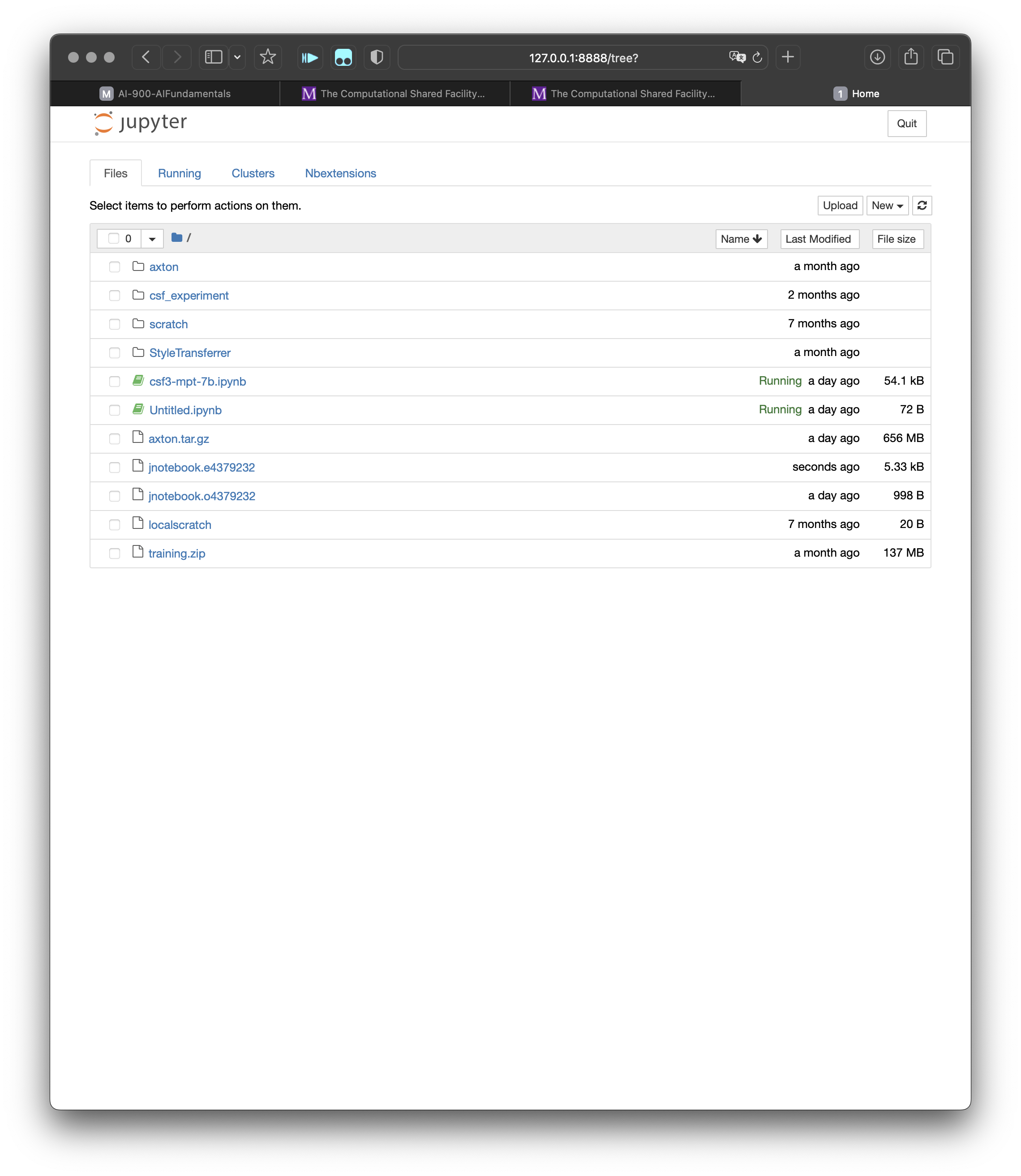
奇技淫巧 CSF3 Computation Cluster使用指南
随着深度学习的发展, 在曼彻斯特大学越来越多的计算机系大三年级本科生选择与机器学习/人工智能/大语言模型/计算机视觉相关的毕业设计项目, 但是训练一个深度学习模型需要大量的计算资源, 绝大多数学生的计算机无法满足这一需求. 为了解决这一问题, 曼大计算机系为这些学生特批了使用CSF3 Computation Cluster的权限, 本文将介绍CSF3的申请流程和基本使用方法, 以及一些提升使用体验的奇技淫巧.
什么是CSF3?
根据曼大计算机系CSF3主页, CSF是曼彻斯特大学的高性能计算 (HPC )集群, 具有约8644个处理器核心和100个GPU (nVIDIA V100 和 nVIDIA A100), 原则上仅供博士, 硕士研究生等研究人员使用, 但大三年级本科生可以申请用于毕业设计项目的计算资源.
需要注意, 大三本科生可申请的 GPU 仅限于 nVIDIA V100, 且每个学生默认只能申请一块 GPU. 但是, 在申请时可以说明自己项目的特殊性, 从而获取到更多的计算资源.
申请CSF3使用权限
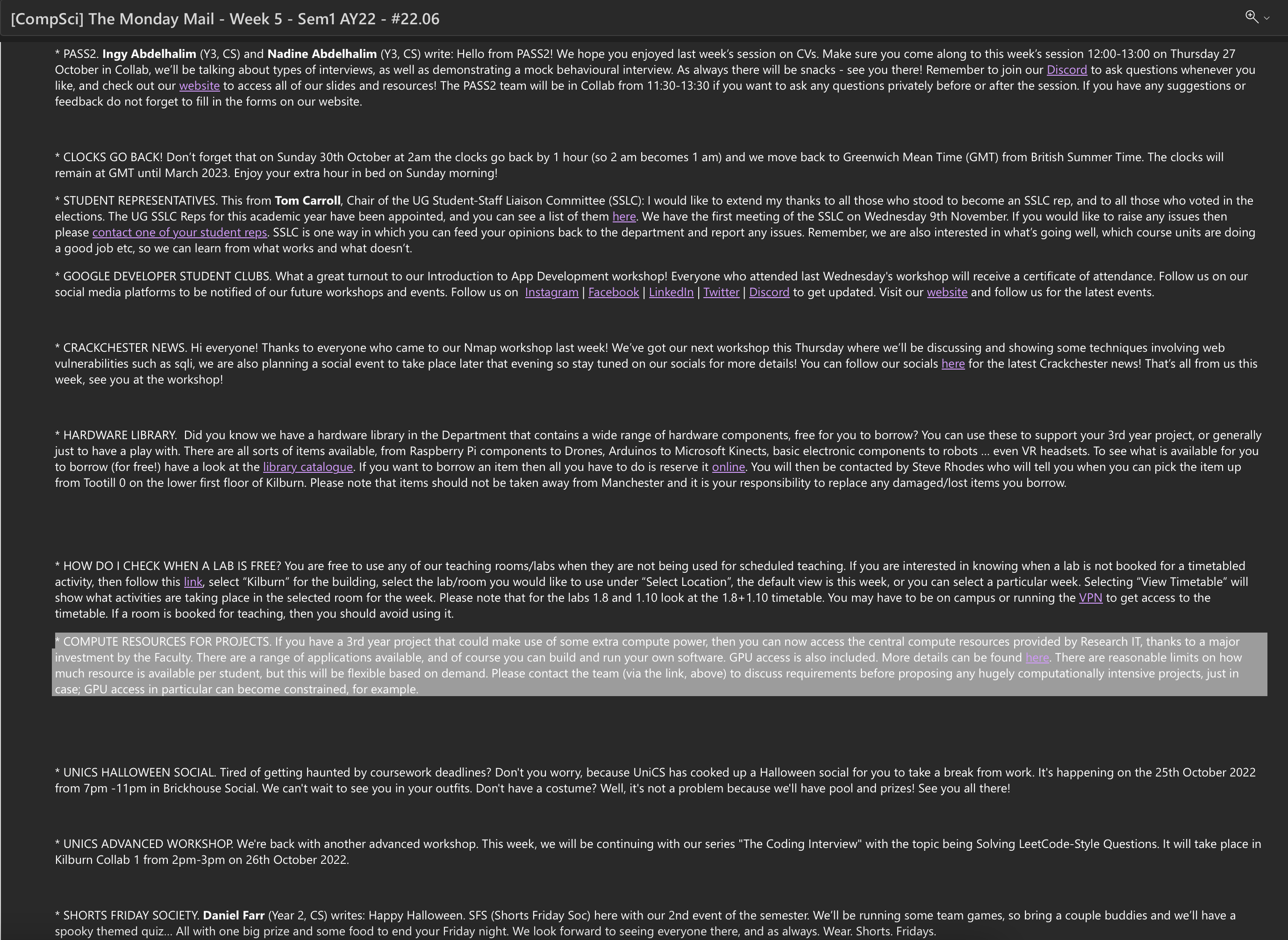
大约在10月末时, Paul会在某一篇 Monday Mail 中很隐晦的地方提及CSF3开放申请的通知, 如下图所示:
随后, 点击链接即可被重定位到该网页:

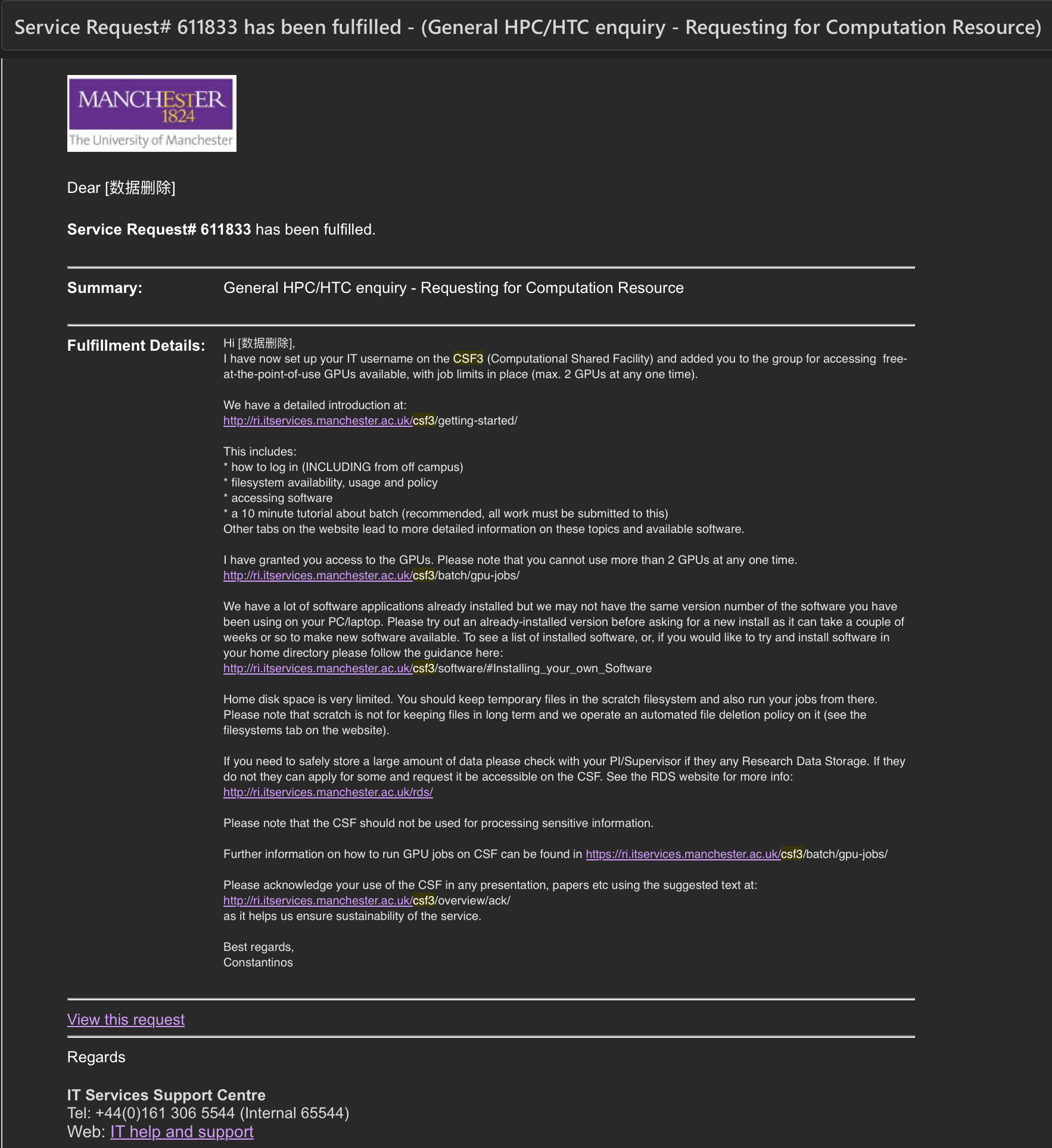
向邮箱地址 its-ri-team@manchester.ac.uk 发送申请邮件有机会获得CSF3计算资源. 若需要多块 GPU, 个人建议在邮件中附上自己的 Research Proposal, 以说明额外的计算资源的必要性. 一般在几个工作日内就会收到确认邮件:
访问CSF3
在申请通过后, 我们即可通过 SSH 访问 CSF3.
在校内使用 SSH 访问
在校内可以直接通过
1
ssh <username>@csf3.itservices.manchester.ac.uk
访问 CSF3. 为方便使用, macOS 用户可使用 Termius. 注意, 曼大的学生邮箱可通过 Github 的学生白嫖包激活 Termius 的学生账户, 从而获得 Termius 的高级功能.
在校外使用 SSH 访问
在校外环境中, 访问 CSF3 存在两点困难. 首先需要通过 VPN 连接到曼大的内网, 其次需要使用 kilburn 作为跳板机连接到 CSF3.
配置和连接曼大VPN可参考 学校官方文档, kilburn 跳板机的连接方式如下:
1
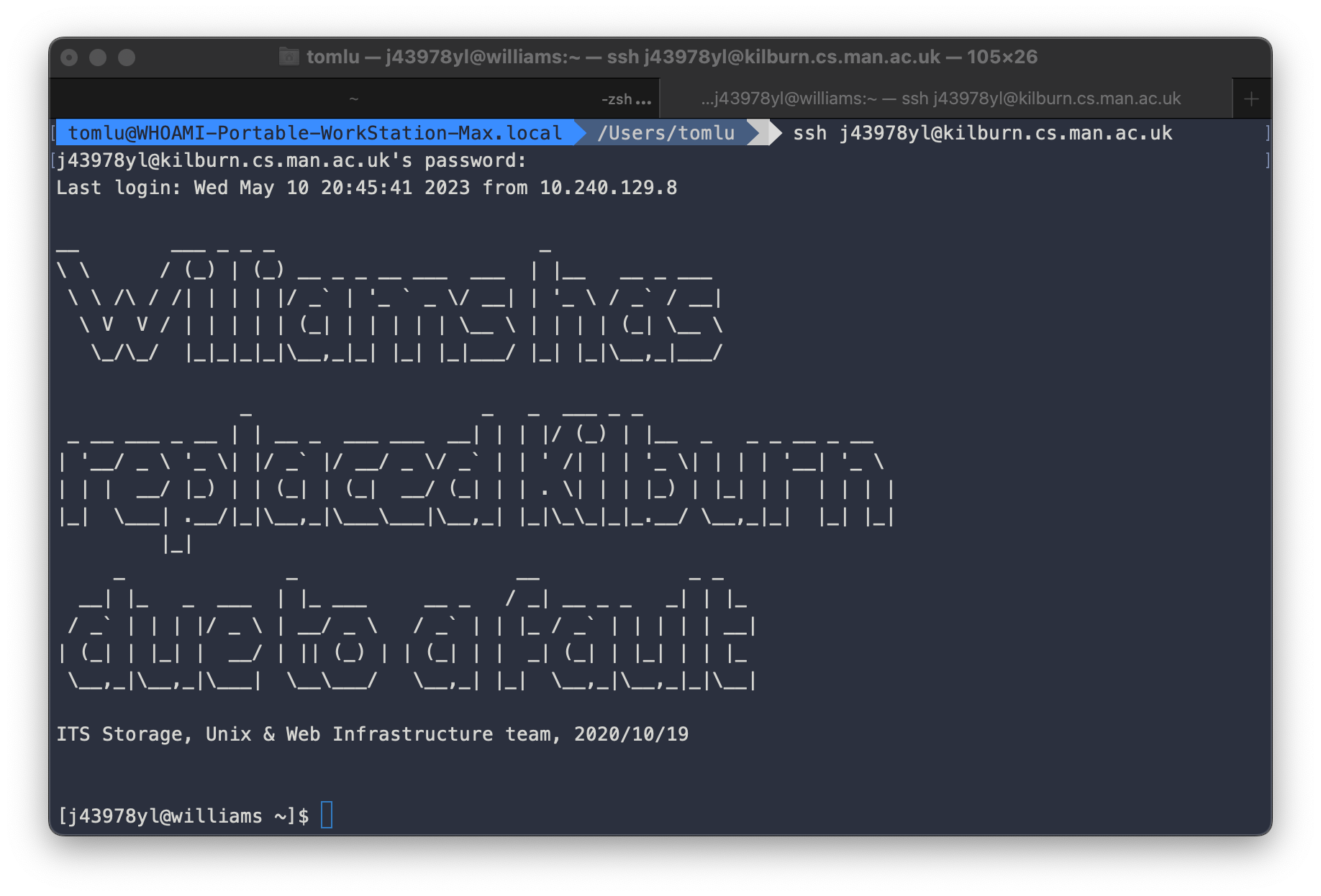
ssh <username>@kilburn.cs.man.ac.uk
登陆成功后终端页面如下图所示:
随后, 就可在跳板机上使用相同的命令连接到 CSF3.
使用CSF3
本科生不具有在 CSF3 上安装软件包的权限, 但是可以通过 module 加载已经安装好的软件包. 本节将介绍如何加载常用的软件包, 如 Jupyter Notebook, PyTorch, TensorFlow 等.
加载软件包
CSF3 Computation Cluster中预装了大量的软件包, 但必须使用 module 命令加载才能使用. 我们可以在 这里 获取CSF3运行环境中预装的所有软件包列表. 下面介绍数个常用的软件包的加载方法.
Jupyter Notebook
根据个人使用经验, 建议加载 2019.03 版本的 Jupyter Notebook:
1
module load apps/binapps/jupyter-notebook/5.7.8 # Uses anaconda3/2019.03
在当前运行环境加载软件包后, 需要启动 Jupyter Notebook 服务器. 在加载服务器时, 可选定处理器核心数, 是否分配GPU等参数. 例如, 我们可以在 CSF3 上启动一个使用 nVIDIA V100 的 Jupyter Notebook 服务器:
1
jupyter-notebook-csf -p 8 -g 1 # runs a parallel 8-core job - on a GPU node using 1 GPU
启动 Jupyter Notebook 本质上是提交了一个 Batch Job, 该任务的命名规则为 jnotebook, 并会被自动分配一个 jobid, 数值越大说明任务排名越靠后. 该任务会在后台运行, 我们可以通过 qstat 命令查看任务运行状态:
1
2
3
4
[j43978yl@login1 [csf3] ~]$ qstat
job-ID prior name user state submit/start at queue slots ja-task-ID
-----------------------------------------------------------------------------------------------------------------
4379232 0.35174 jnotebook j43978yl r 06/03/2023 17:17:36 nvidiagpu.q@node815.pri.csf3.a 8
在任务启动成功后, 将会在本地生成两个文件, 一个是 jnotebook.o<jobid> 文件, 一个是 jnotebook.e<jobid> 文件. 分别对应任务的标准输出和标准错误. 我们可以通过 cat 命令查看任务的输出. jnotebook.o<jobid> 文件中会包含如何通过建立 SSH Tunnel 访问 Jupyter Notebook 的说明, 以及 Jupyter Notebook 的 token.
为了省事, 也可以参考 该方法 关闭 Jupyter Notebook 的 token 验证, 从而无需token即可访问 Jupyter Notebook.
注意, 你自己机器上的 VSCode 可能会在本地运行一个映射端口号相同的 Jupyter Notebook 服务器, 从而导致无法访问 CSF3 上的 Jupyter Notebook 服务器. 若遇到输入 token 仍然无法访问的情况, 可以尝试通过退出 VSCode 等方式关闭本地的 Jupyter Notebook 服务器.
更详细的 Jupyter Notebook 的使用方法, 可参考官方文档: Jupyter Notebook
PyTorch
PyTorch 也是一个二进制软件包, 同样需要通过 module 加载:
1
2
# Python 3.7 for GPUS: (uses CUDA 10.1.168, Anaconda3 2019.07)
module load apps/binapps/pytorch/1.3.1-37-gpu
在加载 PyTorch 后, 是不能直接使用的, 需要进入交互模式或批处理模式调用 GPU 和 PyTorch. 对这两个模式的描述见下文.
CSF3页面对 PyTorch 的详细使用文档见此处.
TensorFlow
Tensorflow 的调用方法和 PyTorch 类似, 详细的官方文档见此处.
文件处理
Linux 环境下的文件处理属于基本知识, 但考虑到受众文化水平参差不齐的可能性, 此处做简单介绍.
文件传输
我们使用 sftp 在本地和 CSF3 之间传输文件. 具体使用方法可参阅此处.
文件压缩
个人建议在 CSF3 上使用 tar 命令进行文件压缩, 具体使用方法可参阅此处.
文件解压
训练数据集, 机器学习代码仓库等大文件或复杂文件夹需要在压缩后使用 sftp 协议传输到 CSF3 上, 传输完成后需要解压. CSF3 内置了 unzip, 具体使用方法可参阅此处.
交互模式和 BatchJob (批处理)模式
为了减少对资源的消耗并提高效率, CSF3 的程序执行方式被分为交互模式和批处理模式. 一般地, 交互模式下若用户在约一小时内没有进行任何操作, 会被自动登出, 而批处理模式下用户提交的任务会在后台运行, 不会被自动终止.
在交互模式下, 用户会被重定向到一个 node 上, 该 node 会被分配给用户独享, 用户可以在该 node 上进行交互式的程序开发和调试. 在批处理模式下, 用户提交一个 Batch Job 到 CSF3 的 queue 中, CSF3 会在有空闲资源时自动分配资源给用户, 用户的程序会在后台运行, 用户可以通过 qstat 命令查看任务运行状态.
用户在批处理模式下无法直接进行交互式的程序开发和调试, 程序运行的输出会被重定向到 job_name.o<jobid> 文件中, 用户可以通过 cat 命令查看输出.
提交 Batch Job
下面以 PyTorch 为例, 介绍如何在 CSF3 上提交 Batch Job.
编写 Batch Job 脚本
为了将任务提交到 CSF3 的 queue 中, 我们需要编写一个 Batch Job 脚本, 该脚本包含了任务的描述和运行命令. 以 PyTorch 为例, 我们可以编写如下的 Batch Job 脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#!/bin/bash --login
#$ -cwd # Run job from directory where submitted
# If running on a GPU, add:
#$ -l v100=1
#$ -pe smp.pe 8 # Number of cores on a single compute node. GPU jobs can
# use up to 8 cores per GPU.
# We now recommend loading the modulefile in the jobscript
module load apps/binapps/pytorch/1.0.1-36-gpu
# $NSLOTS is automatically set to the number of cores requested on the pe line.
# Inform some of the python libraries how many cores we can use.
export OMP_NUM_THREADS=$NSLOTS
python my-gpu-script.py
随后需要使用 qsub 命令将该脚本提交到 CSF3 的 queue 中:
1
qsub <script_name>
奇技淫巧
启用 Jupyter Notebook 中对 PyTorch 的支持
原则上, PyTorch 只能在交互模式下使用, 但我们可以通过 Jupyter Notebook 在批处理模式下使用 PyTorch. 这个 hack 是通过在分配了至少一个 GPU 核心的 Jupyter Notebook 实例中加载 PyTorch 的二进制文件实现的. 具体步骤如下:
首先在新创建的 Jupyter Notebook 中运行第一个代码块, 该代码块会检查本 Jupyter Server 中 Python 的路径:
1
2
import sys
sys.executable
输出形为
1
'/opt/apps/apps/binapps/<python_path>/python'
随后, 检查 Python 版本:
1
!/opt/apps/apps/binapps/<python_path>/python --version
然后选择合适的 PyTorch 版本, 并加载:
1
!/opt/apps/apps/binapps/<python_path>/python -m pip install --user torch
最后, 检查 PyTorch 是否成功加载:
1
2
import torch
torch.cuda.is_available()
然后, 就可以正常使用 PyTorch 了. 使用 Tensorflow 的方法类似, 只需对应替换软件包路径即可.
通过 SSH Tunnel 在校外访问 Jupyter Notebook
上文提到, CSF3 的 Jupyter Notebook 服务在不做任何 hack 的情况下只能在校内访问, 但我们可以通过手动搭建从跳板机到本机的 SSH Tunnel 在校外访问 Jupyter Notebook.
假设我们已在 CSF3 上成功运行了 Jupyter Notebook, 已得知 CSF3上 Jupyter Notebook 的对应端口为 $8888$, 并已连接到了 kilburn 跳板机, 接下来我们需要首先在 kilburn 上启动一个 SSH Tunnel, 将 CSF3 上的 8888 端口通过 SSH Tunnel 映射到 kilburn跳板机的 8888 端口上, 然后再构建第二个 SSH Tunnel, 将 kilburn 跳板机的 8888 端口通过 SSH Tunnel 映射到本机的 8888 端口上. 具体步骤如下:
首先在 kilburn 上启动第一个 SSH Tunnel:
1
ssh -L 8888:node815:8888 <user_name>@csf3.itservices.manchester.ac.uk
注: 上述命令中的 node815 是 CSF3 上 Jupyter Notebook 的 node 名称, 每次启动 Jupyter Notebook 时都会随机分配一个 node 给用户, 此处需要根据实际情况进行替换. 该命令可在 CSF3 根目录中的 jnotebook.o<jobid> 文件中找到.
随后在本机启动第二个 SSH Tunnel:
1
ssh -L 8888:127.0.0.1:8888 <user_name>@kilburn.cs.man.ac.uk
上述命令将 kilburn 跳板机的 8888 端口映射到本机的 8888 端口上, 此时我们就可以在本机的浏览器中访问 Jupyter Notebook 了.