(values) + self.W2(query_with_time_axis))
)
# score shape: (batch_size, max_length, 1)
# produced by the "alignment model"
attention_weights = F.softmax(score, dim=1) # [128x46x1]
# context_vector shape == (batch_size, max_length, hidden_size)
# perform weighted sum with computed attention weights with GRU units' hidden outputs
context_vector = attention_weights * values
context_vector = torch.sum(context_vector, dim=1) # [128x1024]
return context_vector, attention_weights
class Decoder(nn.Module):
def __init__(self, vocab_size, embedding_dim, dec_units, batch_sz):
super(Decoder, self).__init__()
self.batch_sz = batch_sz
self.dec_units = dec_units
self.embedding = nn.Embedding(
vocab_size,
embedding_dim
) # 6082x256
self.gru = nn.GRU(
embedding_dim + dec_units,
dec_units,
batch_first = True
)
self.fc = nn.Linear(dec_units, vocab_size)
self.attention = BahdanauAttention(dec_units)
def forward(self, x, hidden, enc_output):
context_vector, attention_weights = self.attention(hidden, enc_output)
x = self.embedding(x)
x = torch.cat(
tensors = (context_vector.unsqueeze(1), x),
dim = -1
)
output, state = self.gru(x, hidden)
output = output.view(
-1,
output.size(2)
)
x = self.fc(output)
return x, state, attention_weights
模型的训练, 推理和效果参见原 Tensorflow 实现.
注意力机制的一般化形式
下面我们将注意力机制从 Encoder-Decoder 框架中剥离, 并对齐进行进一步的抽象.
本质上, 注意力机制的计算可被视为:
\[\text{Attention}(\text{Query}, \text{Source}) = \sum_{i=1}^{L_x}\text{Similarity}(\text{Query}, \text{Key}_i) \cdot \text{Value}_i\]其中, $L_x$ 表示输入序列, 即 $\text{Source}$ 的长度. 由此可以将注意力机制视为:
- $\text{Source}$ 中的元素由一系列的 $\text{<Key, Value>}$ 键值对构成.
- $\text{Query}$ 是目标输出序列 $\text{Target}$ 中的某个元素.
- 给定 $\text{Query}$, 通过计算它和 $\text{Source}$ 中不同 $\text{Key}$ 之间的相似性/相关性, 就可以得到每个 $\text{Key}$ 的权重系数: $\text{Similarity(Query, Value)}$.
- 对每个 $\text{Key}$ 对应的 $\text{Value}$ 关于权重系数求和, 就得到了最终的
Attention值. (如果 $\text{Value}$ 是向量, 则最终得到的就是注意力向量)
在 Bahdanau 注意力机制中, 计算注意力向量的过程中 $\text{Source}$ 中的 $\text{Key}$ 和 $\text{Value}$ 本质是合二为一的, 也就是输入句子中每个单词对应的隐表示 (语义编码).
对注意力机制的抽象化理解
从抽象化的注意力机制计算流程来看, 我们可以用如下的两种方式理解注意力机制:
解释1: 信息聚焦
注意力机制被解释为: 从大量信息中选择性地筛选出少量重要信息, 并聚焦到这些信息上而忽略其余不重要信息的过程. 在这种解释中, “聚焦” 体现在对输出序列中不同的 Query 和输入序列中不同 Key 之间 权重的计算 上, 其大小代表了 Key 关于 Query 的重要性, 而和 Key 对应的 Value 就是信息本身.
解释2: 软寻址 (Soft Addressing)
注意力机制被解释为: 某种软寻址. 输入序列 Source 被视为 存储器中所存储的内容, 其元素均为 键值对: Key-Value.
而给定输出序列中某个位置 Query, 要计算它关于 Source 的注意力值 (注意力向量) 的过程就是对这个存储器执行 key = Query 的 查询 的过程, 查询目的就是从该存储器中 根据 Query 和存储的元素 Key 进行 相似性/相关性比较 进行 寻址 取出对应的数值, 也就是注意力值 (注意力向量).
我们称这种寻址为 软寻址, 因为它在寻址过程中会从 每个 Key 地址 取出内容, 计算它的重要性 (由它关于 Query 的相似性/相关性决定), 然后对每个 Key 对应的 Value 加权求和取出 最终的 Attention 值, 而非像常规寻址一样, 只从存储内容中找出一条.
Attention 值 (向量)的计算
在绝大部分注意力机制中, Attention 值 (向量) 的计算过程都可被抽象归纳为两个步骤:
- 根据输出序列中指定的位置
Query和 输入序列中的不同Key, 计算权重系数. - 根据第一步中所计算出的权重系数, 对输入序列中每个
Key对应的Value进行 加权求和.
进一步地, 第一步还可被细分为两个阶段: 计算 Query 和 Key 的原始相关性打分 和 对计算得出的原始分值归一化 (Normalize).
由此, 注意力机制中 Attention 值 (向量) 的计算流程可以被如下可视化:
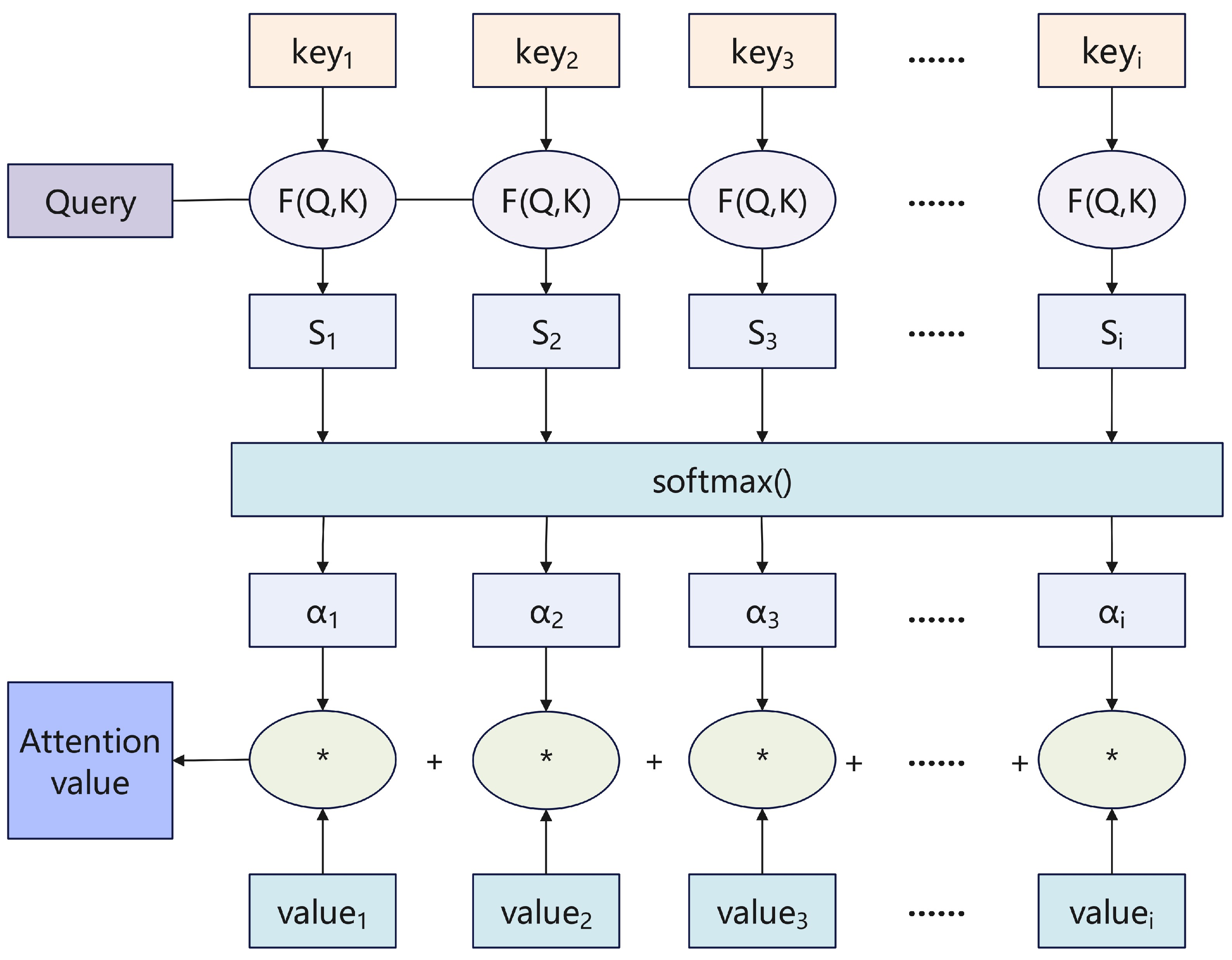
具体地, 在第 1.1 阶段, 也就是对 Query 和 Key 的原始相关性打分的计算中, 可以选择 求两者的向量点积 (如 Luong 注意力), 求两者的向量余弦相似度 或引入 前馈神经网络 (如 Bahdanau 注意力) 等方法.
在第 1.2 阶段, 可以通过简单的归一化 (Normalization) 将 1.1 阶段中计算得出的相关性打分整理为 所有元素权重和为 $1$ 的概率分布, 也可使用 SoftMax 将原始数值进行转换, 进一步突出重要元素的权重.
在第 2 阶段, 执行的操作就是简单的加权求和:
由此, 针对 Query 的注意力值 (向量) 得以求出.
注意力机制的各种变形
简单的 Scaled Dot-Product Attention
首先介绍一种结构较为简单且被广泛使用的 Attention 构造方式. 该构造又称 Scaled Dot-Product Attention. 我们用文本分类任务作为例子对其进行介绍:
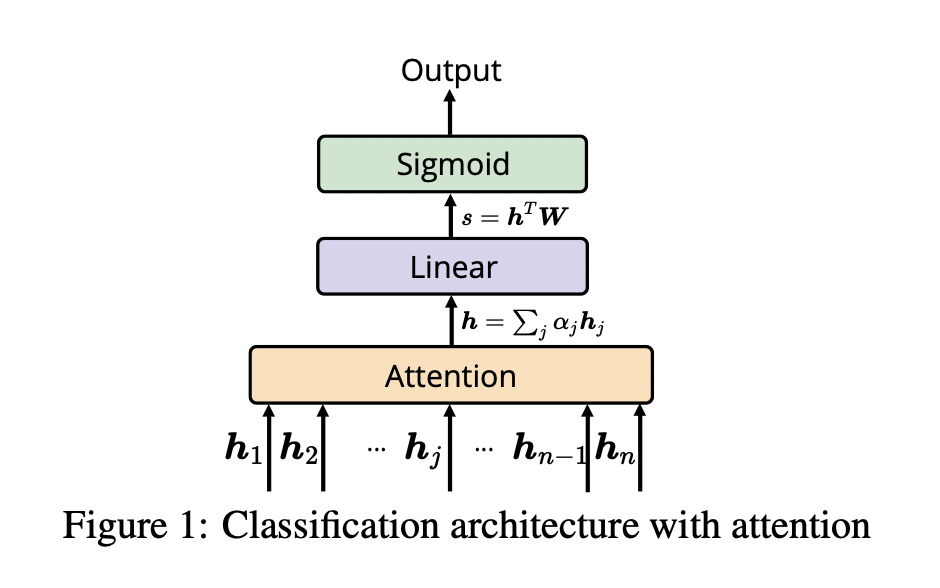
假设输入的文本长度为 $n$, 记为 $x = e_1, e_2, \cdots, e_n$. 则经过 RNN 编码后得到输入文本序列中每一步的 RNN 模块 hidden state (均为 $1 \times d$ 维的向量):
接下来将它们同时视为 Key 和 Value, 而对应输出序列每一步的查询向量用 $V \in \mathbb{R}^{d}$ 表示.
接下来使用 向量点积 作为打分函数. 即: 对任意给定的第 $i$ 个 Key, 其关于查询的分数 $\text{score}$ 为:
其中, $\lambda$ 为一个用于放缩点积结果, 让经过 SoftMax 后的所得权重更平滑的超参数, 一般设为 $\sqrt{d}$.
这种通过使用超参数 $\lambda$ 进行缩放的点积计算注意力权值的方式又称 缩放点积.
注意力权重 (Attention Weight) 由得到的打分通过 SoftMax 函数计算得来:
最后对 Value 关于对应的注意力权重做加权求和, 就得到了该 Query 的注意力值.
Self-Attention 中的注意力机制实现
Self-Attention 可视为 特征提取层, 给定输出 $I$, 得出经过特征融合后得到的输出 $O$. 此处我们只对其内部的注意力机制实现和注意力值 (向量) 计算方法进行介绍.
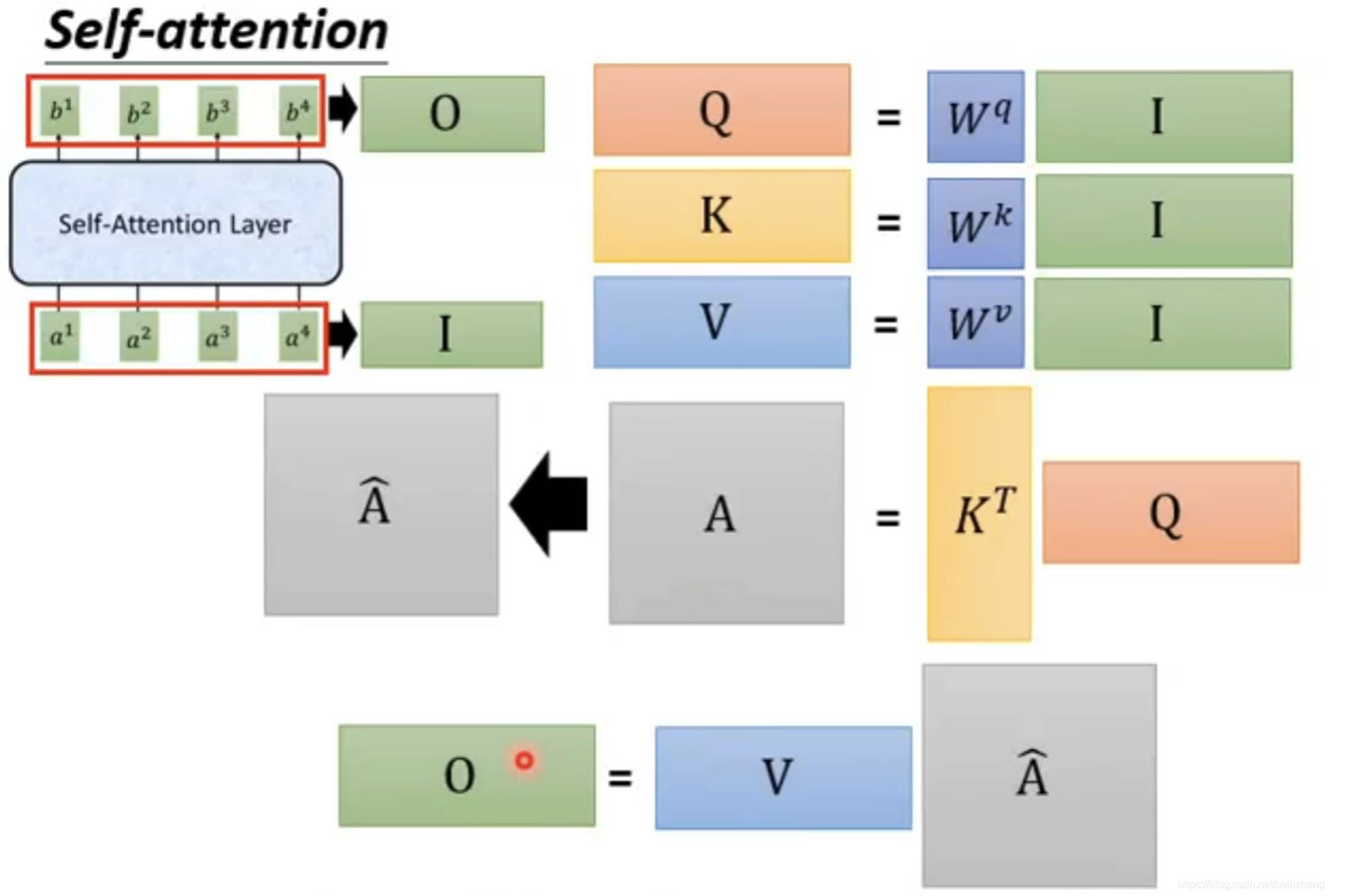
假设输入的 特征序列 长度为 $n$, 记为 $I = a_1, a_2, \cdots, a_n$. Self-Attention 中规定, 注意力机制概念中的 Query, Key 和 Value 分别由特征向量 $a_i$ 和三个 参数可学习 的全连接层 (可视为矩阵) $W^q, W^k, W^v$ 计算得到:
由此关于输入特征 $I$ 得到关于它自身的 Query, Key 和 Value 矩阵:
随后计算注意力值矩阵 $A$:
\[A = K^{\top} \cdot Q\]然后对 $A$ 通过 归一化 后得到 $\hat{A}$, 乘上 $V$, 计算得出最后的输出特征 $O$:
\[O = V \cdot \hat{A}\]简单的 PyTorch 实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, embed_dim):
super(SelfAttention, self).__init__()
self.query = nn.Linear(embed_dim, embed_dim)
self.key = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
q = self.query(x)
k = self.key(x)
v = self.value(x)
attn_weights = torch.matmul(q, k.transpose(1, 2))
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
attended_values = torch.matmul(attn_weights, v)
return attended_values
class SelfAttentionClassifier(nn.Module):
def __init__(self, embed_dim, hidden_dim, num_classes):
super(SelfAttentionClassifier, self).__init__()
self.attention = SelfAttention(embed_dim)
self.fc1 = nn.Linear(embed_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, num_classes)
def forward(self, x):
attended_values = self.attention(x)
x = attended_values.mean(dim=1)
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
注意力机制的应用
下面, 我们对注意力机制的应用进行简要讨论.
自注意力机制 Self-Attention
自注意力机制 (Self-Attention) 首先在2017年的经典论文 Attention is All you need 中被提出, 其核心思想为: 在处理序列数据时, 使用注意力机制计算输入序列中每个元素与 同一个序列 中其他元素之间的关系. Self-Attention 可视为 特征提取层, 给定输出 $I$, 得出经过特征融合后得到的输出 $O$.
由此, 自注意力机制得以解决 神经网络对多个相关的输入之间无法建立起相关性 的问题. 作为注意力机制的变体, 自注意力机制中的 $Q, K, V$ 均 来源相同, 因此自注意力机制中的 Q, K, V 计算方式也和常规的注意力机制有很大不同.
自注意力机制中 Attention Mechanism 的实现方式, 计算方法和原理参见本文章节: “注意力机制的一般化形式-注意力机制的各种变形-Self-Attention 中的注意力机制实现”.
自注意力机制的功能是筛选出重要信息而将相对不那么重要的信息过滤. 在 CV 领域应用时, 由于自注意力机制无法充分利用图像的尺度和平移不变性, 以及图像的特征局部性等先验知识, 因此需要通过大量数据学习它们, 由此导致自注意力机制对有效信息的提取能力要 比卷积神经网络更差, 只有在 训练数据规模较大 的前提下才能有效地建立准确的全局关系.
此外, 自注意力机制 并不保留输入序列中向量之间的位置关系. 在 NLP 领域应用中, 由于单词/文字在句中的位置会导致词语具有不同的性质, 因此需要引入 位置编码 (Positional Encoding) 进行信息的补齐: 对每个输入向量加上位置向量, 一并带入自注意力层进行计算.
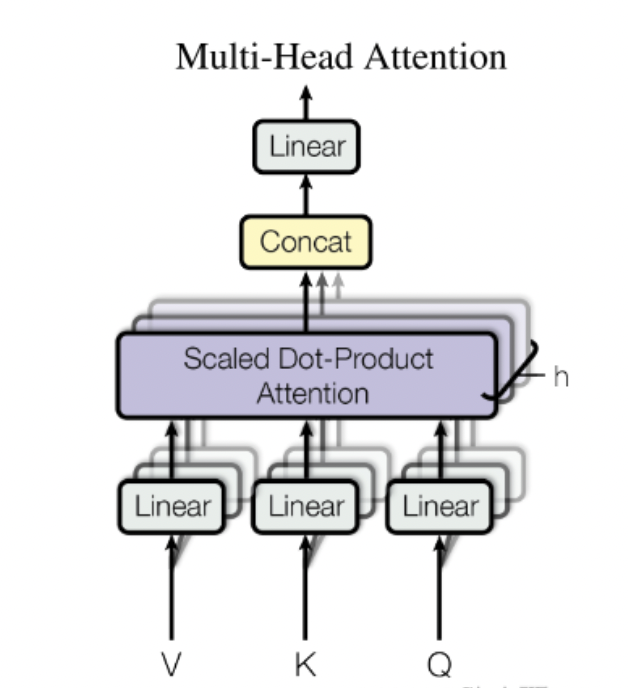
多头自注意力机制 Multi-Head Self Attention
Self-Attention 中实现的注意力机制中, 参数可学习 的全连接层 (可视为矩阵) 为: $W^q, W^k, W^v$.
每个输入特征向量 $a_i$ 分别和这三个矩阵相乘得到对应的 $q^i, k^i, v^i$ 参与后续注意力权值和输出特征 $O$ 的计算.
由于只有 一组 可学习的, 参与计算注意力权值的矩阵 $W^q, W^k, W^v$, 这样的注意力机制又称 单头自注意力机制. 为了更好的并行计算捕获更多维度的信息, 包括 多组 可学习的, 参与计算注意力权值的矩阵 的注意力机制算法被提出, 这就是所谓的 多头自注意力机制.
在实践中, 我们希望在给定相同的查询, 键值对的集合时, 模型能够基于 相同的注意力机制 学习到不同的相关关系. 随后, 通过将这些 独立 学习得到的信息组合起来, 从而得以捕捉到序列内各种范围的依赖关系.
由此, 我们使用 独立学习 得到的多组不同的注意力权值计算矩阵 W^q, W^k, W^v 变换给定的查询和键值对, 将这些独立学习得到的信息提取输出相 拼接, 通过另一个可学习的线性投影 (Linear Projection) 进行变换, 产生最终输出.
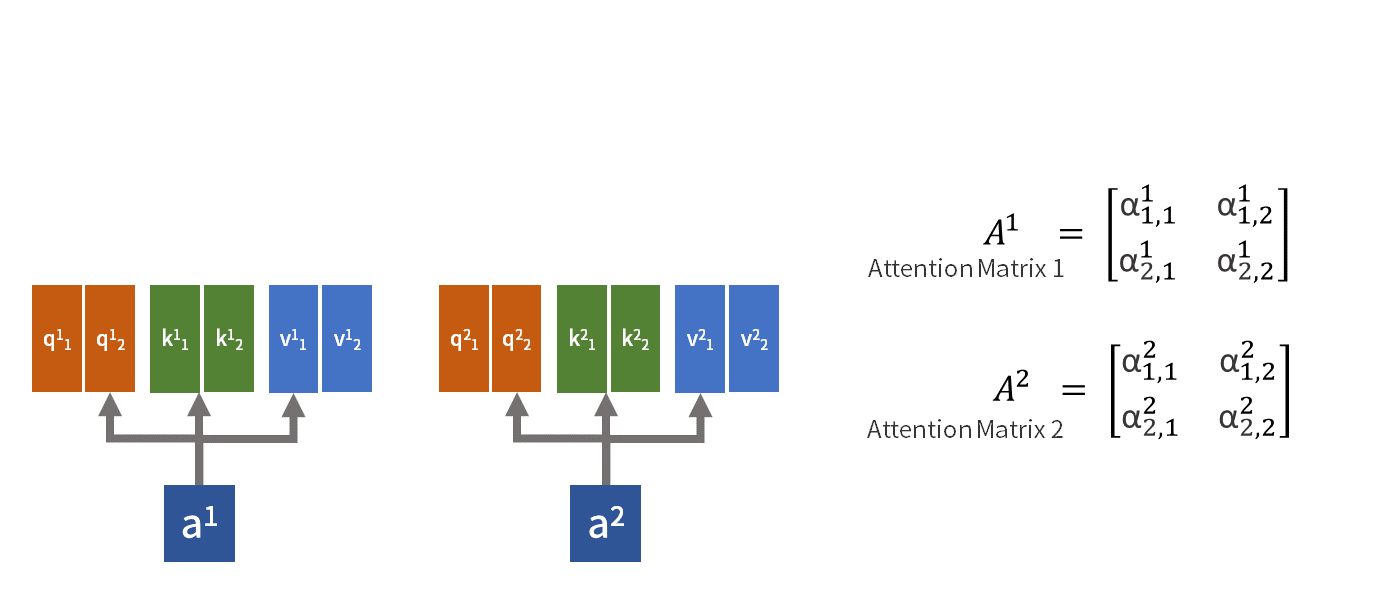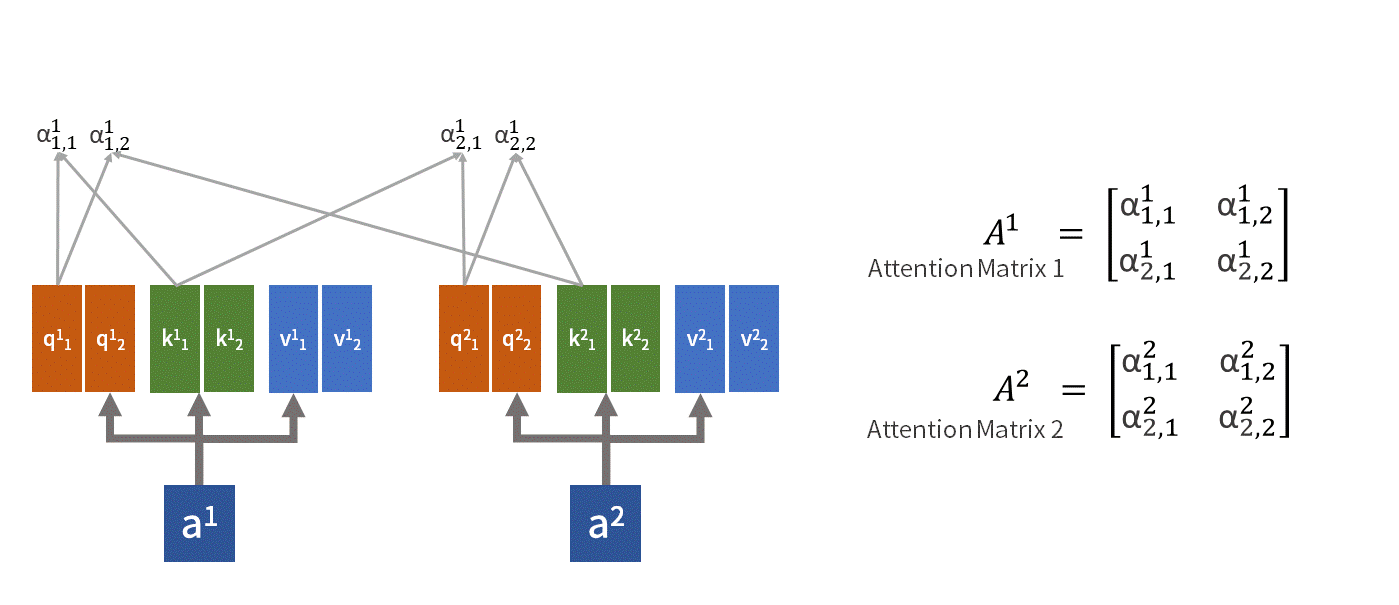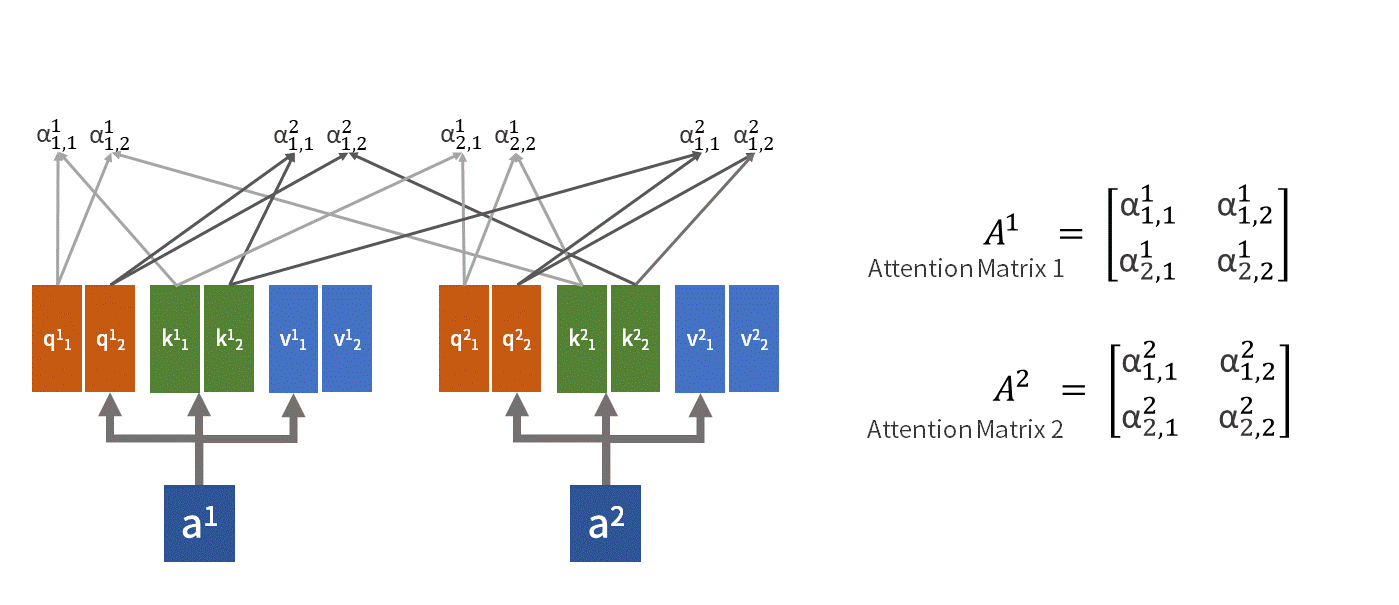
上图的例子中描述的就是一个包含了两组可学习矩阵的 双头自注意力机制.
多头自注意力机制的实现
首先定义注意力机制的头数, 以及输入特征维度. hidden_size 为 $q^i, k^i, v^i$ 的总维度.
1
2
3
self.num_attention_heads = num_attention_heads
self.attention_head_size = int(hidden_size / num_attention_heads)
self.all_head_size = hidden_size
其次定义 $W^q, W^k, W^v$:
1
2
3
self.key_layer = nn.Linear(input_size, hidden_size)
self.query_layer = nn.Linear(input_size, hidden_size)
self.value_layer = nn.Linear(input_size, hidden_size)
随后使用输入特征 $x$ 和 $W^q, W^k, W^v$ 相乘得到 Query, Key 和 Value 矩阵, 维度为 (batch_size, seq_length, hidden_size):
1
2
3
key = self.key_layer(x)
query = self.query_layer(x)
value = self.value_layer(x)
计算后需要将 seq_length 和 num_attention_heads 维度对换, 让最终得到的 $Q, K, V$ 张量维度为 (batch_size, num_attention_heads, seq_length, attention_head_size):
1
2
3
4
5
6
7
def trans_to_multiple_heads(self, x):
new_size = x.size()[ : -1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_size)
return x.permute(0, 2, 1, 3)
key_heads = self.trans_to_multiple_heads(key)
query_heads = self.trans_to_multiple_heads(query)
value_heads = self.trans_to_multiple_heads(value)
然后进行计算: $\frac{Q \cdot K}{\sqrt{\text{attention_head_size}}}$:
1
2
3
4
5
attention_scores = torch.matmul(query_heads, key_heads.permute(0, 1, 3, 2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
# perform normalization
attention_probs = F.softmax(attention_scores, dim = -1)
然后将得到的注意力矩阵和 Value 矩阵 $V$ 相乘得到输出特征, 维度为 (batch_size, num_attention_heads, seq_length, attention_head_size):
1
context = torch.matmul(attention_probs, value_heads)
最后将各个头得到的输出特征进行拼接:
1
2
3
4
5
6
# “contiguous()” is crucial to store tensor into a consecutive memory space
# to prevent errors happen when performing .view() operation
# REF: https://blog.csdn.net/kdongyi/article/details/108180250
context = context.permute(0, 2, 1, 3).contiguous()
new_size = context.size()[ : -2] + (self.all_head_size , )
context = context.view(*new_size)
与RNN的结合
参考本文章节: “Bahdanau 注意力机制-实现”.
Transformer
Transformer 是 Google 在 Attention is all you need 中提出的一种 完全基于注意力机制 的新模型结构. 传统的 Seq2Seq 模型基于结构复杂的 CNN 或 RNN, 一般由编码器和解码器两部分组成, 但这样的模型难以并行计算和训练, 且输入序列中较早的信息容易丢失. Transformer 架构完全摒弃了传统 Seq2Seq 模型架构中的 RNN 结构, 具有并行度高, 训练时间短等显著优势.
和使用 CNN 代替 RNN 的 Seq2Seq 模型相比, 由于卷积神经网络实际上可以视为 特殊的 Attention (卷积神经网络中的感受野大小固定, Attention 机制的感受野是动态计算得出的), 因此引入自注意力机制就避免了卷积神经网络需要多次卷积才能结合距离较远的数据, 在长时序信息的特征提取上表现不佳的问题.
下面介绍 Transformer 模型的架构:
解释
大多数表现优秀的 Seq2Seq 模型都包括 Encoder 和 Decoder 两部分: 前者将输入
映射为一个连续 表示的序列
\[z = z_1, z_2, \cdots, z_n.\]给定从编码器得出的输出 $z$, 解码器以 自回归 (Auto-regressive) 的方式 一个一个地 生成输出序列
其中 自回归, 是指在生成下一个字符 $y_i$ 时, 总是将 先前生成的符号 $y_{i-1}$ 作为解码器的附加输入的生成方式.
Transformer 的基础结构仍然包括编码器 (Encoder) 和解码器 (Decoder) 两部分. 编码器和解码器均由三类网络结构组成: 多头自注意力层, 前馈神经网络 (全连接层) 和 LayerNorm 层.
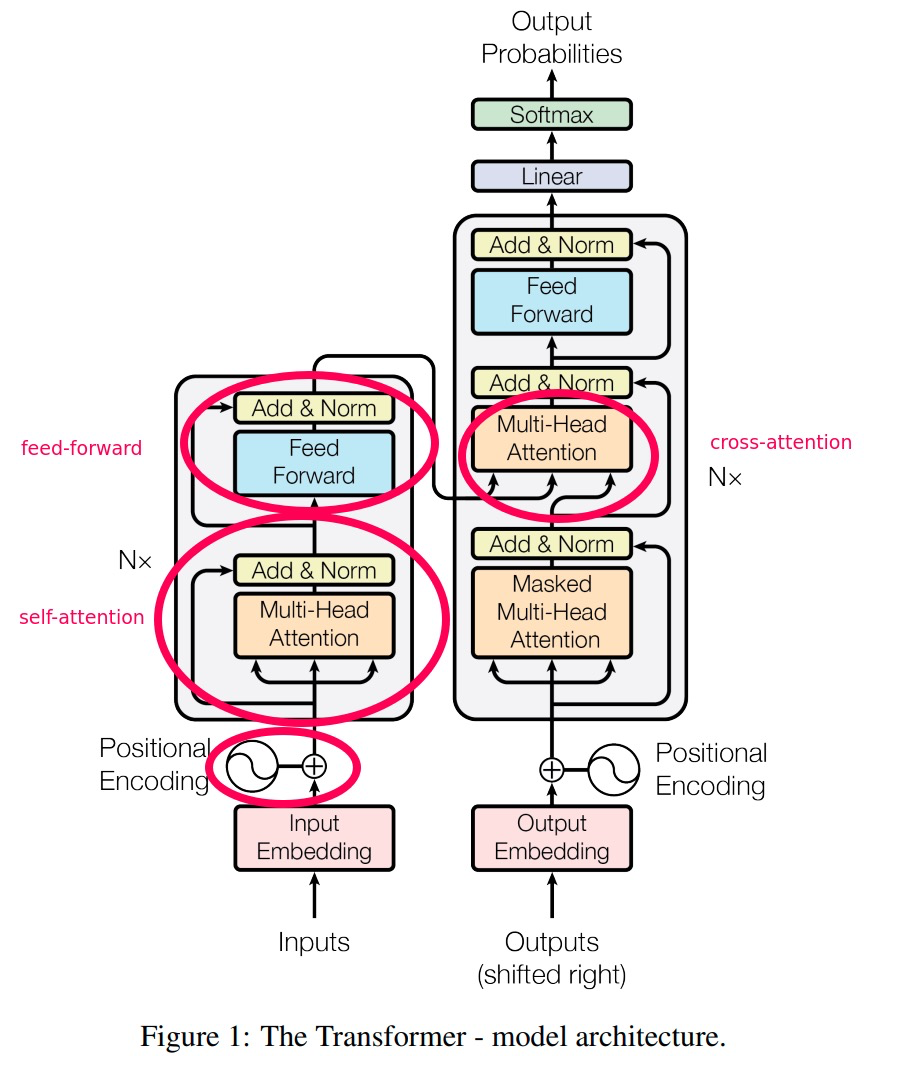
上图中左侧和右侧部分分别对应了 Transformer 模块中的编码器和解码器. 我们已经知道 多头自注意力层 和 全连接层 分别起到了信息提取和作线性变换, 对多维度信息进行混合的作用. 下面解释 LayerNorm 层的功能:
和 Batch Normalization 相似, Layer Normalization 作为 归一化层, 处理的对象不是如 Batch Normalization 一样对输入的一批样本 的 同一维度特征 作归一化, 而是对 单个样本 的 所有维度特征 作归一化. Transformer 架构中不适用 Batch Normalization 的主要原因是: 成批输入的样本 batch 中序列长度 可能不一致, 而若要对这批样本进行归一化就需要补齐长短不一的输入样本.
使用 $0$ 等空数据补齐样本, 将使较短序列中实际包含信息的向量规模相对减小而较长序列中实际包含信息的向量规模相对增大, 导致误差抖动增加, 无法起到稳定输入分布的效果.
上图中展示的是构成 Transformer 中编码器和解码器的 基本层 (layer):
-
Transformer的编码器由 $N=6$ 个 编码器基本层 串行堆叠构成, 每个编码器基本层中都包括两个主要部分: 作特征提取的 多头自注意力机制层 和起信息混合作用的 全连接层.为了确保经过特征提取和信息混合后神经网络获取的信息至少不会比什么也不做要差, 这两个子层后都如同
ResNet一样采用了 残差连接, 也就是说每个子层Sublayer()的输出都是LayerNorm(x + Sublayer(x)).为方便残差连接的拼接, 模型中所有子层和
embedding层的输出维度都是 $512$ 维.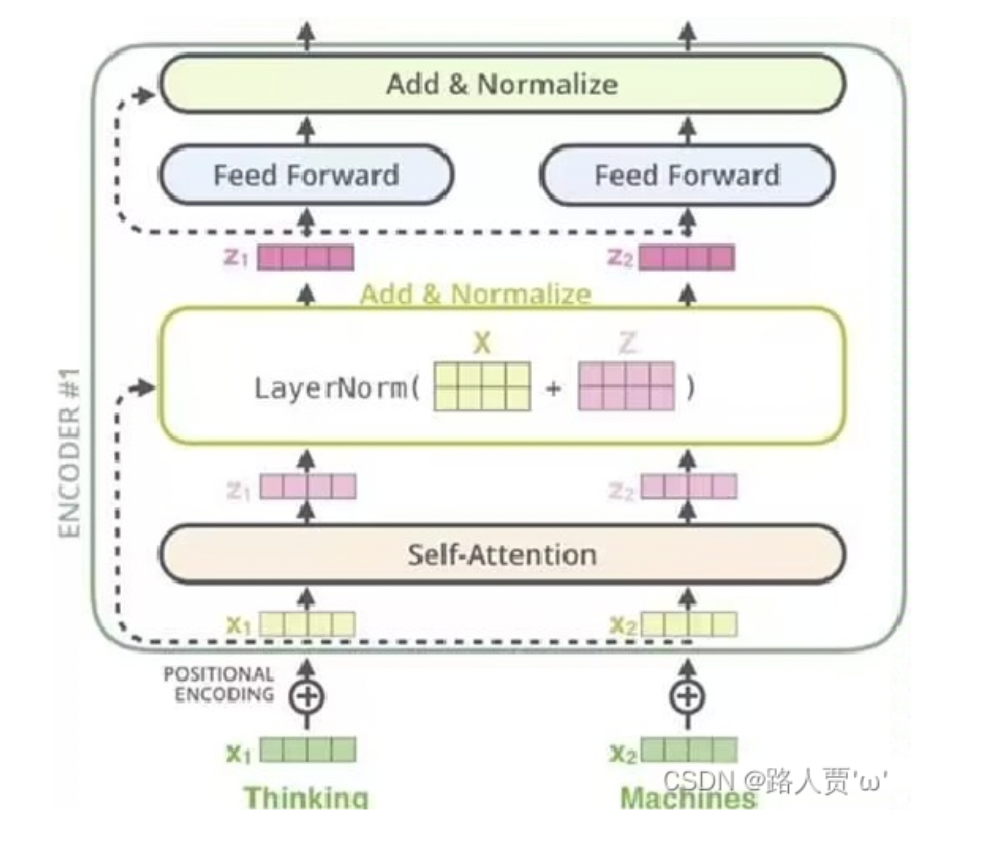
-
解码器同样由 $N=6$ 个 解码器基本层 串行堆叠构成. 每个解码器基本层中除了多头自注意力机制层和全连接层以外, 还额外加入了 对编码器的输出进行多头自注意力机制操作 的中间层. 基于解码器需要执行自回归预测任务的特点, 它对输入的多头自注意力层还被添加了 掩膜 (
Mask), 在训练时, 掩膜会阻止注意力层中第 $i$ 个位置的预测接触到任何序列后面的已知输出, 防止 “作弊”.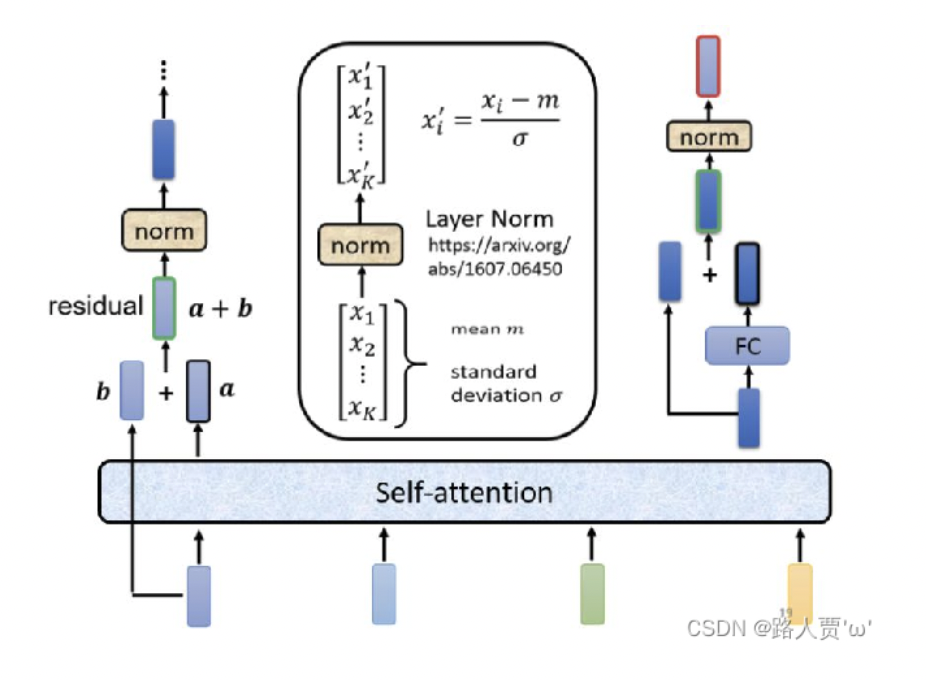
自注意力机制 和 多头自注意力机制 在上文中已有详细解释, 故此处不再赘述. 需要关注的是, 多头 (自) 注意力机制在 Transformer 中有三种不同的应用:
- 在编码器基本层中使用了 多头自注意力机制 层.
- 解码器基本层中, 三个子层里的第一层为 加入了掩膜的多头自注意力机制层 (
Masked Multi-Head Attention). - 解码器基本层中, 三个子层里的第二层为 关于掩膜多头自注意力机制层的输出 和 编码器层输出 的 多头注意力机制. 其中, $Q$ 由 掩膜多头自注意力机制层的输出 提供, 而 $K$ 和 $V$ 来源于 编码器层输出.
Transformer 架构中引入了 Embedding 词向量层对输入和输出字符向量化, 并使用线性变换和 Softmax 函数将解码器的输出转换为字典中每一个字符是预测的下一个字符的概率.
Transformer 架构完全基于注意力机制而不包含 RNN 或 CNN, 对序列输入中数据的相对位置排布不敏感: 由于注意力机制的输出为 $V$ 的加权和, 而权重仅为 $Q$ 关于 $K$ 的相似度, 相似度又与位置信息无关, 只和语义信息有关, 因此一个序列被打乱后作为输入经过注意力机制层, 输出的结果是和不打乱一致的.
为了规避注意力机制 不保留序列中数据的顺序信息 的问题, 作者设计了 位置编码 (Positonal Encoding) 来编码需俩中关于字符的相对或绝对位置信息.
位置编码被添加到编码器和解码器 (完整的编码器/解码器) 的输入向量 (Embedding) 中. 位置编码的维度被设计为和输入向量的维度相同, 使得它们可以被简单 相加 后传入编码器或解码器. 作者选择使用 不同频率的正弦/余弦函数 作为位置编码: 位置编码的每个维度都唯一地对应一个正弦曲线:
实现
下面展示 PyTorch 中预实现的 Transformer 层的调用:
1
2
3
4
5
6
7
8
9
10
11
12
import torch
import torch.nn as nn
transformer_layer = nn.TransformerEncoderLayer(
d_model = 32, # input dimension
nhead = 8, # number of attention heads in multi-head self-attention layers
batch_first = True
)
x = torch.rand(2, 16, 32)
output = transformer_layer(x)
print(output.shape) # torch.Size([2, 16, 32])
Transformer的应用
接下来, 我们简述一些 Transformer 架构的应用.
Vision Transformer
通过上文的描述我们已经知道, Transformer 是一种端到端的, 解决 NLP 任务的模型架构, 采用多头自注意力机制使得模型能够并行化地快速训练并获得对全局信息的提取能力. 通常, Transformer 需要在大型文本语料库中进行 预训练, 然后在垂直领域进行微调从而在特定任务上达到更好的性能.
Vision Transformer 是 Transformer 模型架构在计算机视觉领域中的变体, 在尽可能避免对原有模型架构的改动的前提下, 成功的将其迁移至了计算机视觉领域, 证明了 Transformer 架构在图形领域同样具有取代传统的 CNN 架构用于图像分类和检测任务的能力.
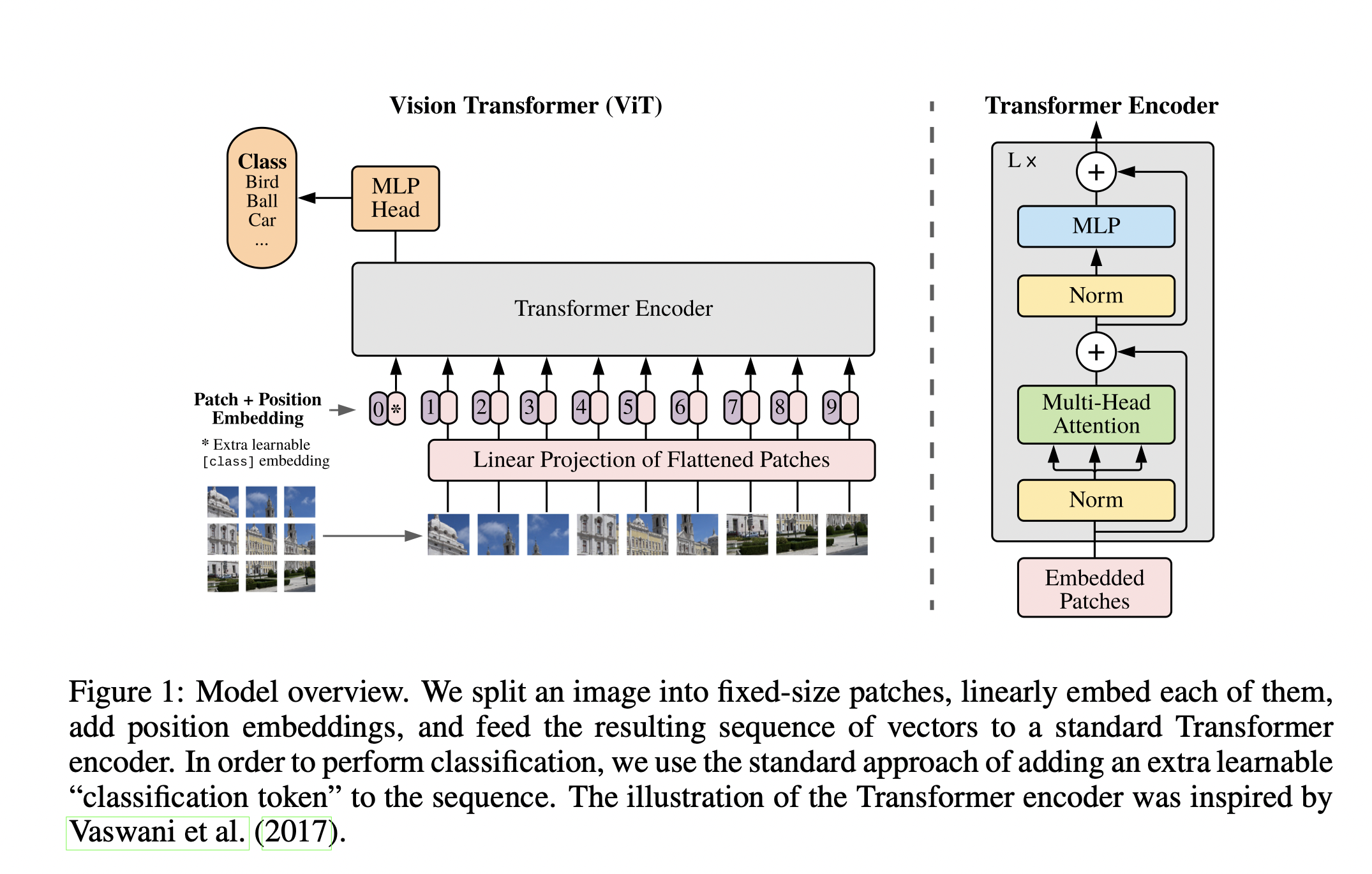
作者将图片拆分为不重叠且大小固定的 patch 序列, 经过向量化后作为 线性序列 输入传入 Transformer 中, 类比 NLP 领域中的词组序列输入.
论文中设计的 Vision Trasformer 图片分类器执行的操作基本如下:
- 将图片分割为大小相同 (如 $16 \times 16$) 且不重叠的
Patches, 然后将每个Patch展开为 一维向量. - 一般地, 由于展开后的
Patch维度较大, 还需通过线性投影层对Patch做进一步的Token化, 进行维度压缩和特征变换得到Patch Embeddings. - 在所得的
Patch Embeddings前加入作者额外引入的 可学习的Class Token, 方便后续分类. - 在加入了
Class Token的Patch Embeddings后面再加上 位置编码 (Position Embedding), 然后将其作为多个 串行 的Transformer Encoders中进行 全局注意力计算和特征提取:Transformer Encoder中的多头自注意力模块负责提取Patch内或Patch序列之间的特征, 在多头自注意力模块后的全连接层模块负责对所提取的特征进行线性变换. - 提取出串行的
Transformer Encoders中最后一个的输出序列中对应Class Token的部分, 以其作为编码器串最终的信息提取结果, 传入作为分类器的全连接层 (MLP) 中, 得出最终的分类结果.
预训练语言模型
预训练语言模型是 Transformer 架构的重要应用之一. 预训练语言模型通过使用大量的语料数据对模型进行 无监督或弱监督学习 (Unsupervised or Weak-supervised), 使参数规模庞大的语言模型具备句法, 语法规律等足够多的语言知识. 然后在下游任务中再对模型进行相应的 finetune.
注:
监督学习基于成对的 输入-输出 数据, 学习目标是让模型能够正确拟合输入和输出之间的映射关系. 监督学习需要经过标注的训练数据, 有明确的模型训练目标, 并通过 目标函数 判断模型训练的效果.
无监督学习基于 未标注 的数据, 没有明确的学习目标, 依赖模型自身对训练数据的内在结构和关系进行挖掘. 无监督学习不依赖经过标注的训练数据, 没有明确的模型训练目标, 难以评估模型训练的效果.
半监督学习介于监督学习和无监督学习, 使用 大量的未标注数据 和 少量的标注数据 对模型进行训练, 目的是在有限的标注数据引导下最大程度地利用未标注数据提高模型的泛化能力.
在语言模型的无监督预训练目标中, 最为成功的是 自回归 和 自编码 语言建模. 在 Transformer 架构中, 其编码器和解码器就分别属于自编码和自回归模型.
因此, 预训练语言模型主要包括 自编码模型 (又称AE模型, Autoencoder Language Model) 和 自回归模型 (也称 AR模型, Autoregressive Language Model):
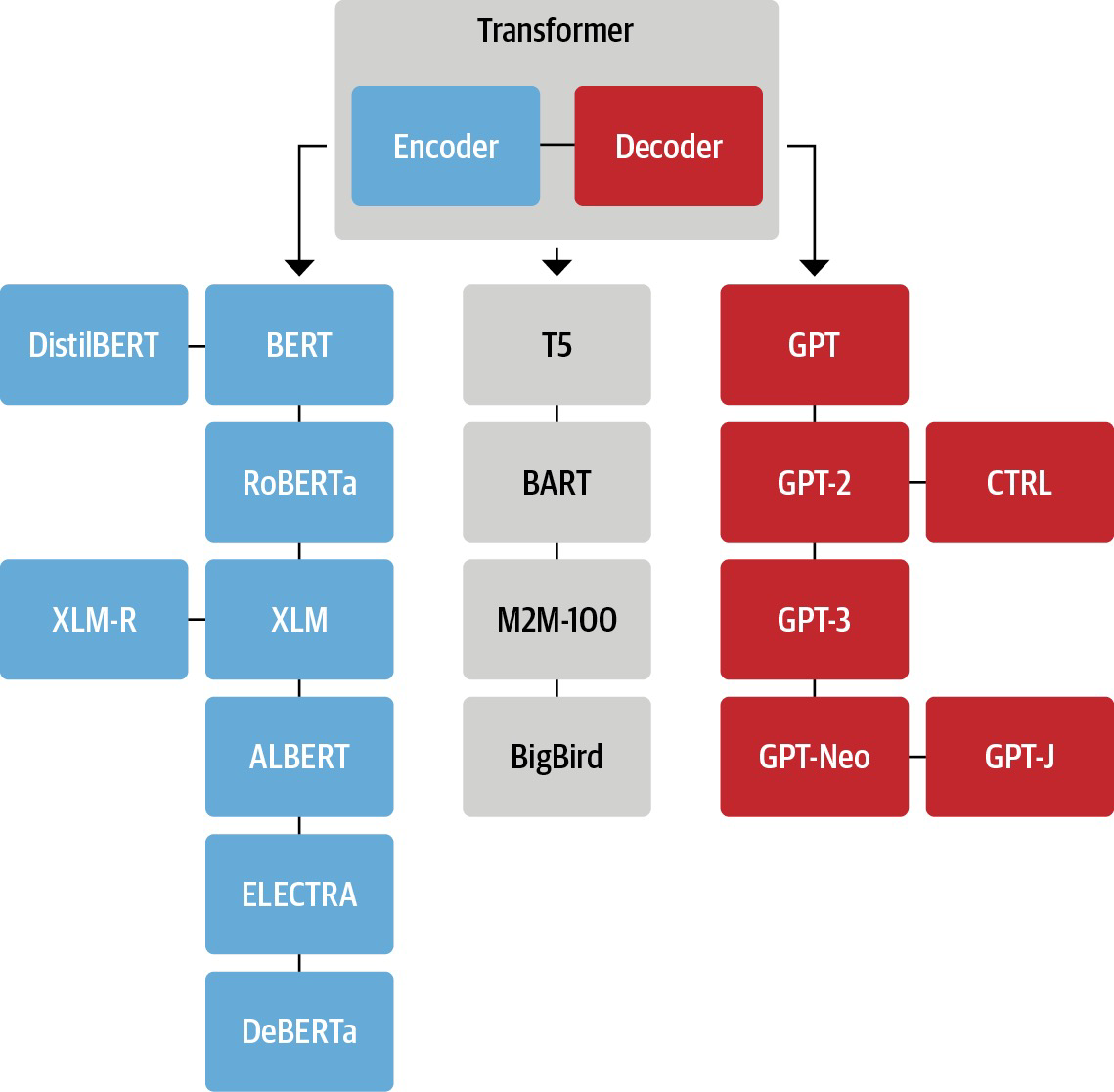
上图中左侧蓝色的模型均为 Transformer Encoder, 也就是自编码模型; 右侧红色的则为 Transformer Decoder, 即自回归模型. 中间的灰色模型为结合了 Transformer Encoder 和 Transformer Decoder 的 Seq2Seq 模型.
自编码语言模型
我们首先解释 自编码器 的概念. 自编码器 (Auto Encoder) 是用于学习 数据的有效特征表示 的神经网络, 由负责 将输入数据映射到低维特征空间 的编码器和 将低维特征映射回原始空间 的解码器组成.
自编码模型的主要代表是 Google 推出的 BERT. 它们的能力可以被简要的解释为 “做完形填空”: 从被掩膜部份掩盖的输入中, 预测被掩盖的部份, 重建原始数据.
BERT 及其变体, 包括 RoBERTa, ALBERT 等 AE 模型包含 双向 Transformer 结构, 能够生成包含语言理解的文本表示 (Text Representation), 擅长自然语言理解任务 (NLU, 即 Natural Language Understanding), 常被用于生成 句子的上下文表示 和 词/句子嵌入向量, 但 不能被直接用于文本生成.
自编码语言模型 (AE) 的优缺点总结如下:
优点: 自编码语言模型对序列中任意元素的表示可以 涵盖这个元素前后两方向的完整上下文, 擅长语言理解任务.
缺点:
- 自编码语言模型存在 输入噪声 的问题: 由于
BERT类模型在预训练过程中必须使用在下游finetune任务中永不会出现的掩膜符号[MASK]对输入进行遮盖, 因此会产生 预训练-微调差异, 而自回归语言模型由于不依赖被掩膜遮盖的输入训练, 因此不存在这种问题. BERT假设, 在给定unmasked tokens时, 所有待预测 (masked) 的tokens都是相互独立的, 而这一点是与事实不符的.
自回归语言模型
自回归语言模型 (AR 模型) 的代表为 GPT, 本质是 Transformer 架构中的解码器, 其学习模式为: 给定一系列按照时序排序的输入序列, 每一次给定一个输入, 预测下一个 timestep 的输出, 并将其输出作为预测下下个 timestep 的值时的输入. 自回归语言模型因其特性常用于 生成式任务, 如自然语言生成 (Natural Language Generation) 领域中的文本摘要, 文本翻译, 对话问答等一系列任务.
自回归模型利用文本的上下文, 通过估计训练学习到的文本语料库中文本的 概率分布, 对当前输入序列的下一个词进行预测:
给定文本序列
\[T = x_1, x_2, \cdots, x_{L_T}.\]则该文本序列的似然序列可以被分解为 前向连乘 (由前向后预测):
\[p(T) = \prod_{i=1}^{L_T} p(x_i \vert x_{<i})\]或者 后向连乘 (由后向前预测):
\[p(T) = \prod_{i={L_T}}^{1} p(x_i \vert x_{>i})\]由于 AR 模型仅能 单向编码, 因此它在对 双向上下文信息 进行建模时效果不佳.
自回归语言模型 (AR) 的优缺点总结如下:
优点: 擅长 NLG 任务, 训练目标较为简单: 预测语料库中的下一个 token, 训练数据方便取得.
缺点: 无法同时利用和建模双向的上下文信息, 无法完全捕捉文本中 tokens 的内在联系.
Encoder-Decoder 模型
Encoder-Decoder 模型同时使用编码和解码器, 将所有的下游任务视为 Seq2Seq 任务: 文本-文本, 文本-图像, 图像-文本, 文本-序列等.
BERT
BERT 是自编码模型的典型代表.
介绍
BERT 全称 Bidirectional Encoder Representation from Transformer, 中文译为 “来自 Transformer 的双向编码器表征”, 蕴含了它的数个特点: 架构源于 Transformer 中的编码器, 可通过编码生成文本的隐表示, 以及具有双向编码文本序列中上下文的能力.
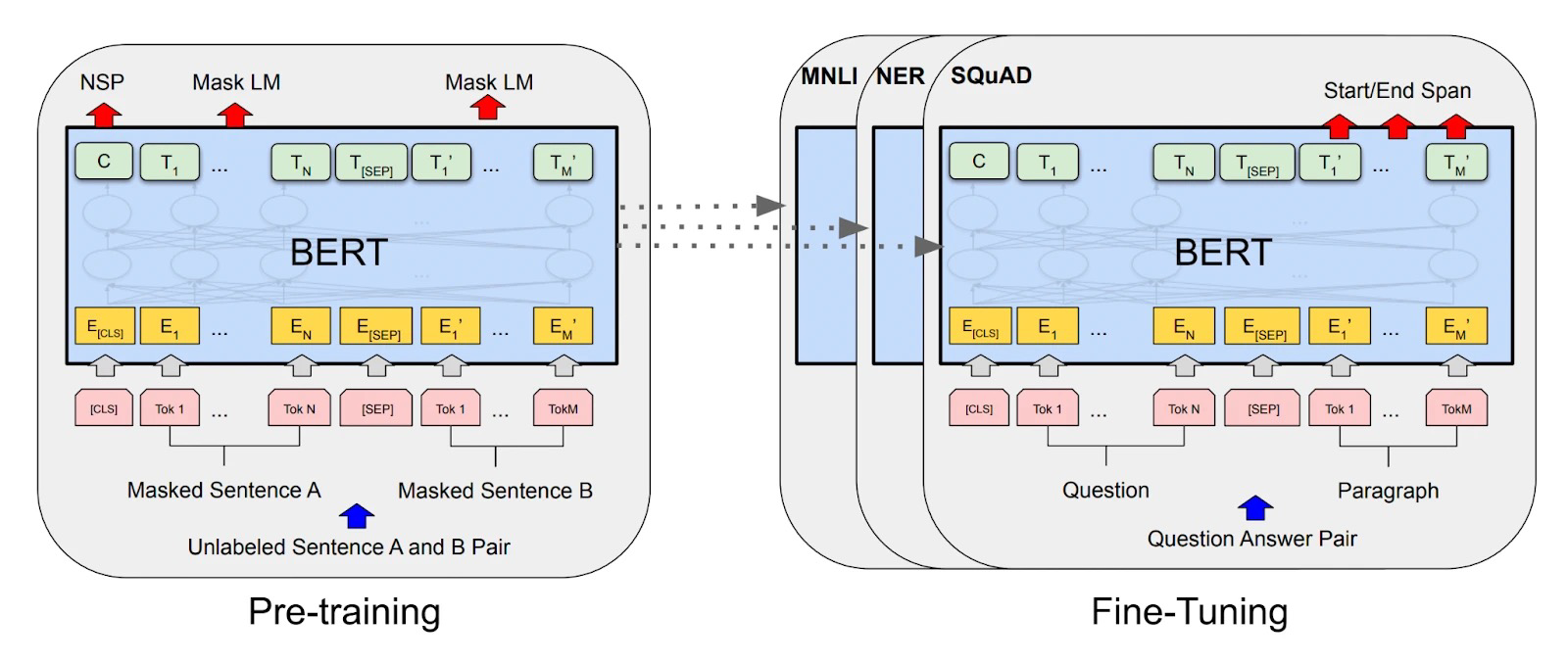
BERT 具有两个版本: base 和 large, 二者在堆叠的 多头自注意力机制层 的层数, 头数和隐藏层维度上有区别, 后者的参数总量约为前者的三倍.
作为 Transformer 架构中的编码器部分, BERT 的训练和应用同样遵循 预训练-下游任务微调 的模式. BERT 的模型训练目标包括 掩膜语言模型 (Masked Language Model) 和 下一结构预测 (Next Sentence Prediction). 下面对这两个训练目标进行简要介绍:
-
Masked Language ModelMasked Language Model训练目标就是要求模型掌握做 “完形填空” 的能力. 文本序列作为输入数据, 被随机使用掩膜 “[MASK]” 遮盖掉序列中约 $15\%$ 的单词, 对模型的优化目标是检查 模型能否通过剩下的上下文信息预测出被遮盖的单词原本应该是什么. 在该训练过程中, 上下文的语义信息被注意力机制层提取和学习, 并储存在模型参数中.由于在下游的实际
NLU任务中绝无可能出现掩膜[MASK], 因此在训练时需要使用下列的策略进行遮盖. 对每个被选定了要被遮盖的位置:- 有 $80%$ 的概率使用掩膜
[MASK]遮盖它, 作为 未知信息 赋予模型预测能力. - 有 $10\%$ 的概率用 随机采样 的单催替换它, 作为 噪声 赋予模型 自行纠错 的能力.
- 有 $10\%$ 的概率不做替换, 作为正确的信息.
由此, 强迫被训练的模型 不依赖当前的词而必须考虑其上下文 进行完形填空的预测, 获取全量全局的信息.
比如:
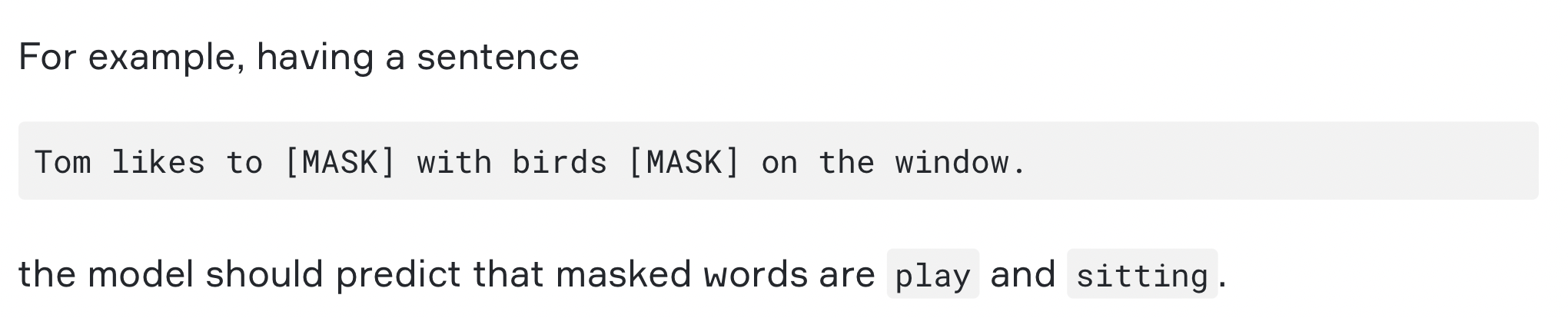
- 有 $80%$ 的概率使用掩膜
-
Next Sentence Prediction由于部分
NLU下游任务, 比如问答和推理均基于 给定的两个句子之间关系 的理解, 因此要让BERT具有解决这类任务的能力, 就需要设计训练目标增强模型对句子的 理解能力.因此, 在训练中, 将会有 $50\%$ 有关联的句子 (实际上是
Token序列) 对, 和 $50\%$ 无关的句子对进行训练, 让模型判断抽取的这对句子是否存在关联. 其输入形式为:1 2 3 4 5 6
# 输入用 [CLS] 作为开头, 句子之间用 [SEP] 进行隔断, 每个句子中要被掩盖的部份用掩膜 [MASK] 覆盖 Input = [CLS] the man went to [MASK] store [SEP]he bought a gallon [MASK] milk [SEP] Label = IsNext Input = [CLS] the man [MASK] to the store [SEP]penguin [MASK] are flight ##less birds[SEP] Label = NotNext
比如:

模型架构
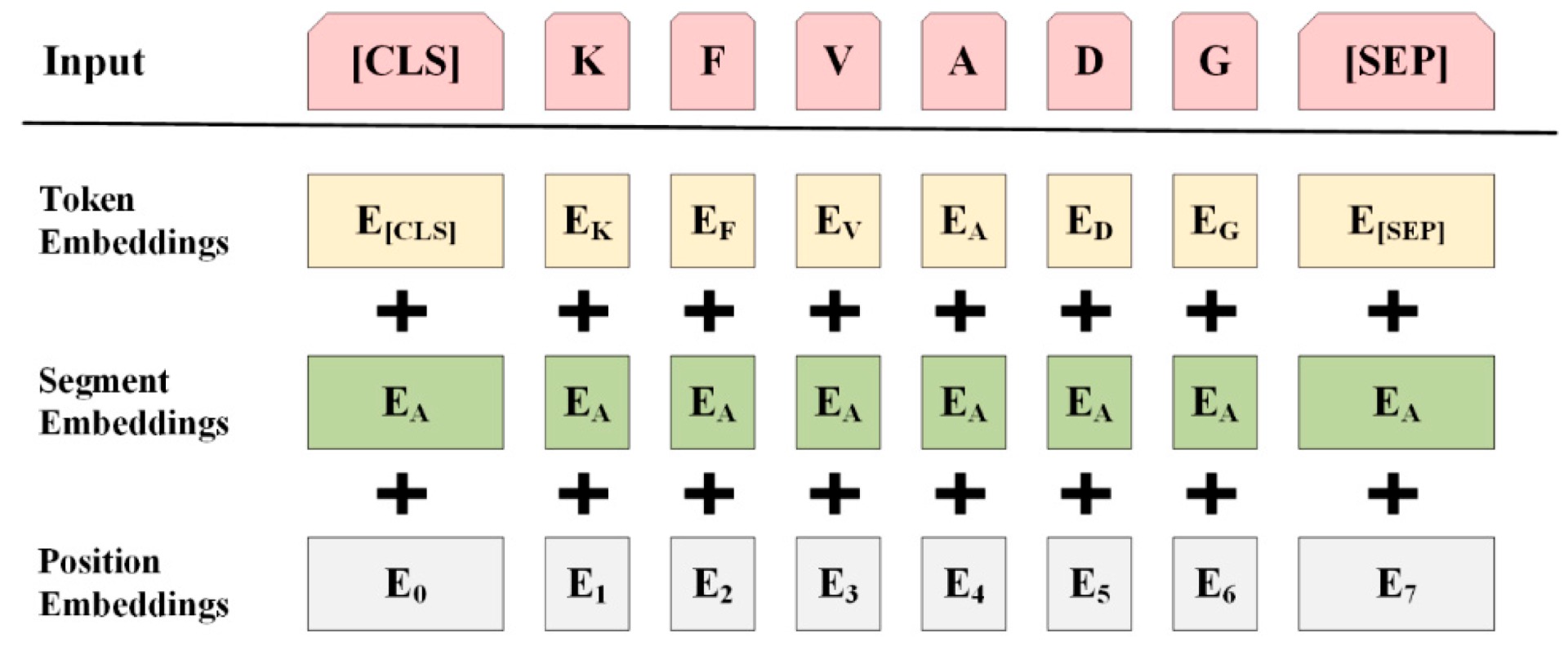
为了完成 BERT 的两个训练目标, 其输入需要经过较为复杂的处理流程:
- 将作为输入的句子进行分词, 加上开头指示符
[CLS]和 隔断符 (如果只有一个句子则不用)[SEP], 并用掩膜[MASK]基于上文描述的策略随机掩盖句子中的文本. - 将处理后的句子向量化, 得到
Token Embeddings - 额外计算句子中每个单词的
Positional Embeddings. - 为了让模型具备区分输入的不同句子的能力, 额外构造
Segment Embeddings: 上句的任何位置上Segment Token均为 $0$, 下句均为 $1$. - 将
Token Embeddings,Segment Embeddings和Position Embeddings三个向量累加 (Element-wise Addition), 得到最终传入模型的输入.
计算流程如下图所示:
实现
参考 , 下面简要介绍 BERT 模型的 PyTorch 实现, 数据预处理和模型训练.
Google 发布的 BERT 模型使用了 BooksCorpus 和 English Wikipedia 语料进行训练, 规模达到千万级别. 由于本实现仅为学习目的, 因此仅使用 IMDB 影评数据集进行训练, 数据集规模约为 $7200$ 词.
数据集可通过 Kaggle 上的相关页面 下载. 我们构建数据集类 IMDBBertDataset(), 并分别实现:
- 将数据集按照 句子 拆分.
- 基于拆分出的句子, 进一步将其拆分为单词, 并构建 单词表.
- 基于上文提及的规则, 为
NSP训练目标构建句子对, 以及对每个句子进行相应的掩膜掩盖 (Masking).
训练集构建部分的代码展示如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
import random
import typing
from collections import Counter
from pathlib import Path
import numpy as np
import pandas as pd
import torch
from tqdm import tqdm
from torch.utils.data import Dataset
from torchtext.vocab import vocab
from torchtext.data.utils import get_tokenizer
from typing import List
# select CUDA, CPU or MPS device accordingly
device = torch.device("cuda" if torch.cuda.is_available() else ("mps" if torch.backends.mps.is_available() else "cpu"))
class IMDBBertDataset(Dataset):
CLS = '[CLS]'
PAD = '[PAD]'
SEP = '[SEP]'
MASK = '[MASK]'
UNK = '[UNK]'
MASK_PERCENTAGE = 0.15 # according to original paper
MASKED_INDICES_COLUMN = 'masked_indices'
TARGET_COLUMN = 'indices'
NSP_TARGET_COLUMN = 'is_next' # Next Sentence Prediction
TOKEN_MASK_COLUMN = 'token_mask'
OPTIMAL_LENGTH_PERCENTILE = 70
def __init__(self, path: str, ds_from: int = None, ds_to: int = None, should_include_text: bool = False):
# in IMDB dataset, two columns exist: 'review' and 'sentiment'
self.ds: pd.Series = pd.read_csv(path)['review']
if ds_from is not None or ds_to is not None:
self.ds = self.ds[ds_from : ds_to]
self.tokenizer = get_tokenizer('basic_english')
self.counter = Counter()
self.vocab = None
self.optimal_sentence_length = None
self.should_include_text = should_include_text
# include textual representations for debug purposes on-demand
if should_include_text:
self.columns = ['masked_sentence', self.MASKED_INDICES_COLUMN, 'sentence', self.TARGET_COLUMN,
self.TOKEN_MASK_COLUMN,
self.NSP_TARGET_COLUMN]
else:
self.columns = [self.MASKED_INDICES_COLUMN, self.TARGET_COLUMN, self.TOKEN_MASK_COLUMN,
self.NSP_TARGET_COLUMN]
self.df = self.prepare_dataset()
# implement standard operational methods in torch.utils.data.Dataset class
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
# method for preparing a training-item tensors
item = self.df.iloc[idx]
inp = torch.Tensor(item[self.MASKED_INDICES_COLUMN]).long()
token_mask = torch.Tensor(item[self.TOKEN_MASK_COLUMN]).bool()
# restrict the model prediction on masked tokens (MLM Target)
mask_target = torch.Tensor(item[self.TARGET_COLUMN]).long()
# set all non-masked integers (tokens) in the target to 0
mask_target = mask_target.masked_fill_(token_mask, 0)
attention_mask = (inp == self.vocab[self.PAD]).unsqueeze(0)
# set the nsp target
# nsp is a binary classification problem, create nsp target as a tensor of two items
# train the model for NSP: use BCEWithLogitsLoss (Binary Cross Entropy Loss)
if item[self.NSP_TARGET_COLUMN] == 0:
t = [1, 0] # NOT next
else:
t = [0, 1] # IS next
nsp_target = torch.Tensor(t)
return (
inp.to(device),
attention_mask.to(device),
token_mask.to(device),
mask_target.to(device),
nsp_target.to(device)
)
def prepare_dataset(self) -> pd.DataFrame:
# prepare the dataset, steps:
# 1. split dataset on sentences
# 2. create a vocabulary for word-token pair: {<word> : <token>}
# 3. create training dataset:
# 3.1 add special tokens like '[SEP]' to the sentence
# 3.2 randomly mask 15% words with '[MASK]' in each sentences
# 3.3 pad sentences to predifined length
# 3.4 ccreate NSP items for sentence pairs
sentences, nsp, sentence_lens = [], [], []
# split the dataset on sentences
for review in self.ds:
# split sentences with commas
review_sentences = review.split('. ')
sentences += review_sentences
self._update_length(review_sentences, sentence_lens)
self.optimal_sentence_length = self._find_optimal_sentence_length(sentence_lens)
print("[INF] Creating vocabulary...")
for sentence in tqdm(sentences):
s = self.tokenizer(sentence)
self.counter.update(s)
self._fill_vocab()
print("[INF] Preprocessing dataset...")
for review in tqdm(self.ds):
review_sentences = review.split('. ')
if len(review_sentences) > 1:
# Produce true and false NSP item pairs
for i in range(len(review_sentences) - 1):
# produce true pairs:
first, second = self.tokenizer(review_sentences[i]), self.tokenizer(review_sentences[i+1])
nsp += [self._create_item(first, second, 1)]
# produce false pairs
first, second = self._select_false_nsp_sentences(sentences)
first, second = self.tokenizer(first), self.tokenizer(second)
nsp += [self._create_item(first, second, 0)]
return pd.DataFrame(nsp, columns=self.columns)
def _update_length(self, sentences: List[str], lengths: List[int]):
for v in sentences:
l = len(v.split())
lengths += [l]
return lengths
def _find_optimal_sentence_length(self, lengths: List[int]):
return int(np.percentile(np.array(lengths), self.OPTIMAL_LENGTH_PERCENTILE))
def _fill_vocab(self):
# specials= argument is only in 0.12.0 version
# specials=[self.CLS, self.PAD, self.MASK, self.SEP, self.UNK]
self.vocab = vocab(self.counter, min_freq=2)
# 0.11.0 uses this approach to insert specials
self.vocab.insert_token(self.CLS, 0)
self.vocab.insert_token(self.PAD, 1)
self.vocab.insert_token(self.MASK, 2)
self.vocab.insert_token(self.SEP, 3)
self.vocab.insert_token(self.UNK, 4)
self.vocab.set_default_index(4)
def _create_item(self, first: List[str], second: List[str], target: int = 1):
# create masked sentence items
updated_first, first_mask = self._preprocess_sentence(first.copy())
updated_second, second_mask = self._preprocess_sentence(second.copy())
nsp_sentence = updated_first + [self.SEP] + updated_second
nsp_indices = self.vocab.lookup_indices(nsp_sentence)
inverse_token_mask = first_mask + [True] + second_mask
# create sentence items without masking random words
first, _ = self._preprocess_sentence(first.copy(), should_mask=False)
second, _ = self._preprocess_sentence(second.copy(), should_mask=False)
original_nsp_sentence = first + [self.SEP] + second
original_nsp_indices = self.vocab.lookup_indices(original_nsp_sentence)
if self.should_include_text:
return(
nsp_sentence,
nsp_indices,
original_nsp_sentence,
original_nsp_indices,
inverse_token_mask,
target
)
else:
return (
nsp_indices,
original_nsp_indices,
inverse_token_mask,
target
)
def _select_false_nsp_sentences(self, sentences: List[str]):
"""Select sentences to create false NSP item
Args:
sentences: list of all sentences
Returns:
tuple of two sentences. The second one NOT the next sentence
"""
sentences_len = len(sentences)
sentence_index = random.randint(0, sentences_len - 1)
next_sentence_index = random.randint(0, sentences_len - 1)
# To be sure that it's not real next sentence
while next_sentence_index == sentence_index + 1:
next_sentence_index = random.randint(0, sentences_len - 1)
return sentences[sentence_index], sentences[next_sentence_index]
def _preprocess_sentence(self, sentence: List[str], should_mask: bool = True):
inverse_token_mask = []
if should_mask:
sentence, inverse_token_mask = self._mask_sentence(sentence)
sentence, inverse_token_mask = self._pad_sentence([self.CLS] + sentence, [True] + inverse_token_mask)
return sentence, inverse_token_mask
def _mask_sentence(self, sentence: List[str]):
"""Replace MASK_PERCENTAGE (15%) of words with special [MASK] symbol
or with random word from vocabulary
Args:
sentence: sentence to process
Returns:
tuple of processed sentence and inverse token mask
"""
len_s = len(sentence)
inverse_token_mask = [True for _ in range(max(len_s, self.optimal_sentence_length))]
mask_amount = round(len_s * self.MASK_PERCENTAGE)
for _ in range(mask_amount):
i = random.randint(0, len_s - 1)
if random.random() < 0.8:
sentence[i] = self.MASK
else:
# All is below 5 is special token
# see self._insert_specials method
j = random.randint(5, len(self.vocab) - 1)
sentence[i] = self.vocab.lookup_token(j)
inverse_token_mask[i] = False
return sentence, inverse_token_mask
def _pad_sentence(self, sentence: typing.List[str], inverse_token_mask: typing.List[bool] = None):
# preprocess [CLS] and [PAD] sentendce
len_s = len(sentence)
if len_s >= self.optimal_sentence_length:
# truncate
s = sentence[:self.optimal_sentence_length]
else:
# pad the sentence to optimal sentence length
s = sentence + [self.PAD] * (self.optimal_sentence_length - len_s)
if inverse_token_mask:
len_m = len(inverse_token_mask)
if len_m >= self.optimal_sentence_length:
inverse_token_mask = inverse_token_mask[:self.optimal_sentence_length]
else:
inverse_token_mask = inverse_token_mask + [True] * (self.optimal_sentence_length - len_m)
return s, inverse_token_mask
# testing
if __name__ == '__main__':
BASE_DIR = Path(__file__).resolve().parent.parent
ds = IMDBBertDataset(BASE_DIR.joinpath('data/imdb.csv'), ds_from=0, ds_to=50000,
should_include_text=True)
print(ds.df)
接下来构建 BERT 模型. 根据论文描述, 我们将模型拆分为以下的几个部分:
-
JointEmbedding: 负责建模Word Embedding,Segment Embedding和Position Embedding.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
class JointEmbedding(nn.Module): def __init__(self, vocab_size, size): super(JointEmbedding, self).__init__() self.size = size self.token_emb = nn.Embedding(vocab_size, size) self.segment_emb = nn.Embedding(vocab_size, size) self.norm = nn.LayerNorm(size) def forward(self, input_tensor): # compute the embeddings, add them together and normalize them sentence_size = input_tensor.size(-1) pos_tensor = self.attention_position(self.size, input_tensor) segment_tensor = torch.zeros_like(input_tensor).to(device) # this is achievable as we have padded each sentence to identical length during data preprocessing # in original paper, first and second sentence's segment embeddings are set to 0 and 1 so as to enable the model to differentiate sentences segment_tensor[:, sentence_size // 2 + 1:] = 1 # follow the paper's description output = self.token_emb(input_tensor) + self.segment_emb(segment_tensor) + pos_tensor return self.norm(output) def attention_position(self, dim, input_tensor): # compute positional embeddings for each token batch_size = input_tensor.size(0) sentence_size = input_tensor.size(-1) pos = torch.arange(sentence_size, dtype=torch.long).to(device) d = torch.arange(dim, dtype=torch.long).to(device) d = (2 * d / dim) pos = pos.unsqueeze(1) pos = pos / (1e4 ** d) pos[:, ::2] = torch.sin(pos[:, ::2]) pos[:, 1::2] = torch.cos(pos[:, 1::2]) return pos.expand(batch_size, *pos.size()) def numeric_position(self, dim, input_tensor): pos_tensor = torch.arange(dim, dtype=torch.long).to(device) return pos_tensor.expand_as(input_tensor)
-
自注意力机制和多头注意力机制层:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41
class AttentionHead(nn.Module): def __init__(self, dim_inp, dim_out): super(AttentionHead, self).__init__() self.dim_inp = dim_inp self.q = nn.Linear(dim_inp, dim_out) self.k = nn.Linear(dim_inp, dim_out) self.v = nn.Linear(dim_inp, dim_out) def forward(self, input_tensor: torch.Tensor, attention_mask: torch.Tensor = None): query, key, value = self.q(input_tensor), self.k(input_tensor), self.v(input_tensor) scale = query.size(1) ** 0.5 # \sqrt(input_size) attention_scores = torch.bmm(query, key.transpose(1, 2)) / scale # A = Q*(K^T)/sqrt(input_size); bmm == Batched Matrix Multiplication attention_scores = attention_scores.masked_fill_(attention_mask, -1e9) # prevent division by zero attention_val = f.softmax(attention_scores, dim=-1) # normalize attention scores attention_context = torch.bmm(attention_val, value) return attention_context class MultiHeadAttention(nn.Module): def __init__(self, num_heads, dim_inp, dim_out): super(MultiHeadAttention, self).__init__() # produce a batch of attention heads in parallel self.heads = nn.ModuleList([ AttentionHead(dim_inp, dim_out) for _ in range(num_heads) ]) # produce a linear layer for feature merging self.linear = nn.Linear(dim_out * num_heads, dim_inp) # normalize self.norm = nn.LayerNorm(dim_inp) def forward(self, input_tensor: torch.Tensor, attention_mask: torch.Tensor): s = [head(input_tensor, attention_mask) for head in self.heads] attention_values = torch.cat(s, dim=-1) attention_values = self.linear(attention_values) return self.norm(attention_values)
Transformer Encoder:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
class Encoder(nn.Module): def __init__(self, dim_inp, dim_out, attention_heads=4, dropout=0.1): super(Encoder, self).__init__() # batch_size x sentence size x dim_inp self.attention = MultiHeadAttention(attention_heads, dim_inp, dim_out) self.feed_forward = nn.Sequential( nn.Linear(dim_inp, dim_out), nn.Dropout(dropout), nn.GELU(), nn.Linear(dim_out, dim_inp), nn.Dropout(dropout) ) self.norm = nn.LayerNorm(dim_inp) def forward(self, input_tensor: torch.Tensor, attention_mask: torch.Tensor): context = self.attention(input_tensor, attention_mask) res = self.feed_forward(context) return self.norm(res)
- 调用和集成上述类的
BERT类:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
class BERT(nn.Module): def __init__(self, vocab_size, dim_inp, dim_out, attention_heads=4): super(BERT, self).__init__() self.embedding = JointEmbedding(vocab_size, dim_inp) self.encoder = Encoder(dim_inp, dim_out, attention_heads) self.token_prediction_layer = nn.Linear(dim_inp, vocab_size) self.softmax = nn.LogSoftmax(dim=-1) self.classification_layer = nn.Linear(dim_inp, 2) def forward(self, input_tensor: torch.Tensor, attention_mask: torch.Tensor): embeddeding = self.embedding(input_tensor) encoded_embedding = self.encoder(embeddeding, attention_mask) token_predictions = self.token_prediction_layer(encoded_embedding) first_word = encoded_embedding[:, 0, :] return self.softmax(token_predictions), self.classification_layer(first_word)
最后编写 Loss 计算和模型训练逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
import time
from datetime import datetime
from pathlib import Path
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from bert.dataset import IMDBBertDataset
from bert.model import BERT
# select CUDA, CPU or MPS device accordingly
device = torch.device("cuda" if torch.cuda.is_available() else ("mps" if torch.backends.mps.is_available() else "cpu"))
def percentage(batch_size: int, max_index: int, current_index: int):
"""Calculate epoch progress percentage
Args:
batch_size: batch size
max_index: max index in epoch
current_index: current index
Returns:
Passed percentage of dataset
"""
batched_max = max_index // batch_size
return round(current_index / batched_max * 100, 2)
def nsp_accuracy(result: torch.Tensor, target: torch.Tensor):
"""Calculate NSP accuracy between two tensors
Args:
result: result calculated by model
target: real target
Returns:
NSP accuracy
"""
s = (result.argmax(1) == target.argmax(1)).sum()
return round(float(s / result.size(0)), 2)
def token_accuracy(result: torch.Tensor, target: torch.Tensor, inverse_token_mask: torch.Tensor):
"""Calculate MLM accuracy between ONLY masked words
Args:
result: result calculated by model
target: real target
inverse_token_mask: well-known inverse token mask
Returns:
MLM accuracy
"""
r = result.argmax(-1).masked_select(~inverse_token_mask)
t = target.masked_select(~inverse_token_mask)
s = (r == t).sum()
return round(float(s / (result.size(0) * result.size(1))), 2)
class BertTrainer:
def __init__(self,
model: BERT,
dataset: IMDBBertDataset,
log_dir: Path,
checkpoint_dir: Path = None,
print_progress_every: int = 10,
print_accuracy_every: int = 50,
batch_size: int = 24,
learning_rate: float = 0.005,
epochs: int = 5,
):
self.model = model
self.dataset = dataset
self.batch_size = batch_size
self.epochs = epochs
self.current_epoch = 0
self.loader = DataLoader(self.dataset, batch_size=self.batch_size, shuffle=True)
self.writer = SummaryWriter(str(log_dir))
self.checkpoint_dir = checkpoint_dir
self.criterion = nn.BCEWithLogitsLoss().to(device)
self.ml_criterion = nn.NLLLoss(ignore_index=0).to(device)
self.optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=0.015)
self._splitter_size = 35
self._ds_len = len(self.dataset)
self._batched_len = self._ds_len // self.batch_size
self._print_every = print_progress_every
self._accuracy_every = print_accuracy_every
def print_summary(self):
ds_len = len(self.dataset)
print("Model Summary\n")
print('=' * self._splitter_size)
print(f"Device: {device}")
print(f"Training dataset len: {ds_len}")
print(f"Max / Optimal sentence len: {self.dataset.optimal_sentence_length}")
print(f"Vocab size: {len(self.dataset.vocab)}")
print(f"Batch size: {self.batch_size}")
print(f"Batched dataset len: {self._batched_len}")
print('=' * self._splitter_size)
print()
def __call__(self):
for self.current_epoch in range(self.current_epoch, self.epochs):
loss = self.train(self.current_epoch)
self.save_checkpoint(self.current_epoch, step=-1, loss=loss)
def train(self, epoch: int):
print(f"Begin epoch {epoch}")
prev = time.time()
average_nsp_loss = 0
average_mlm_loss = 0
for i, value in enumerate(self.loader):
index = i + 1
inp, mask, inverse_token_mask, token_target, nsp_target = value
self.optimizer.zero_grad()
token, nsp = self.model(inp, mask)
tm = inverse_token_mask.unsqueeze(-1).expand_as(token)
token = token.masked_fill(tm, 0)
loss_token = self.ml_criterion(token.transpose(1, 2), token_target) # 1D tensor as target is required
loss_nsp = self.criterion(nsp, nsp_target)
loss = loss_token + loss_nsp
average_nsp_loss += loss_nsp
average_mlm_loss += loss_token
loss.backward()
self.optimizer.step()
if index % self._print_every == 0:
elapsed = time.gmtime(time.time() - prev)
s = self.training_summary(elapsed, index, average_nsp_loss, average_mlm_loss)
if index % self._accuracy_every == 0:
s += self.accuracy_summary(index, token, nsp, token_target, nsp_target, inverse_token_mask)
print(s)
average_nsp_loss = 0
average_mlm_loss = 0
return loss
def training_summary(self, elapsed, index, average_nsp_loss, average_mlm_loss):
passed = percentage(self.batch_size, self._ds_len, index)
global_step = self.current_epoch * len(self.loader) + index
print_nsp_loss = average_nsp_loss / self._print_every
print_mlm_loss = average_mlm_loss / self._print_every
s = f"{time.strftime('%H:%M:%S', elapsed)}"
s += f" | Epoch {self.current_epoch + 1} | {index} / {self._batched_len} ({passed}%) | " \
f"NSP loss {print_nsp_loss:6.2f} | MLM loss {print_mlm_loss:6.2f}"
self.writer.add_scalar("NSP loss", print_nsp_loss, global_step=global_step)
self.writer.add_scalar("MLM loss", print_mlm_loss, global_step=global_step)
return s
def accuracy_summary(self, index, token, nsp, token_target, nsp_target, inverse_token_mask):
global_step = self.current_epoch * len(self.loader) + index
nsp_acc = nsp_accuracy(nsp, nsp_target)
token_acc = token_accuracy(token, token_target, inverse_token_mask)
self.writer.add_scalar("NSP train accuracy", nsp_acc, global_step=global_step)
self.writer.add_scalar("Token train accuracy", token_acc, global_step=global_step)
return f" | NSP accuracy {nsp_acc} | Token accuracy {token_acc}"
def save_checkpoint(self, epoch, step, loss):
if not self.checkpoint_dir:
return
prev = time.time()
name = f"bert_epoch{epoch}_step{step}_{datetime.utcnow().timestamp():.0f}.pt"
torch.save({
'epoch': epoch,
'model_state_dict': self.model.state_dict(),
'optimizer_state_dict': self.optimizer.state_dict(),
'loss': loss,
}, self.checkpoint_dir.joinpath(name))
print()
print('=' * self._splitter_size)
print(f"Model saved as '{name}' for {time.time() - prev:.2f}s")
print('=' * self._splitter_size)
print()
def load_checkpoint(self, path: Path):
print('=' * self._splitter_size)
print(f"Restoring model {path}")
checkpoint = torch.load(path)
self.current_epoch = checkpoint['epoch']
self.model.load_state_dict(checkpoint['model_state_dict'])
self.optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
print("Model is restored.")
print('=' * self._splitter_size)
完整代码参见: 此处
GPT
由于不同代际的 GPT 类模型网络架构基本相同, 此处仅描述 GPT-1 和 GPT-2.
介绍
GPT 是典型的自回归模型, 适用于文本生成任务. 为了构造 既能捕捉文本内在信息, 又能广泛适应多种场景 的优化目标, OpenAI 提出了 GPT-1. 和 BERT 相同, GPT 的训练方法也是 无监督预训练, 并基于 自然语言处理领域中多种任务 均可被视为 基于输入生成某种输出 的范式, 其训练目标被设计为 文本补全 (也就是文本续写).
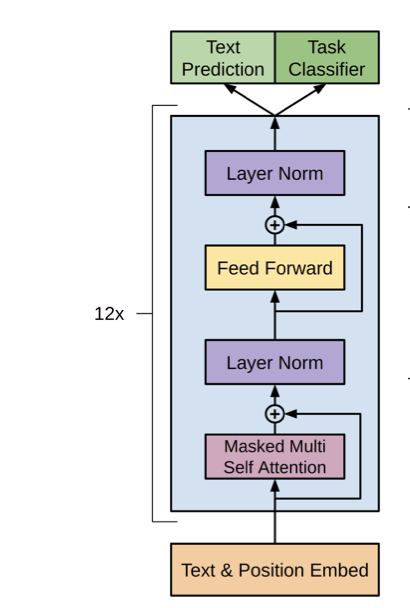
模型架构
为了服务文本补全的设计目标, GPT 基于 Transformer 架构中的解码器 (Decoder) 构建. 在 GPT-1 中, 输入Embedding 被设计为 $768$ 维, 并堆叠了 $12$ 个解码器基本层, 每个基本层由 Masked Multi-Head Self Attention 层, Layer Norm 和前馈神经网络结合残差连接构成.
实现
T5
我们简述典型的 Encoder-Decoder 模型: T5.
介绍
模型架构
多模态视觉语言模型
参考
https://nthu-datalab.github.io/ml/labs/12-1_Seq2Seq-Learning_Neural-Machine-Translation/12-1_Seq2Seq-Learning_Neural-Machine-Translation.html
https://github.com/gursi26/seq2seq-attention
https://d2l.ai/chapter_attention-mechanisms-and-transformers/bahdanau-attention.html
https://medium.com/@a.akhterov/step-by-step-understanding-of-the-bahdanau-attention-mechanism-with-code-5c62e280ca13
https://zhuanlan.zhihu.com/p/136559171
https://mylens.ai/lens/the-evolution-of-attention-mechanism-in-artificial-intelligence-xsq3vf/
https://zhuanlan.zhihu.com/p/631398525?utm_id=0&wd=&eqid=be38b6e2000b4b43000000036545ba6f
https://www.elecfans.com/d/883694.html
https://arxiv.org/abs/1409.3215
https://arxiv.org/abs/1406.1078
https://arxiv.org/abs/1706.03762
https://github.com/EvilPsyCHo/Attention-PyTorch
https://blog.csdn.net/weixin_53598445/article/details/125009686
https://aclanthology.org/2020.acl-main.312/
https://blog.csdn.net/beilizhang/article/details/115282604
https://blog.csdn.net/weixin_43334693/article/details/130189238?spm=1001.2014.3001.5502
https://blog.csdn.net/hxxjxw/article/details/120134012
https://zhuanlan.zhihu.com/p/481559049
https://zhuanlan.zhihu.com/p/459828118
https://zhuanlan.zhihu.com/p/348593638
https://blog.csdn.net/weixin_43334693/article/details/130208816
https://twitter.com/lvwerra/status/1507035164832055318
https://zhuanlan.zhihu.com/p/625714067?utm_id=0
https://huggingface.co/docs/transformers/model_summary
https://aman.ai/primers/ai/autoregressive-vs-autoencoder-models/
https://blog.csdn.net/weixin_44750512/article/details/128903695
https://zhuanlan.zhihu.com/p/609284285?utm_id=0
https://coaxsoft.com/blog/building-bert-with-pytorch-from-scratch
https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270