
空间枚举和剔除
本章介绍一系列有助于提升 渲染性能 的技术: 空间枚举/空间索引 (Spatial Enumeration / Spatial Indexing) 和剔除 (Culling).
空间枚举
空间枚举所需要解决的问题是 如何在用于绘制三维场景的数据结构, 如多边形, 网格, 纹理等, 和实际应用于某些具体场景, 如游戏, 建模中的数据结构之间构建合理的链接. 其问题在于: 基本上并不存在完美适配这两种不同情形的数据结构, 因此需要使用 空间枚举 为它们之间搭建桥梁和链接, 如同为数据库搭建索引, 以实现对数种常见查询 (Query) 的高效适配一样.
在计算机图形学的应用场景中, 同样和数据库应用一样, 存在多种极为常见的应用, 如: 检测物体之间的碰撞, 找出场景中所有从该视点看去可见的物体等. 空间枚举技术就可以通过建立用于渲染的数据结构的索引, 对这些应用进行 加速. 此外, 利用空间枚举技术, 光线追踪渲染, 辐射着色渲染和体积渲染等的效率也可以得到提升.
Gridcell
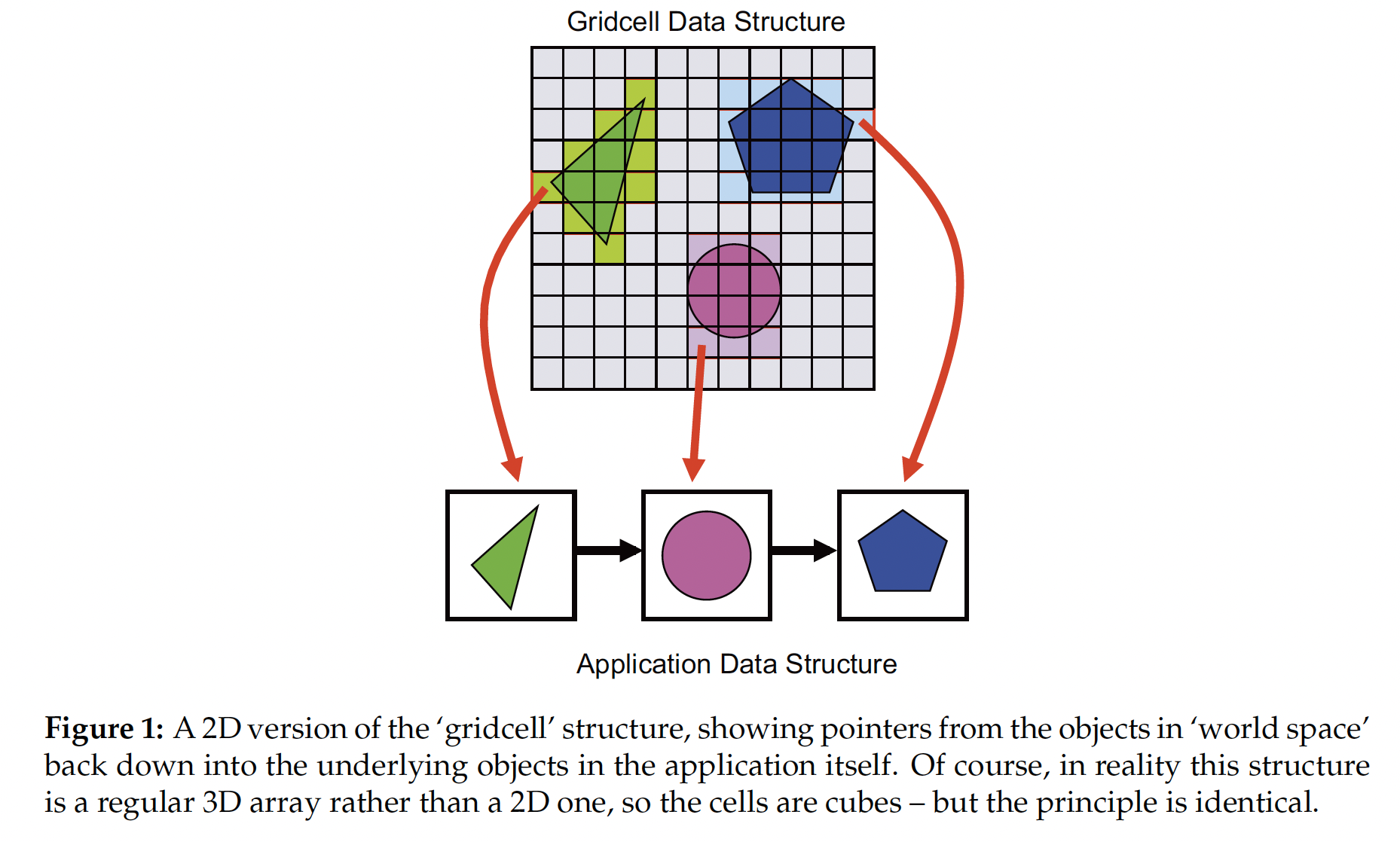
首先, 最简单的空间枚举技术就是 Gridcell: 它将空间切分为多个 立方体分块, 然后将这个切分应用到场景内, 显然场景中的任何物体都可能和某些分块相交, 或完整填充某些分块. 而进一步地, 任何与场景中的某个物体相交或被填充的分块都会被赋予一个 指向某个表示该物体的数据结构的指针, 由此若在空间中随机选定一点, 我们就可以首先确定这个点在 Gridcell 的哪一个区块中, 进一步检查该区块是否和某个物体相交.
构建 Gridcell 的空间复杂度为 $O(n^3)$, 而查询时间复杂度仅为 $O(1)$, 因此 Gridcell 是在查询时间上极为高效, 但空间利用率很差的索引数据结构.
值得注意的是: 本质上我们在体积渲染一章中接触到的 Volume Set, 或 Voxel Structure, 也就是 Gridcell.
OctTree
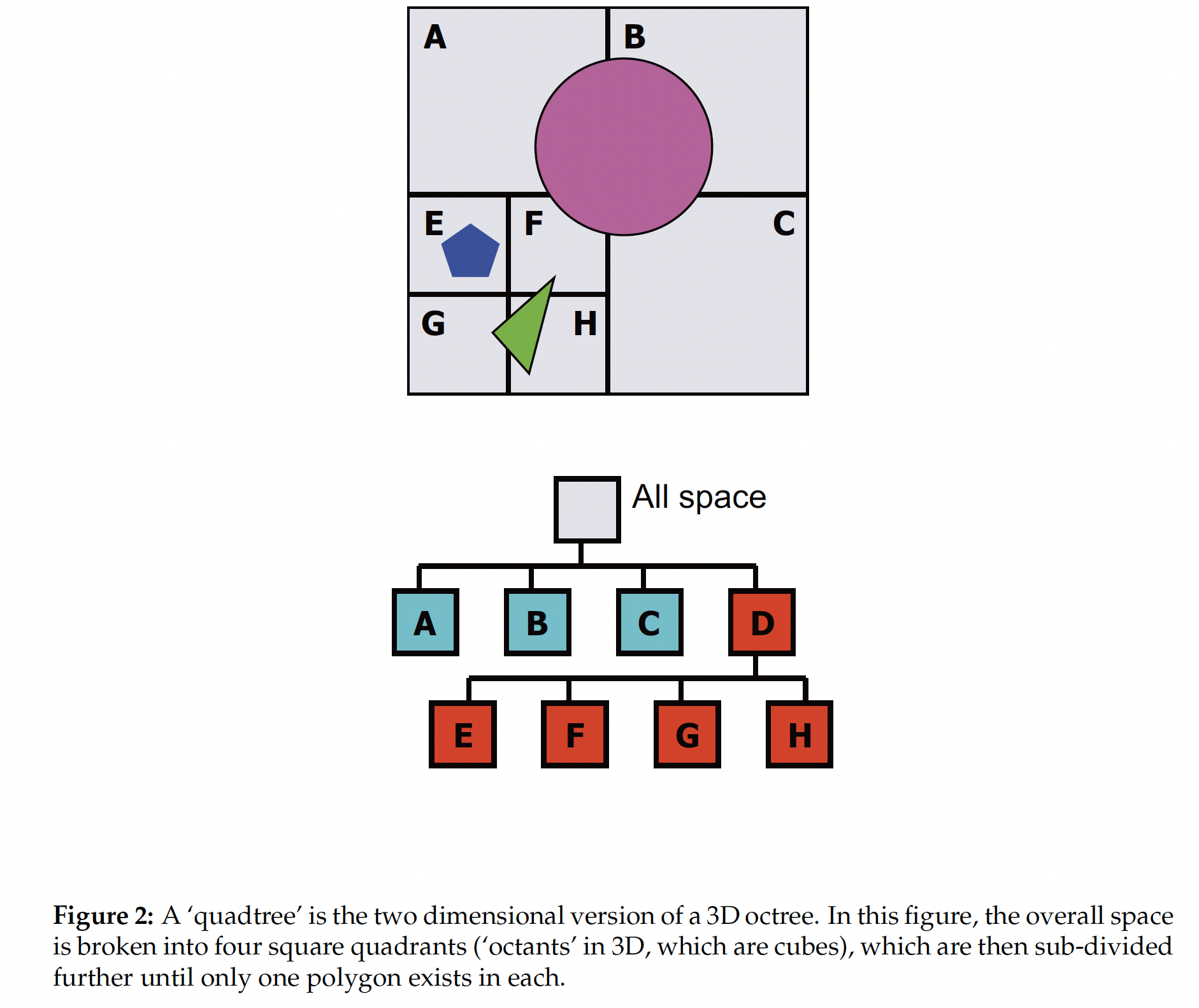
八叉树 (OctTree) 是基于 Gridcell 演变而来的数据结构, 它通过 不对任何不包含物体的空间区块进行任何进一步地分划 而规避了 Gridcell 空间利用率低下的问题. 支持八叉树的基本理论是 Spatial Coherence: ”Stuff tend to cluster together“: 空间中 同属于一个物体 的区块往往都是紧密联系在一起的, 而整个空间中绝大多数的分划其实都是空的.
八叉树的构建过程是 动态和递归 的. 首先它将整个空间视为一整个大的分划, 然后将空间分为 $8$ 份, 检查每一份中是否包含任何物体, 如果否的话 不再对这个子区块进行任何进一步的分划, 否则就要对它 进行类似的 $8$ 份分划和检查, 直到满足递归停止条件, 如达到最大递归深度或分划区块中不再包含足够多的物体, 为止.
八叉树的构建过程是 递归 的, 这很好理解. 它同时是 动态 的, 因为决定某个区块的分划是否被执行取决于 这个区块中是否包含任何物体, 换言之使用这一算法构建出的八叉树是什么样的实际取决于特定的场景, 而非一成不变的.
Hierarchical Bounding Volumes (HBV)
Hierarchical Bounding Volumes 和接下来要介绍的 Binary Space Partitioning 都是用于简化 碰撞检测 的技术.
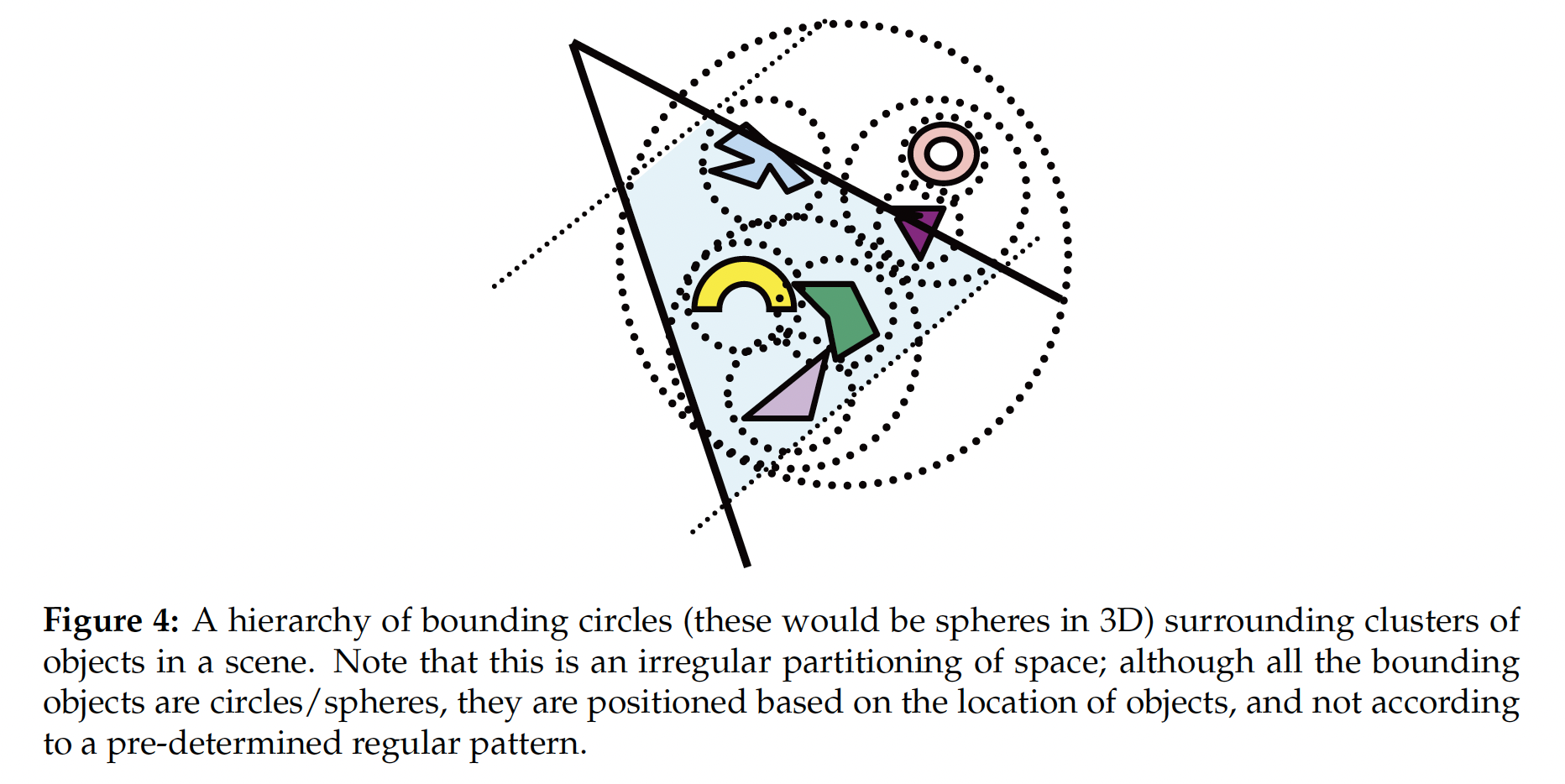
绝大多数的场景中, 物体都由大量的多边形组成, 而在计算 “射入场景的一束光是否和物体碰撞” 时, 如果不加优化就需要涉及大量的 “检查光是否和多边形发生碰撞” 的计算. Hierarchical Bounding Volumes 的优化原理是: 使用 在计算上成本更低的 Bounding Volume 将包含大量多边形的物体包围, 在检测光线是否和物体发生碰撞之前, 首先检查光线是否和该物体的 Bounding Volume 发生碰撞, 从而节约计算资源.
一般地, 圆 和 正方体 是计算 (光线与物体间) 碰撞检测成本较低的几何形状, 因此常常被拿来直接用于作为物体的 Bounding Volume. 而要进一步优化的话, 就可以使用 Bounding Cube: 使用 立方体 作为物体的 Bounding Volume, 就可以在消耗相似计算资源的情况下, 更紧密地包裹住物体, 降低 Bounding Volume 中实际不属于物体的体积, 减少碰撞检测中可能发生的 False Positive.
再进一步地, 我们可以将 物体的各个组成部分拆解, 分别构建这些组成部分的 Bounding Volume, 然后将它们进行 组合, 也就是允许 Bounding Volume 嵌套, 为物体构造 Hierarchical Bounding Volume. 从概念上说, 这一过程类似于 Octree 构建过程的反向: 首先为物体的组成中 层级最低 的部分构建 Bounding Volume, 然后将它们进一步组合在一起, 构建为层级中更抽象的组成部分的 Bounding Volume, 以此类推.
值得注意的是, 与 Gridcell 和 Octree 不同, HBV 是一种 “Irregular” 的空间枚举, 这是因为它对空间进行的划分区块并不总是 体积相等形状相同 的, 而且其划分的模式 完全取决于被划分的物体.
Binary Space Partitioning
最后要介绍的空间划分技术是 Binary Space Partitioning. 在回答 “与给定的射入光线相交的, 离视平面最近的物体是什么” 这类问题时, 如果有一个保持了空间中相对位置的空间划分, 问题就会变得非常简单.
Binary Space Partitioning 能够 保持空间中相对位置, 也就是上下左右前后相对位置. 特别地, 我们所介绍的 Axis-Aligned Binary Space Partitioning 在对空间进行划分时, 会 递归地将场景划分为两个部分, 并且任何一次划分都是 沿着某一个坐标轴 进行的:
如下图所示的例子: 我们首先将空间垂直分成两部分,如图中的第 $0$ 列所示. 然后, 将这两个空间分别 水平划分 为两部分 (如第 $1a$ 行和 $1b$ 行). 然后再对它们依次垂直划分, 再水平划分, 依此类推, 直到达到某个终止条件为止.
这种方法的优点是: 它保留了 对象在不同区域中的相对位置: 即在垂直分区的左侧和右侧, 以及在水平分区的前面/后面.
对 Axis-Aligned Binary Space Partitioning 的一种改进方式是: 允许划分 沿着任意的坐标轴进行. 此外, 还可以在进行空间划分时, 利用空间中 物体表面多边形, 沿着多边形表示的平面进行划分, 这就是所谓的 Polygon-Aligned Binary Space Partitioning.
剔除
剔除 (Culling) 用于在渲染前 剔除没有必要被渲染的空间元素, 从而节约渲染时间.
Detail Culling
Detail Culling 的原则是: 如果场景中有任何 “即使被渲染了也在感官上和没渲染没有区别” 的元素, 则舍弃这些元素, 比如 本身就很小的细节, 或 距离视点太远以至于看上去很小的物体. 对 运动场景 而言, Detail Culling 尤其适用.
Backface Culling
Backface Culling 和上学期接触的 z-buffer 的逻辑很像: 在模型中, 如果有一个面被其他的面遮挡以至于在视点处根本看不到它, 那自然就没必要浪费资源渲染这个面.
实现 Backface Culling 的主要方式是 不绘制表面法线背对视平面的多边形, 判断某个多边形的表面法线是否背对视平面可以通过 计算视角方向向量和多边形表面法线向量点积的符号 实现: 如果符号为负, 说明该多边形背对观察点, 可以被舍弃, 反之则需要被渲染.
此外, 还有另一种用于判断多边形朝向的方法: 我们可以在将多边形渲染到视平面上时对 多边形边的组合方向 进行检查. 基于 “整个场景中所有多边形边的组合方向都具有一致性” 这一假设, 若某个多边形边的绕向和 “已知的, 确定是面向视平面的多边形的边绕向” 不一致, 就可以判定它是背对视平面, 需要被舍弃的多边形.
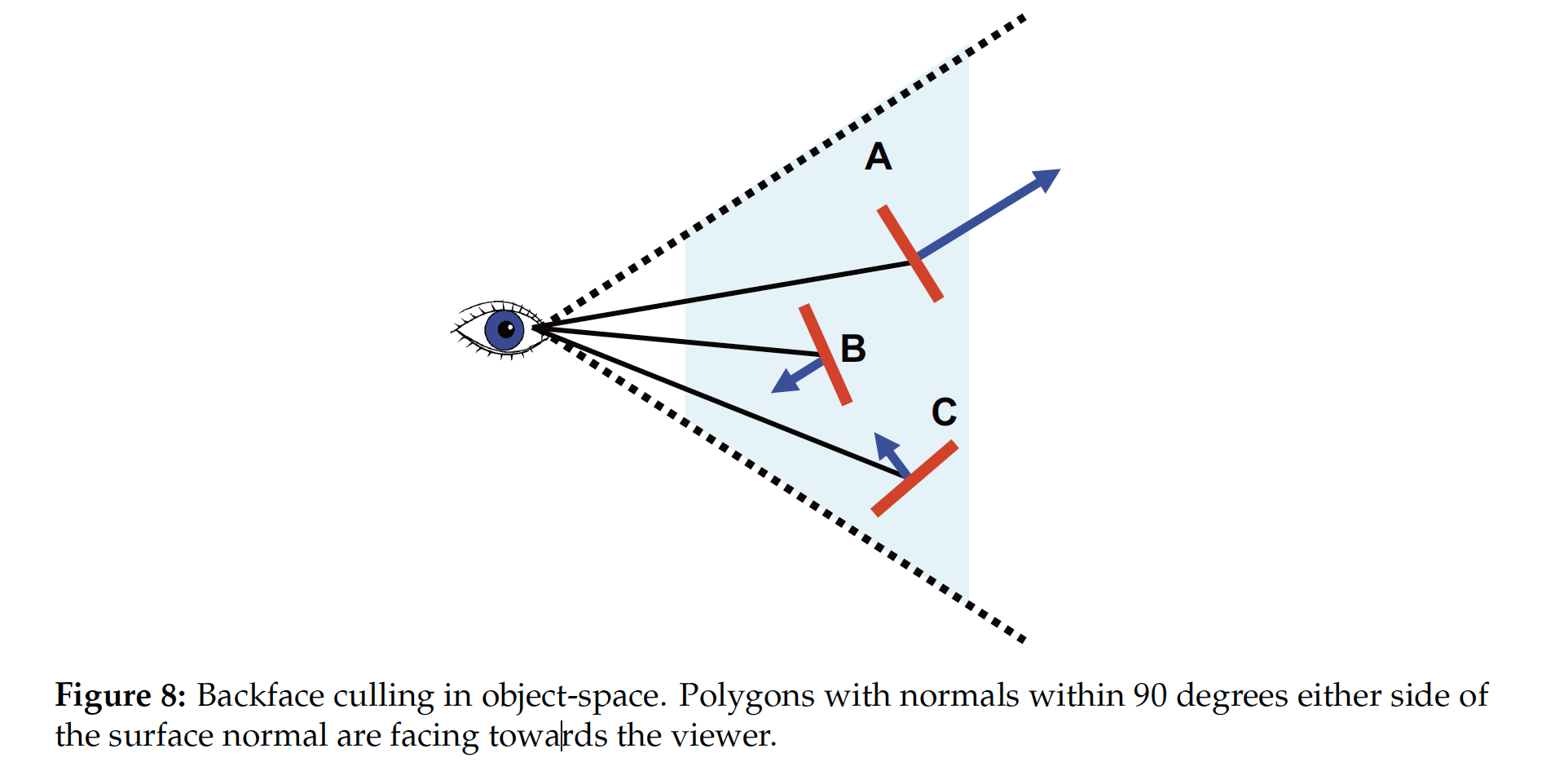
需要注意: Backface Culling 和渲染管线中的 z-buffer 不一致: 前者是在渲染前就决定 “哪些多边形需要被渲染” 的优化, 而后者是在渲染时剔除那些实际上不会被看见的多边形. 因此, 二者实际上的功能是互补的. 如果在某些情况下使用 Backface Culling 消耗的资源太多, 也可以将 “消除不可见平面” 的操作交给 z-buffer 处理.
Frustum Culling
除了剔除掉肉眼难以察觉的场景细节, 被其他面遮挡的多边形以外, 我们还可以通过剔除掉 视景体之外 的物体节约渲染资源, 因为无论如何任何位于视景体之外的东西是不可能被看见的. 若有物体横贯于视景体的边缘, 则它将被 裁切 (Clipping): 位于视景体内的部分将被保留, 而之外的部分将被直接丢弃. 在上面介绍的多种空间枚举方法就可以用于高效地确定, 哪些物体位于视景体之内/外, 或横贯于视景体的边缘.
Occlusion Culling
最后一种 Culling 技术是基于 被渲染的场景 的优化, 其基本思想是: 先于位于渲染管线末端的 z-buffer, 通过分析场景提前决定不去渲染哪些 被场景中的物体, 如墙, 门, 窗所遮挡 (Occlude) 住的部分.
对 静态 或 已经完全确定运动轨迹 的动态画面而言, 我们可以通过进行这种场景分析, 确定场景中哪些物体是 Potentionally Visible 的:

最后补充:
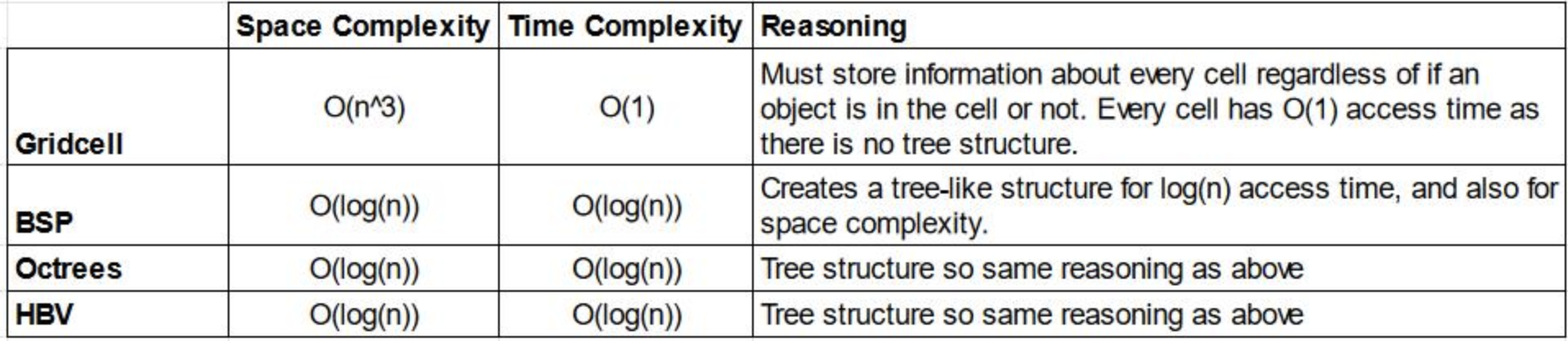
the ns in time and space complexity of these tree-shaped data structures are referring to different things:
talking about space complexity, since they are partitioning on the surface, generally the number of nodes they partitioned is \log(n), where n here is the number of objects.
talking about time complexity, the n here is different to space-complexity-case: it’s referring to the number of nodes in terms of time.
-
HBV is also useful when we need to use ray tracing or path tracing to render the scene: it can speed up the rendering process to some extent as HBV contain the information about bounding boxes so that we can quickly determine whether a ray has hit particular object or not. It can be viewed as another particular advantage of HBV.
-
When performing culling, especially occlusion culling, we can’t really avoid calculating: 1) some ray’s interaction with objects outside the viewable range if we use path tracing or ray tracing; 2) the calculation of invisible patches’ color if we use radiosity; therefore it doesn’t really speed-up the rendering process directly, but it can indeed determine “which polygons are not required to render”, thus speed up the entire rendering process.