
语音识别和语音合成问题
我们将在本章中介绍语音识别和语音合成的相关问题.
语音合成问题
首先我们讨论语音合成问题. 首先, 我们从 “人类是如何讲出语言” 这一问题开始.
人类讲出语言的过程, 可被简化为 将文字转换成发声器官肌肉运动 的过程. 本质上, 发声的过程就是使用肺部储存的空气, 通过发声器官 (Articulator) 控制和调整汽流, 产生包含语言信息的音频信号 (Speech Signal) 的过程.

语音合成 (text-to-speech synthesis) 的主要任务是, 接收文字序列作为输入, 并生成对应的音频波形.
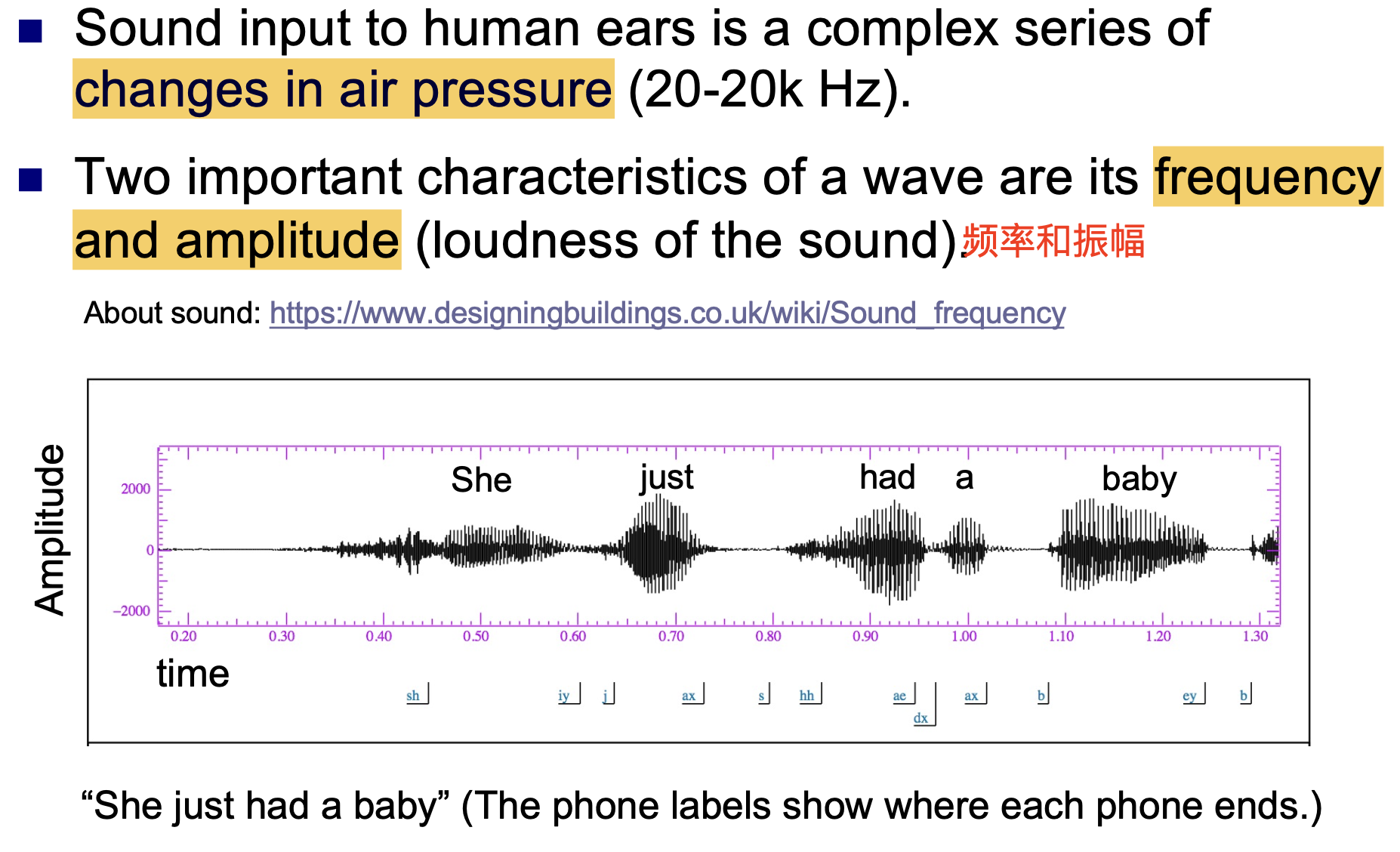
首先, 我们讨论人类可以发出和接收的声波的物理特性. 一般地, 人耳可以接受的声音频率范围在 $20-20000\text{hz}$.
人耳接受的音频输入本质是 一系列复杂的, 音压不断变化的序列, 声波的主要物理特征是 频率 (Frequency) 和 振幅 (Amplitude).
一般地, 文字-语音转换问题的流水线是一个 序列-序列映射问题, 一般包含 文字分析 (Text Analysis) 和 语音合成 (Speech Synthesis) 两部分.

文字分析问题
我们首先讨论文字分析问题.
傅立叶变换
一般地, 以音频表示的语言都是 一系列复杂的, 不同频率和振幅的声波的混合. 我们可以使用 傅立叶变换 (Fourier Transformation) 对接受的声波进行 时域/频域分离:

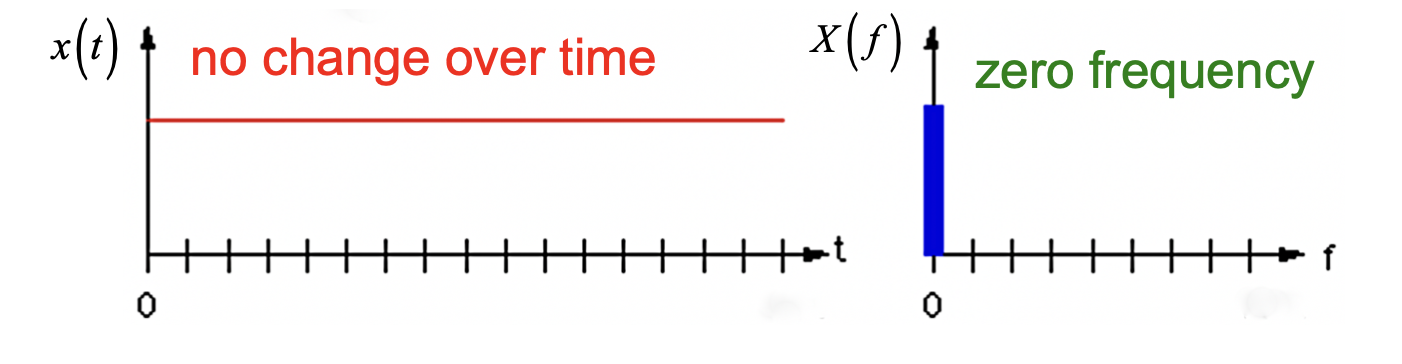
首先, 对于时域下 振幅不随时间变化 的音频信号, 它经过傅立叶转换后在频域中 位于频率横轴零点上:
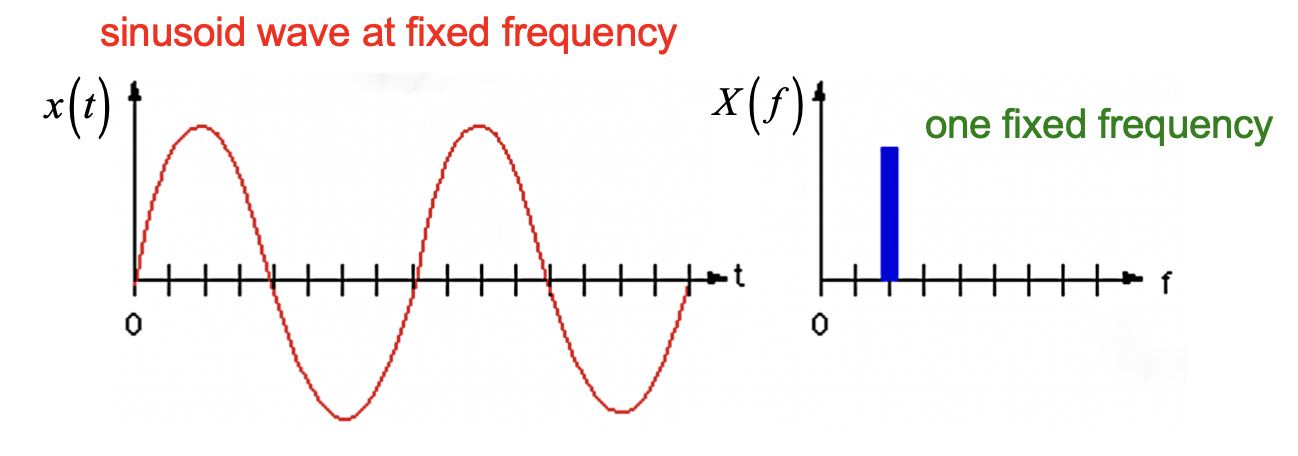
而在时域下频率不同的纯净波, 经过转换后在频率横轴上的位置也不相同:
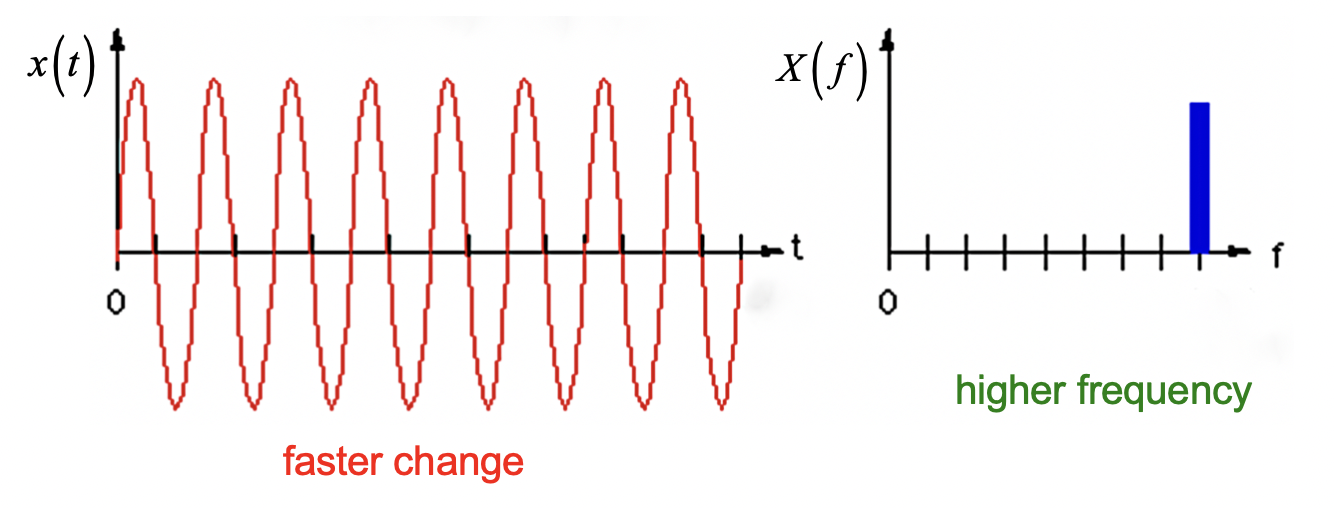
对于 周期性的方波, 经过傅立叶转换后可分离出数个不同的频率:
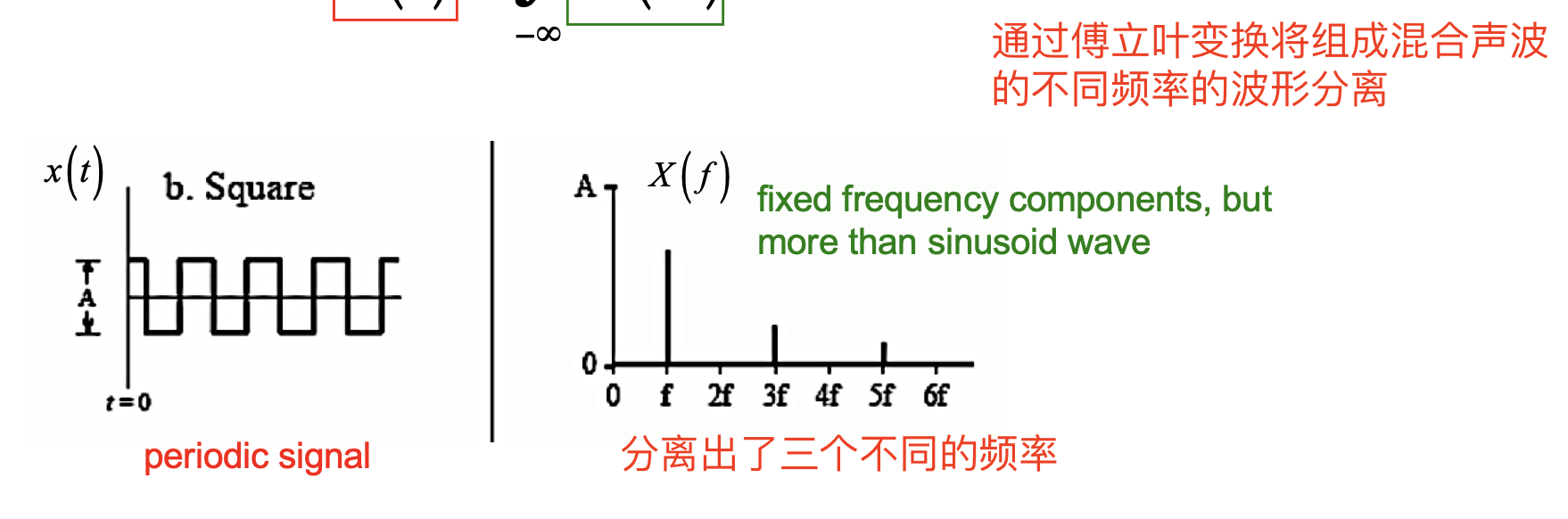
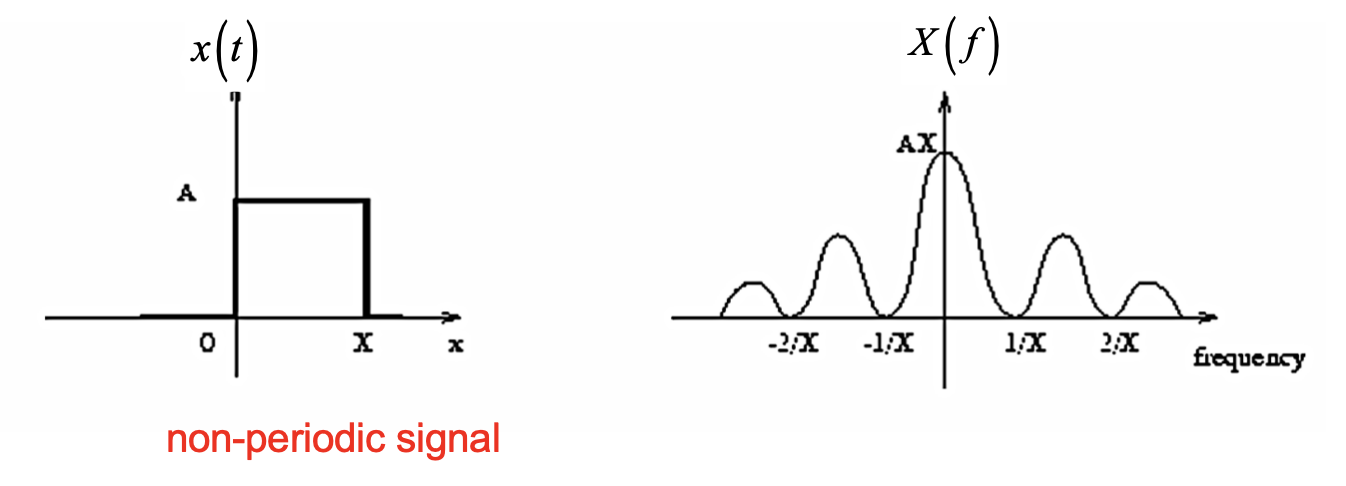
而对于 非周期性的信号, 经转换后得到的函数图像就为一条曲线:
频谱图
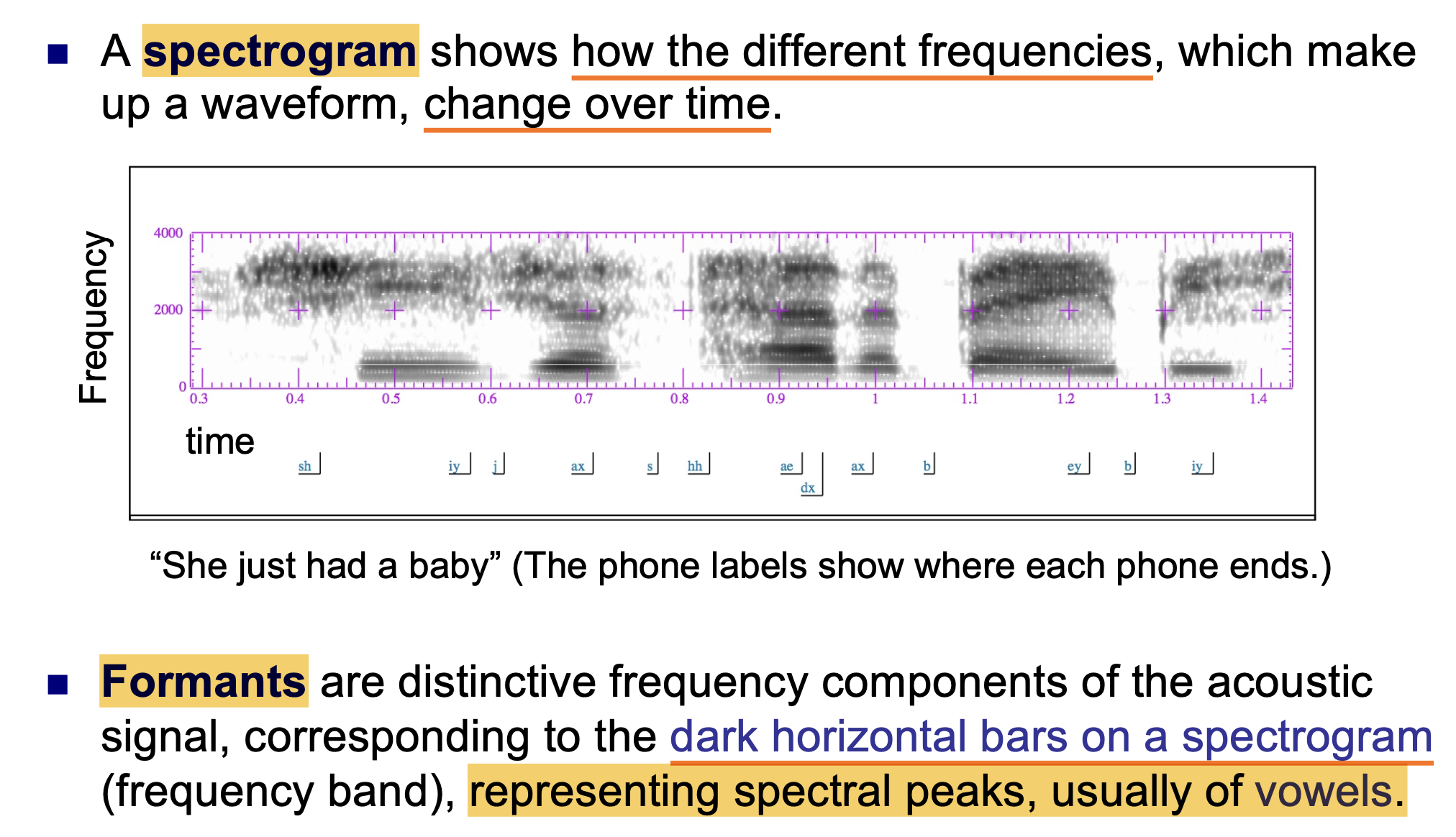
频谱图 (Spectogram) 展示了 组成某个波形的不同频率随时间的变化.
而共振峰 (Formants) 是声学信号的, 不同的 频率分量, 对应的是频谱图上的 黑色水平条, 代表 频谱峰值, 而这些频谱峰值一般都是 元音 的.
音 (Phones)
音素 (Phoneme) 是辨别不同声音的最小单位, 而 音 (Phone) 是音素的具体实现 (phonetic realization). 或者, 也可以将 Phoneme 视为 phones 的一般形式或抽象形式 (Generalization | Abstraction).
Phone 一般分为 元音 (Voewls) 和 辅音 (Consonants).
辅音和元音的组合形成了 音节 (Syllable), 发音语言学 (Articulatory Phonetics) 所研究的领域是 音是如何产生的.

辅音
辅音是通过 限制或阻碍气流 发出的, 以 发音时在口中以何种方式阻挡气流发声 而实现分类. 英语中主要的辅音类型包括 stop(plosives), nasals, fricative, approximant 和 tap:

元音
相比于辅音, 元音一般都是实际发声 (Voiced) 的, 在发声过程中对气流的阻碍也更小, 一般持续时间更长且更为响亮.
元音是基于 发声时舌头在口腔中的位置 分类的, 不同的元音的共振峰和特征位置 (?) 都不相同:

音素 (Phonemes)
音素在不同的语境下有不同的实现形式, 给定音素的, 所有不同的音组成的集合被称为 音位变体 (Allophone).

任何语言的音素数量都是 有限 的, 一般在 $40-60$ 个之间. 下面考虑最简单的文字转语音方法: 发音字典.
字素-音素转换问题
字素-音素转换问题 (Graphemes to Phonemes) 的主要目标是找出给定的, 已知文字形式的单词的 发音.
字素和音素分别是书写格式语言和口语格式语言的最小组成单位.
本质上, 它将 由一系列符号或字素组成的单词 转换为 一系列音素的特定发音. 一般地, 我们可以使用 发音字典, 结合发音规则的发音字典 和 基于数据驱动的机器学习方法 解决这一问题:

发音字典 Pronunciation Dictionary
发音字典是最简单的文字转语音技术, 其实现方式时 预先记录大量的单词发音, 然后在需要时将它们 拼接起来 构成用于输出的音频信号.

发音字典具备明显的局限性:

因此为了适应不同的使用场景和需求, 我们需要考虑更先进的文字转语音技术.
基于规则的文字-语音转换
受语言学的启发, 我们注意到单词的 形态学变换 (Morphophonological Rules) 可以描述和不同形态的前缀或后缀组合后得到的单词的发音, 而特定字母一般也只具有固定的发音, 因此我们可以使用 Letter-to-Sound Rule 描述一系列字母的组合得到的单词发音应该是什么.
更一般地, 我们可以使用一套 语音规则 (Phonological Rule) 描述不同音位和它的音位变体之间的关系:

举例而言, 相同的单词在不同的语境下具有不同的发音:

一般地, 我们称 韵律 (Prosody) 为对句子进行发音时的一些无法被音素序列刻画的特征, 一般由 语气 (Tune), 强调 (重读音和口音 Prominbebce) 以及 句子结构 (Structure).

通过调节音频的 强度 (Intensity), 持续时长 (Duration) 和 音高 (Pitch), 就可以调节韵律.
在对句子进行发音时, 可建模 语气 (Tune) 和 句子结构 相关的规则:

自然, 我们还可以建模 重音的规则:

在推断出规则后, 我们就可以将这套规则和 发音词典结合:

基于机器学习方法的文字-语音转换
一般地, 字素-音素问题可被视为 序列-序列映射学习 任务. 使用相关的数据处理和模型训练方法即可解决.
语音合成问题
下面我们继续讨论语音合成问题.
语音合成器接收一系列语言分析器输出的 音素序列, 基于这个音素序列中所存储的, 每个音素的 特定音高和特定时长 (Duration & Pitch), 输出具体的音频.
解决语音合成问题的基本方法分为下面三类:

拼接语音合成 (Concatenative Speech Synthesis)
拼接语音合成的核心思想是: 将预先存储的 发音块 (Speech Chunks) 基于音素序列简单拼接. 它依赖于一个一般存储双音素的, 足够大的发音数据库:

对发音块的拼接方式有两种: Fixed Inventory 和 Unit Selection:

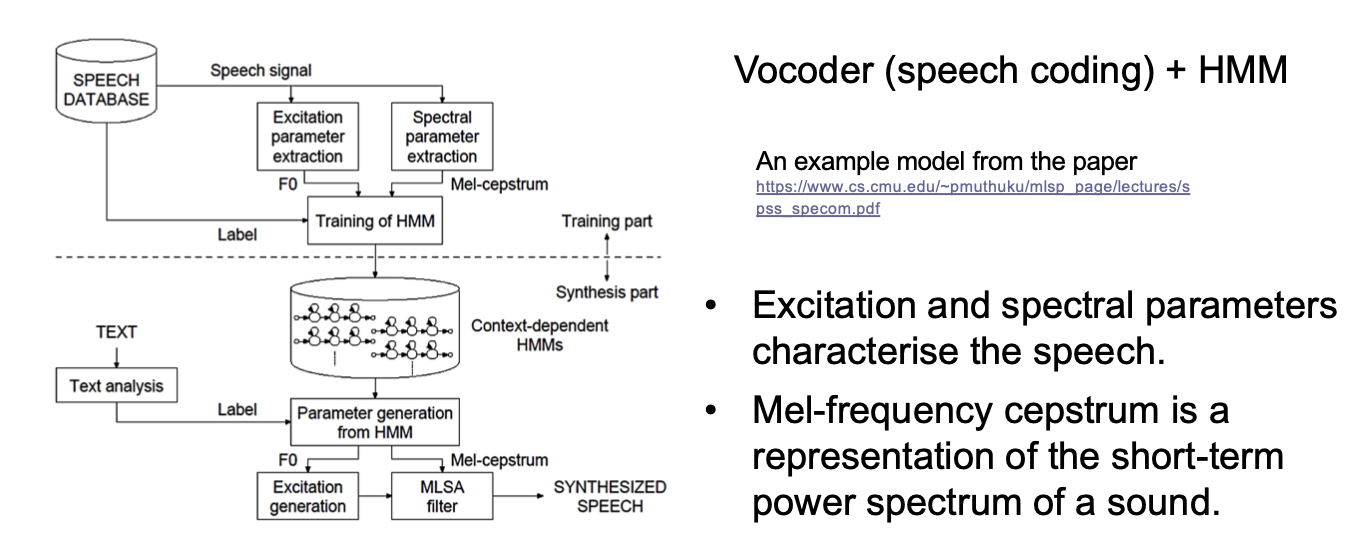
基于统计参数的语音合成 (Statistical Parametric Speech Synthesis)
基于统计参数的语音合成将 所有决定音频数据生成的信息 都作为 音频合成模型的参数, 从而通过 模型的输入参数 调整模型输出的内容和韵律.
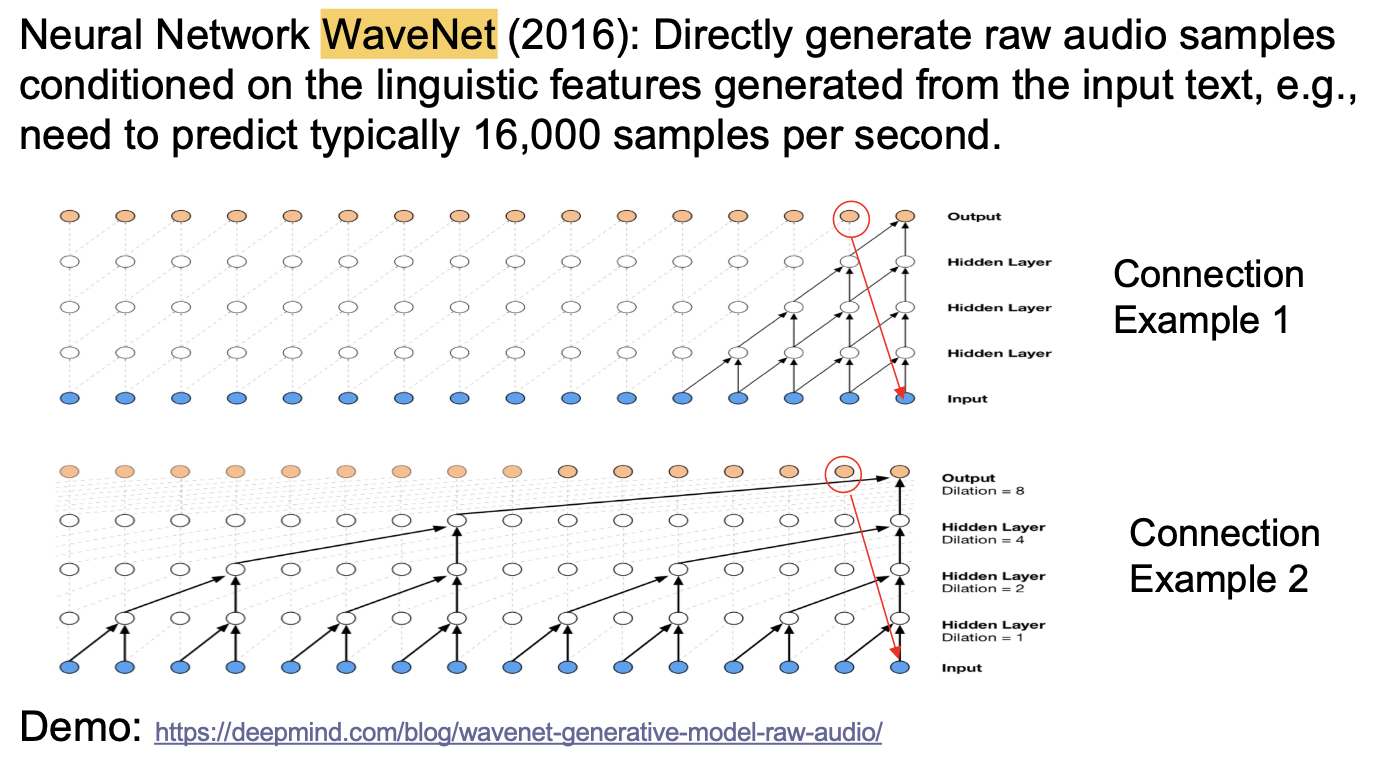
基于神经网络的语音合成 (Neural Network For Speech Synthesis)
基于神经网络的语音合成使用一系列直接获取的音频采样和它们对应的语言学特征作为模型的训练数据, 所训练出的神经网络是 端到端 的: 可以直接基于给定的语言学信息生成对应的音频.
语音识别问题
在本节中, 我们将依次介绍 语音合成问题的基础知识和定义, 典型语音合成系统的架构 和 语音特征提取与解码问题.
基础定义和知识
一般地, 称 语音识别 (Speech Recognition) 为研究如何 将口语使用计算机转换为文字 的问题领域, 其可细分为:
-
自动语音识别问题 (
ASR): -
计算机语音识别问题
-
语音转文字问题 (
STT)
其中我们主要关注自动语音识别问题. 自动语音识别将语音数据中的 声学信息 转换为 (一般以 词串 (Word Strings) 为形式的) 底层语言结构. 其输入为 连续的语音波形, 输出为 由一个或多个符号组成的序列, 其目标是构造关于输入和输出之间的有效映射.
自动语音识别问题的主要难点是: 无法直接使用 Pronunciation Dictionary. 这是因为作为输入的语音波形 并不是一系列恒定模式的简单链接: 不同的单词可能具有相同或相似的发音 (如 fuck 和 phoque), 而相同的符号在不同的环境场合下的发音也不尽相同; 符号之间的界限也更加难以从波形中确定.

语音合成系统的基本架构
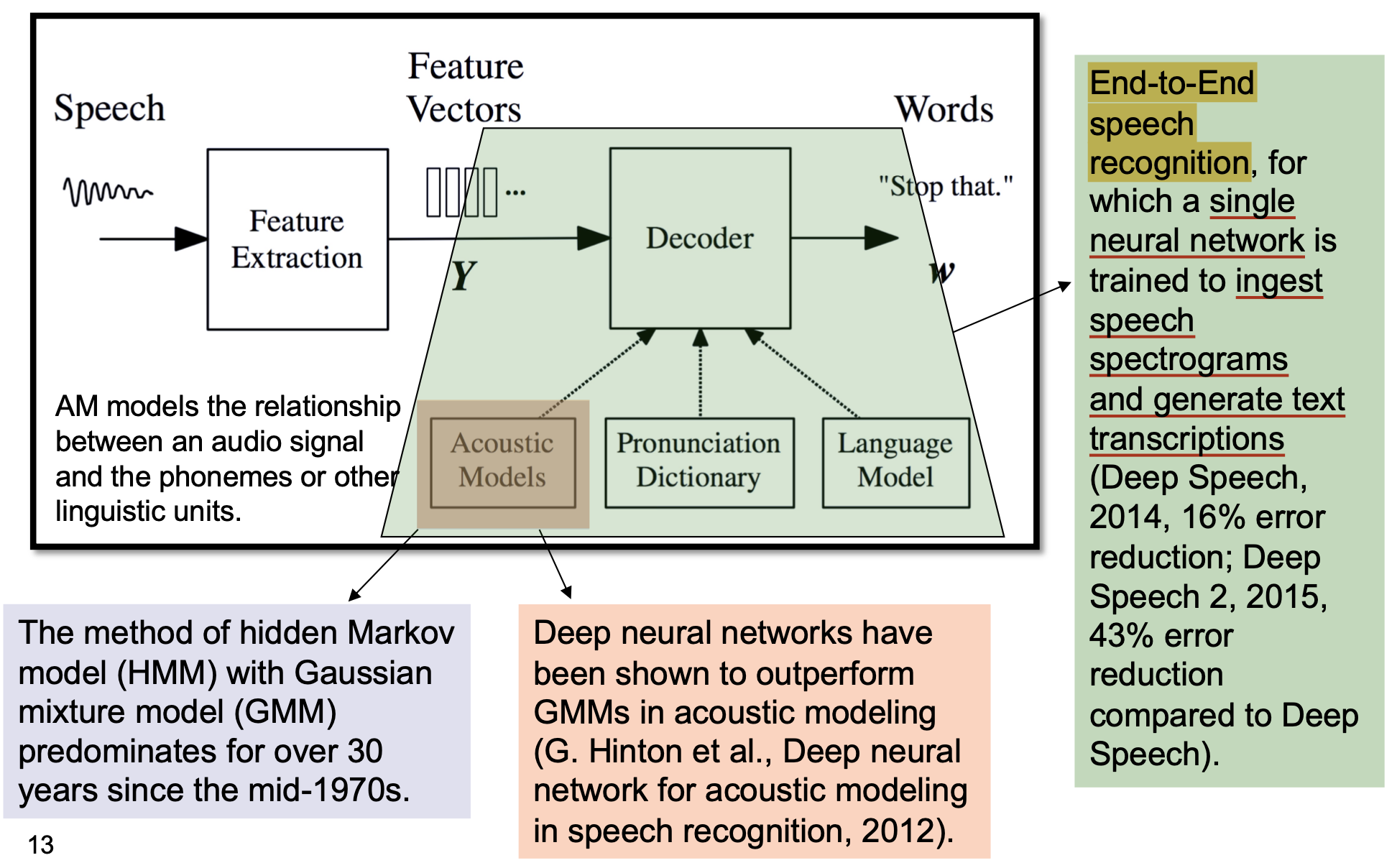
下图展示了语音合成系统的基本架构. 语音波形通过 特征提取 后被转换为 特征向量, 随后传入 解码器 中, 在 声学模型, 发音词典 和 语言模型 的支持下被进一步解码为 文字.
其中, 隐马尔可夫模型 和 高斯混合模型 是神经网络被广泛应用与自然语言处理领域前, 效果最好的声学模型. 而神经网络的表现显著超越了高斯混合模型, 如今 构造和训练单独的神经网络, 以识别语音频谱并直接转换文字 的 端到端方法 称为主流.
语音特征提取问题
我们下面讨论语音特征的提取问题.
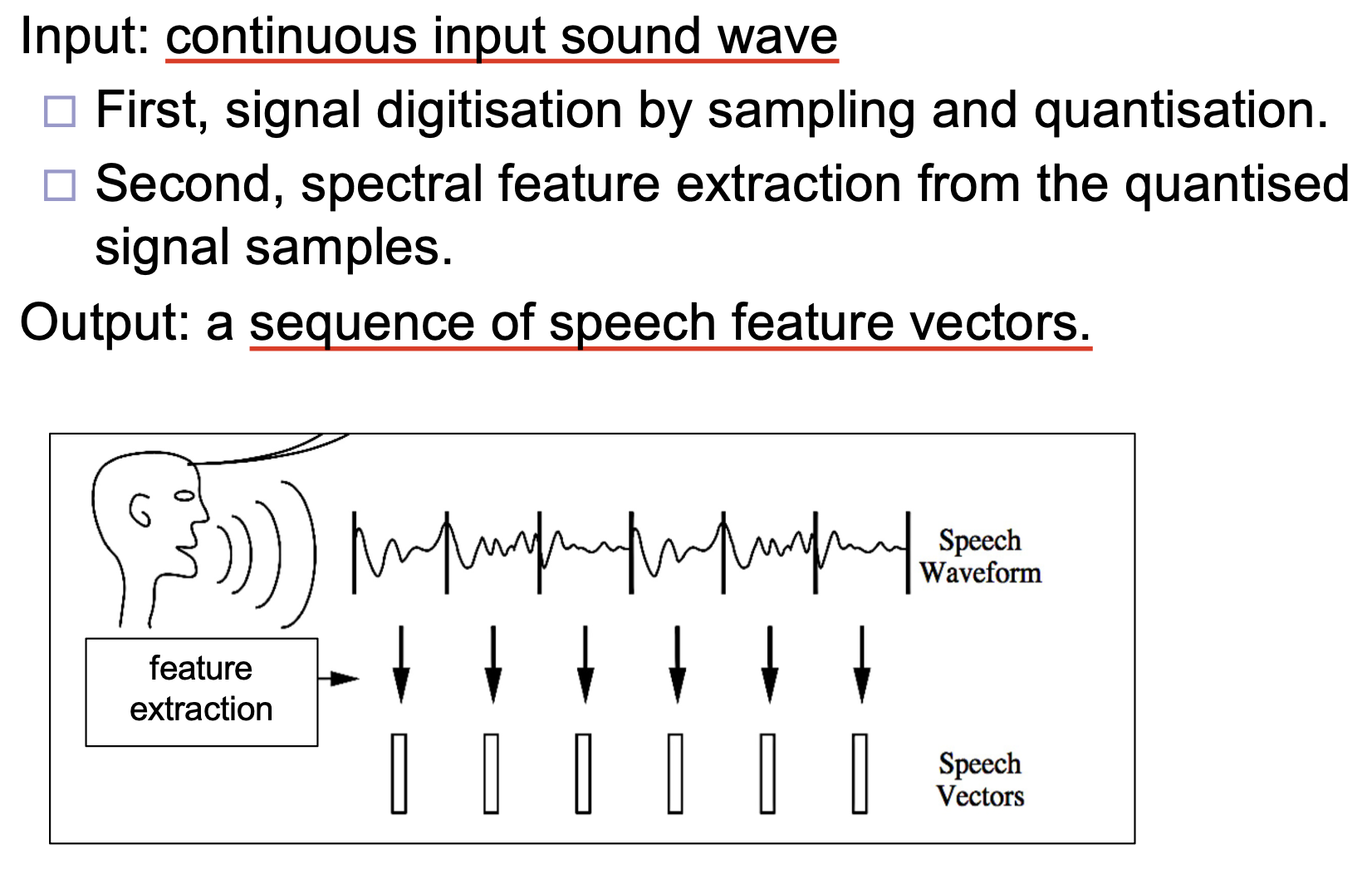
语音特征的提取发生在第一步中, 其输入为 连续的声波, 输入在被 数字化采样 和执行 频谱特征提取 后, 最终被转换为一系列 声学特征向量 并输出.
数字化采样
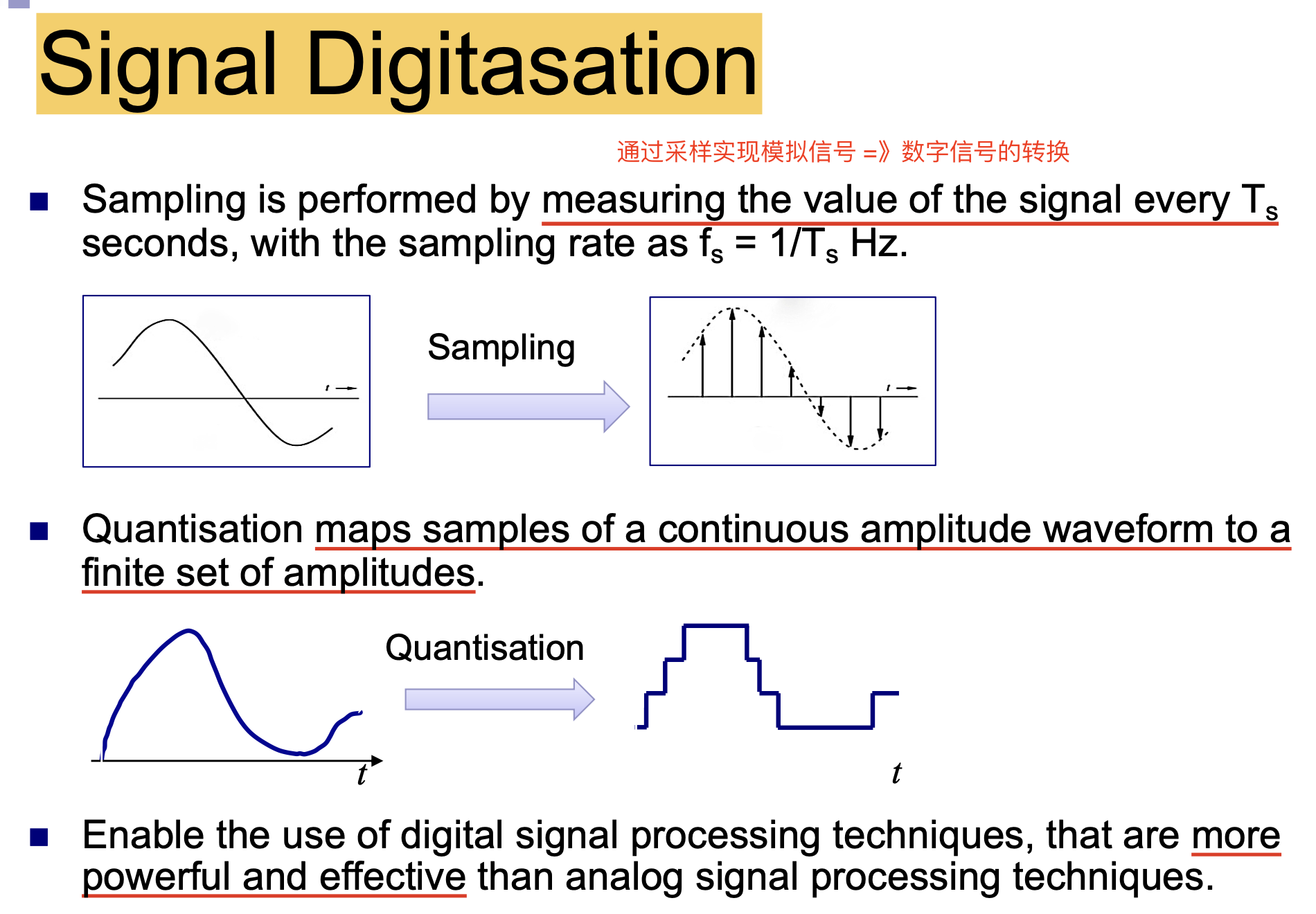
作为输入的声波是 连续 的, 对这种模拟信号需要执行 数字化采样 才能被更好地存储和分析. 对声波的数字化采样是通过 设定采样率, 以 恒定的时间间隔 $T_s$ 对声波周期性采样 得到的. 如下图所示, 经过采样后, 连续的波形被转换为离散的数字信号 (方波), 这一过程称为 量化 (Quantisation), 它将连续振幅波形的样本映射到一组 数量有限的振幅 上, 便于后续的进一步处理.
频谱特征提取
一般地, 我们使用 梅尔频率倒谱系数 (Mel-frequency cepstral coefficient) 进行频谱特征提取.
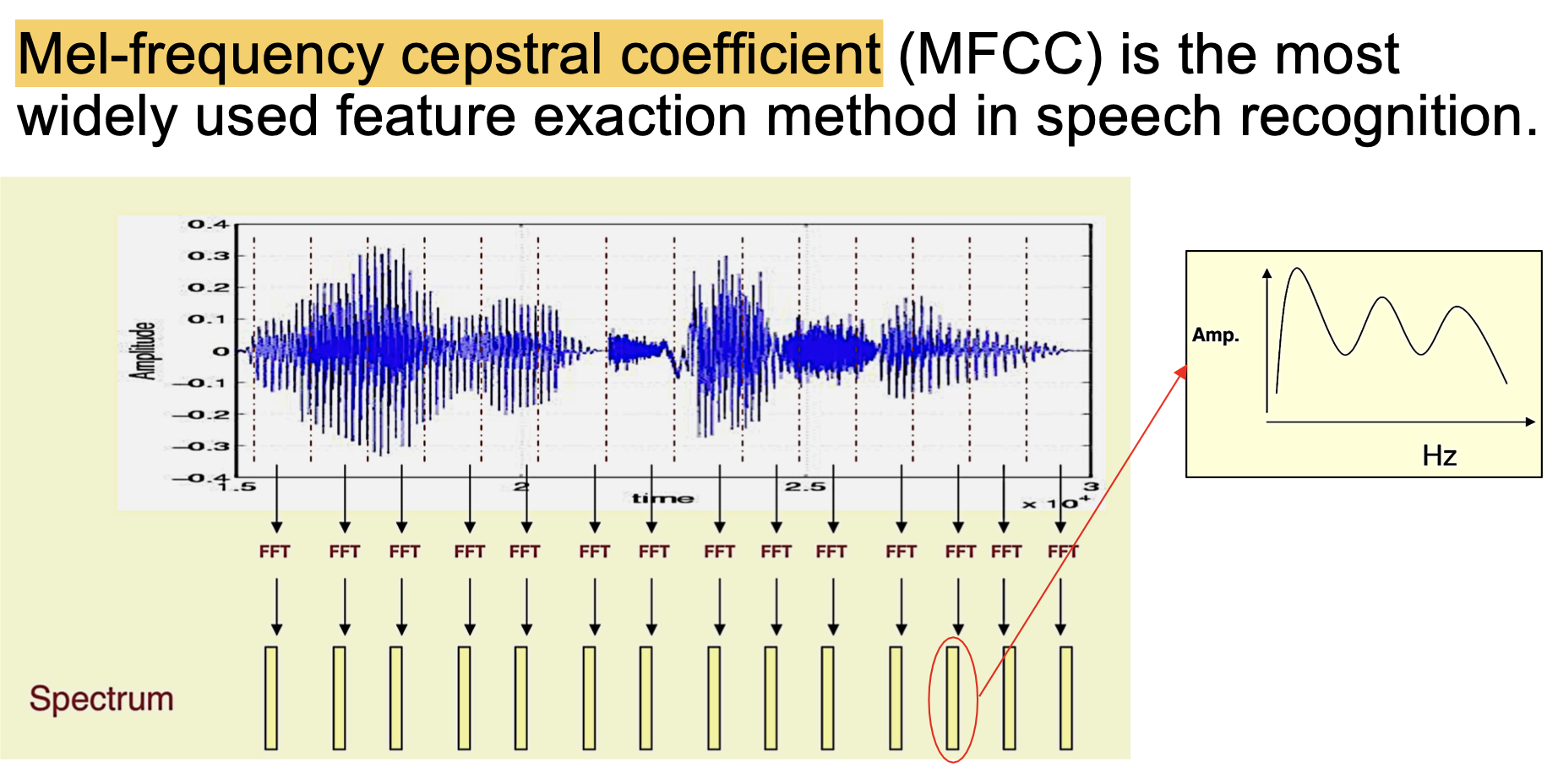
语音特征解码问题
在完成语音特征提取后, 我们将连续的语音波形转换为了一系列特征向量. 下一步, 需要对这些特征向量进行解码, 从而得到可读的字词.
在解码中, 我们解决问题的基本思想基于 概率.
给定一系列特征向量, 首先需要考虑它所能代表的 所有可能的句子. 其次, 对每个可能的句子, 都需要计算出 由这个句子, 最终生成和输入完全一致的特征向量序列的概率. 最后, 选择概率最高的句子, 作为对应的结果.

自然, 进一步地我们就需要考虑 如何量化所谓的 best match. 此处, 我们考虑的量化方式是 基于概率的测度 (Probability Measure).
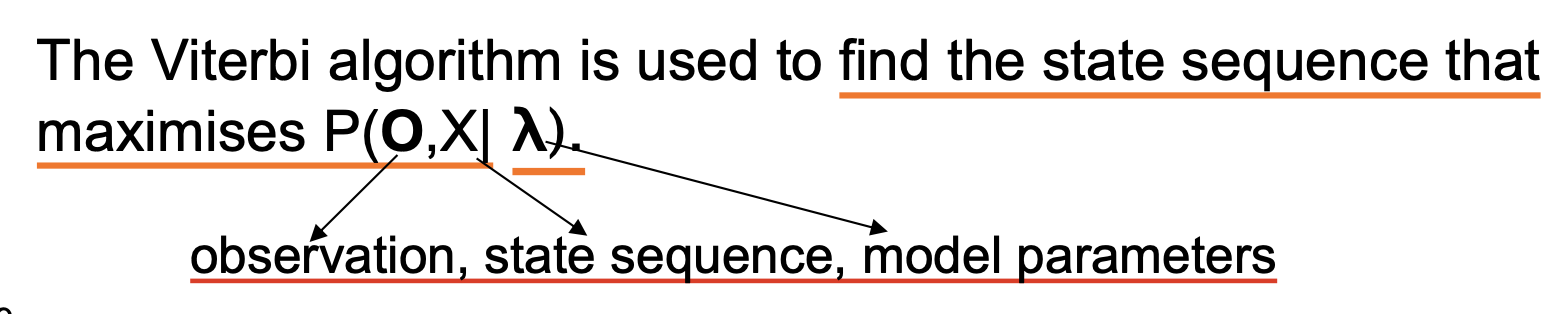
同时, 对几乎包含无数个句子的自然语言进行穷尽搜索显然也是不可能的, 因此同样需要构造某个 足够高效的算法, 使其 无需穷尽搜索一切可能得到特定的特征向量序列的句子, 而只考虑那些 几率大的句子. 本章考虑 维特比算法 (Viterbi Algorithm), 但动态规划也是可行的解决方案之一.

基于概率的映射
基于概率的映射要求我们分别对 口语句子 (Spoken Sentence) 和 候选句子 (Candidate Sentence) 进行合理的表示.
一般地, 我们将口语句子表示为 口语向量链 (Sequence of Speech Vector):
其中, $T$ 表示考虑的 signal segment 的个数; 而将候选句子表示为字词符号串:
进而在这种表示方式下, 最优匹配句子就是:

也就是 观察到口语句子 $O$, 它实际上对应字词符号 $W$ 的 后验概率 (Posterior Probability) 中 最大的概率 所对应的句子.
通过进一步使用 Bayes Rule 就可将后验概率拆解.
拆解得到的式子中, $P(W)$ 一般使用 语言模型或字典计算, 表示 这个句子本身的合理程度, 概率越高说明这个句子越有可能在现实中出现, 符合语法和使用习惯.
$P(O \vert W)$ 是句子 $W$ 关于口语句子 $O$ 的 似然值, 一般使用 声学模型 (Acoustic Model) 计算.
最后, $P(O)$ 是 生成口语句子 $O$ 的概率. 事实上, 这一概率难以计算, 但由于在选择候选句时 无需计算这个概率值, 因此它并不构成语音识别系统中的实现障碍.
由此可见, 对似然值 $P(O \vert W)$ 的计算在剩下的任务中是相对最难的. 下面我们介绍多种声学模型, 并讨论如何对它进行计算.
孤立词识别
在介绍声学模型前, 我们首先观察一个最简单的语音识别问题: 孤立词识别 (Isolated Word Recognition).
在这个例子中, 作为被匹配项的 “候选句子” 实际上都 只由一个词组成, 因此模型在接收输入的口语序列后, 只需从单词表 (Vocabulary) 中找出 一个最合适的词 即可.

隐马尔可夫声学模型
下面介绍一种非常重要的声学模型: 隐马尔可夫模型.
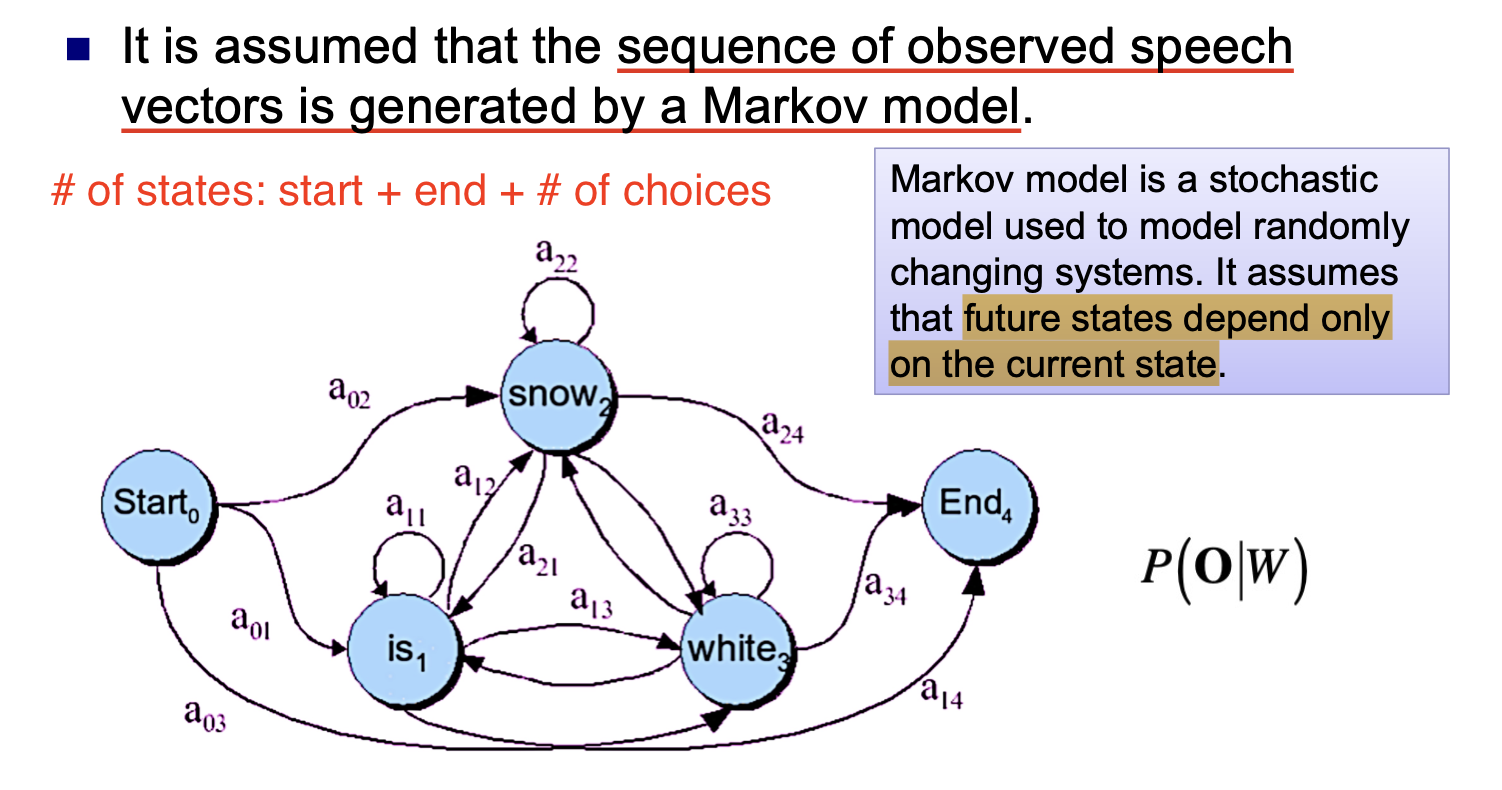
从上面一小节可知, 给定口语序列 $O$ 和某个文字序列 $W$, 声学模型需要计算出 $P(O \vert W)$. 而马尔可夫模型对这个似然值的计算基于假设: 任何 future state 都由 current state 所决定.
我们用一个简单的例子说明隐马尔可夫模型的能力. 在下面的例子中, 除了 start 和 end 两个状态外, vocabulary 中包含了三个单词, 因此该隐马尔可夫模型需要考虑 $5$ 种可能的状态 (state).
而该模型的基本功能就是, 计算出 vocabulary 中三个单词 可重复的, 不同顺序的排列组合 (也即是考虑用这三个单词所能够构造出的所有句子 $W$), 并分别计算口语序列 $O$ 关于它们的每个似然值.
下面是隐马尔可夫模型的一般架构. 口语序列 $O$ 在经过特征提取后会被拆分为多个特征向量, 而每个特征向量经过马尔可夫模型计算后都会被赋予某个单词表中的词.
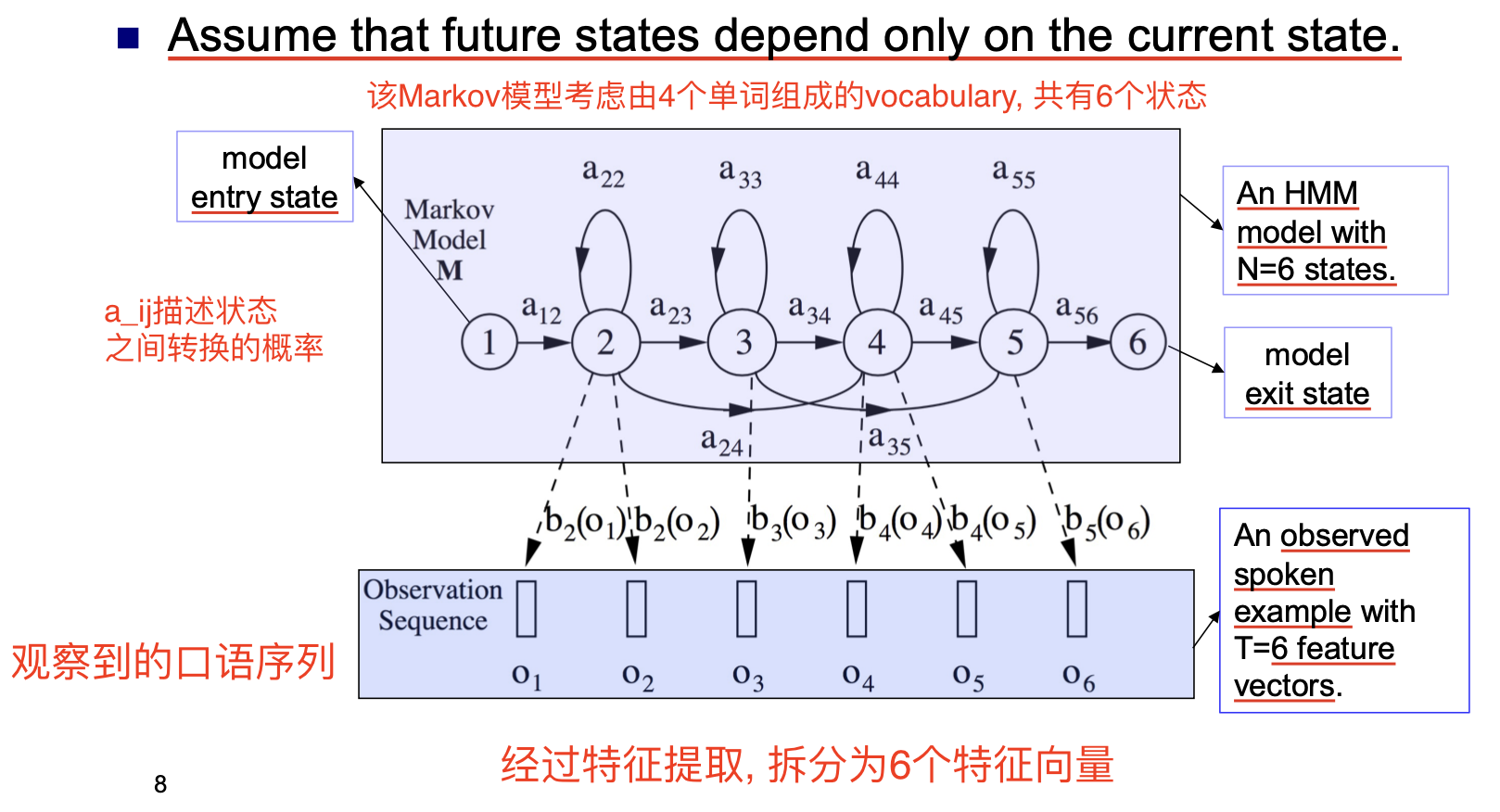
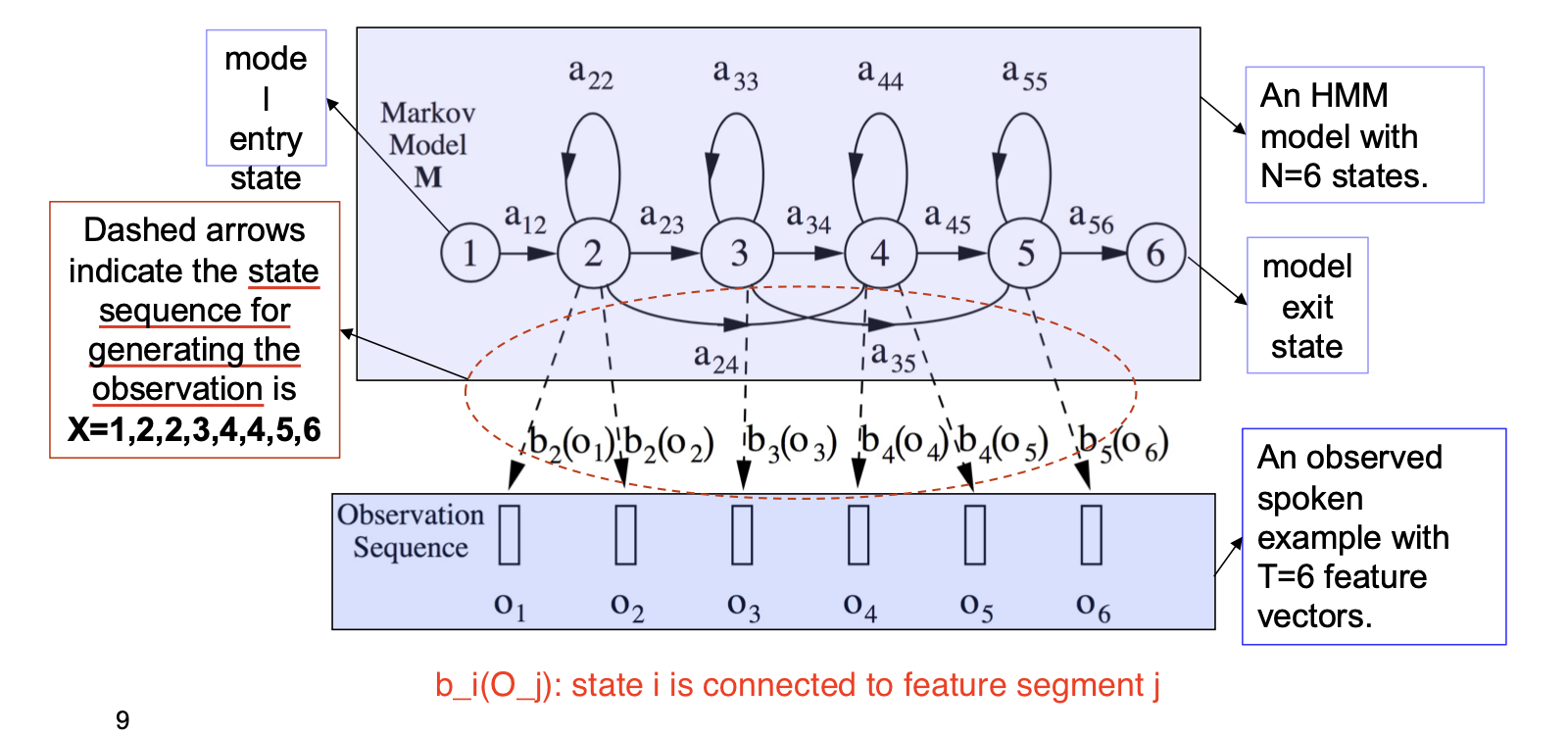
在构造隐马尔可夫模型时, 状态之间转换的概率至关重要.
一般而言, 认为状态之间的转换概率是由语言模型 直接给定 的, 因此任务就变成了对 似然 $b_j()$ 的计算.
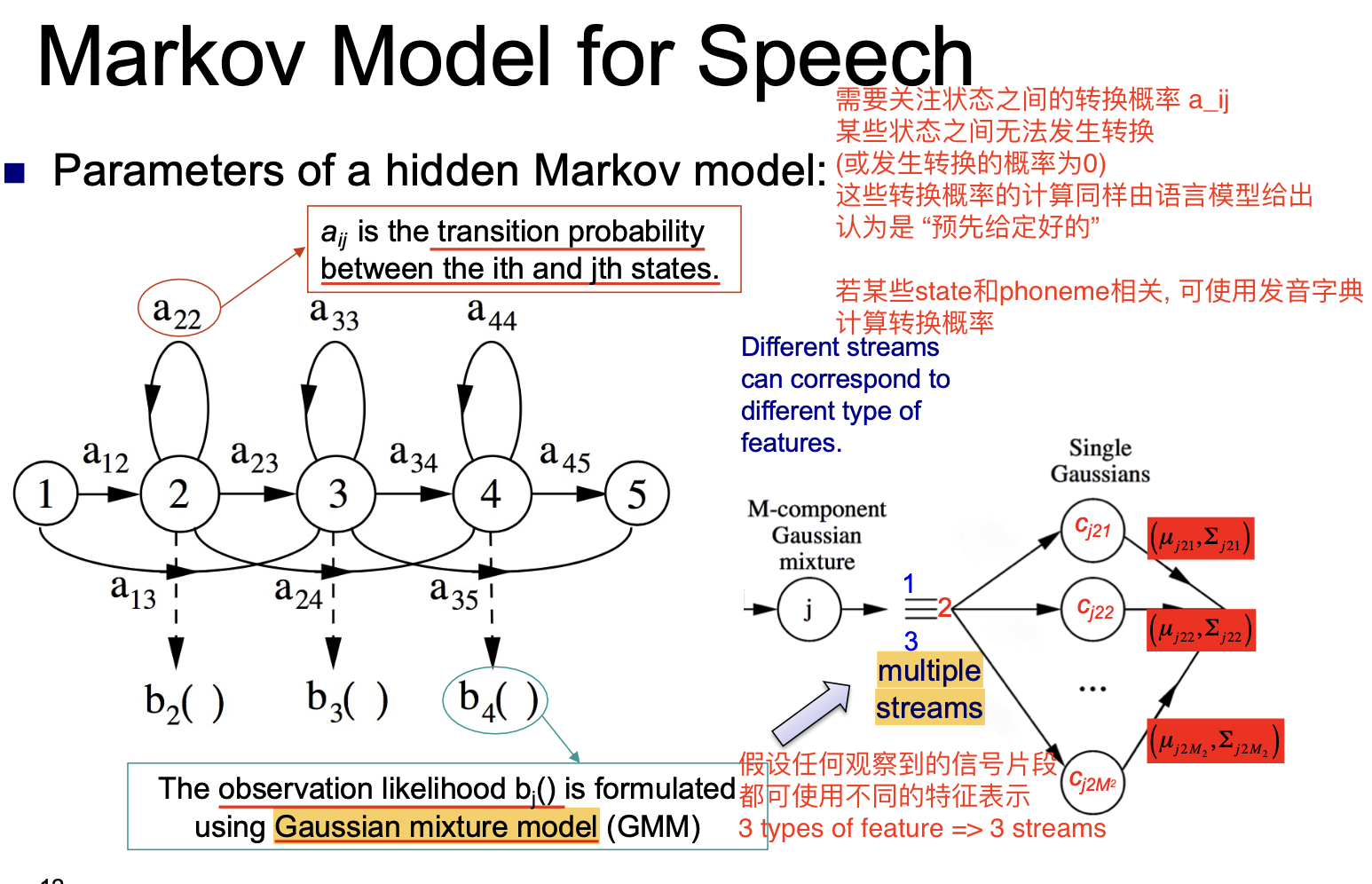
高斯混合模型允许我们对任何观察到的信号片段混合使用多种不同的特征表示. 对给定的信号片段, 表示它的每一个特征都对应一个 stream.
对每个 stream, 在计算 由这个 stream 可以生成指定特征向量的期望 时, 就可使用高斯混合模型. 在选择不同的 Single gaussian 后将其表示 (均值向量 $\mu$ 和协方差矩阵 $\Sigma$) 混合, 就可得到对应的期望值. (此处没懂, 下次去问)
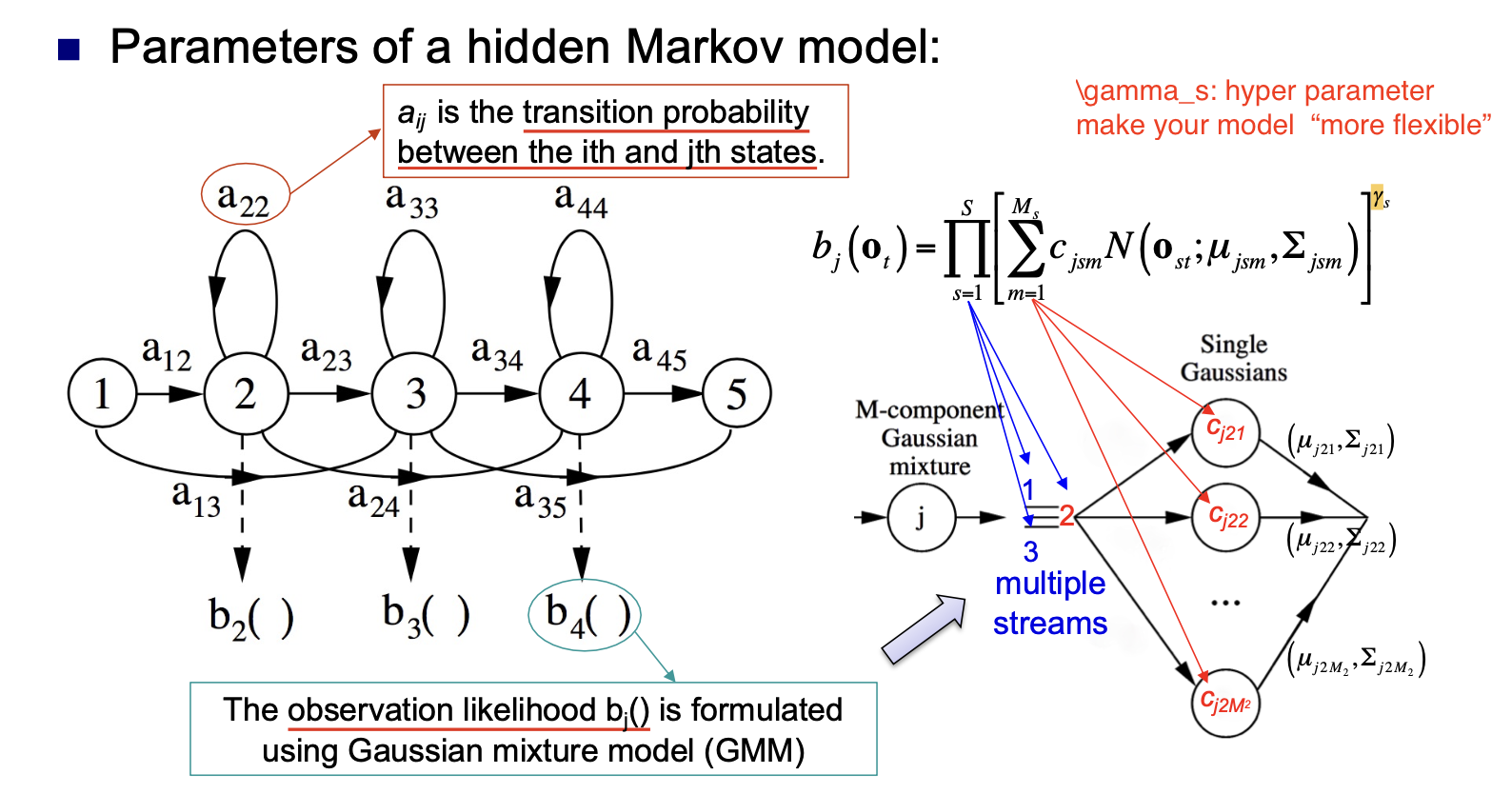
因此, 隐马尔可夫模型的全部参数可被总结如下:

随后讨论对隐马尔可夫模型的训练问题.
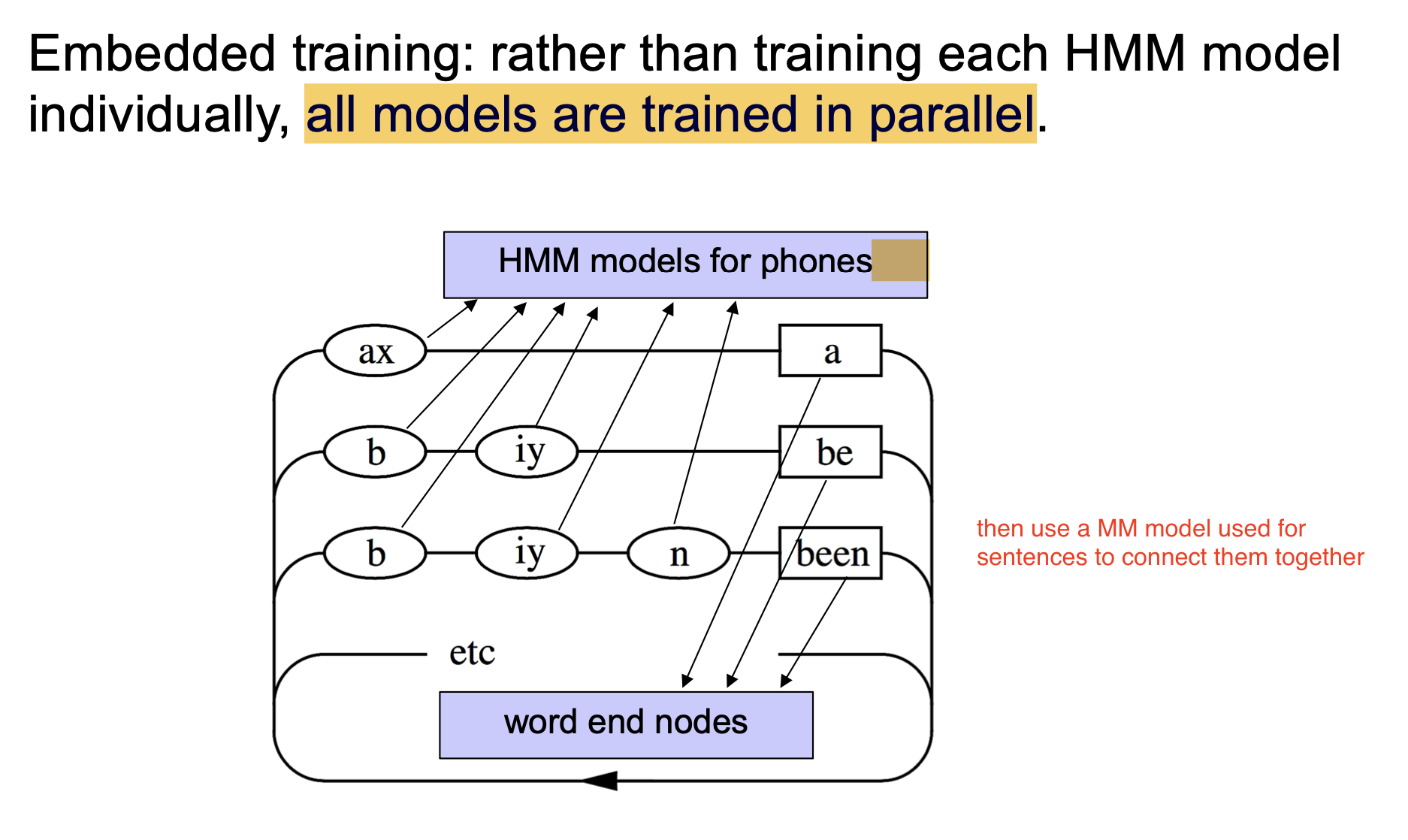
考虑简单的 孤立词识别 问题, 隐马尔可夫模型是关于 每个单词表中的词 训练得到的, 因此单词表里有多少个词, 就有多少个隐马尔可夫模型, 模型中的每个状态对应一个音素, 音素的组合就可得到对应的词. 在训练时, 需要提供 多个该单词的采样.

连续语音识别 Continuous Speech Recognition
下面讨论更复杂的语音识别问题: 连续语音识别.
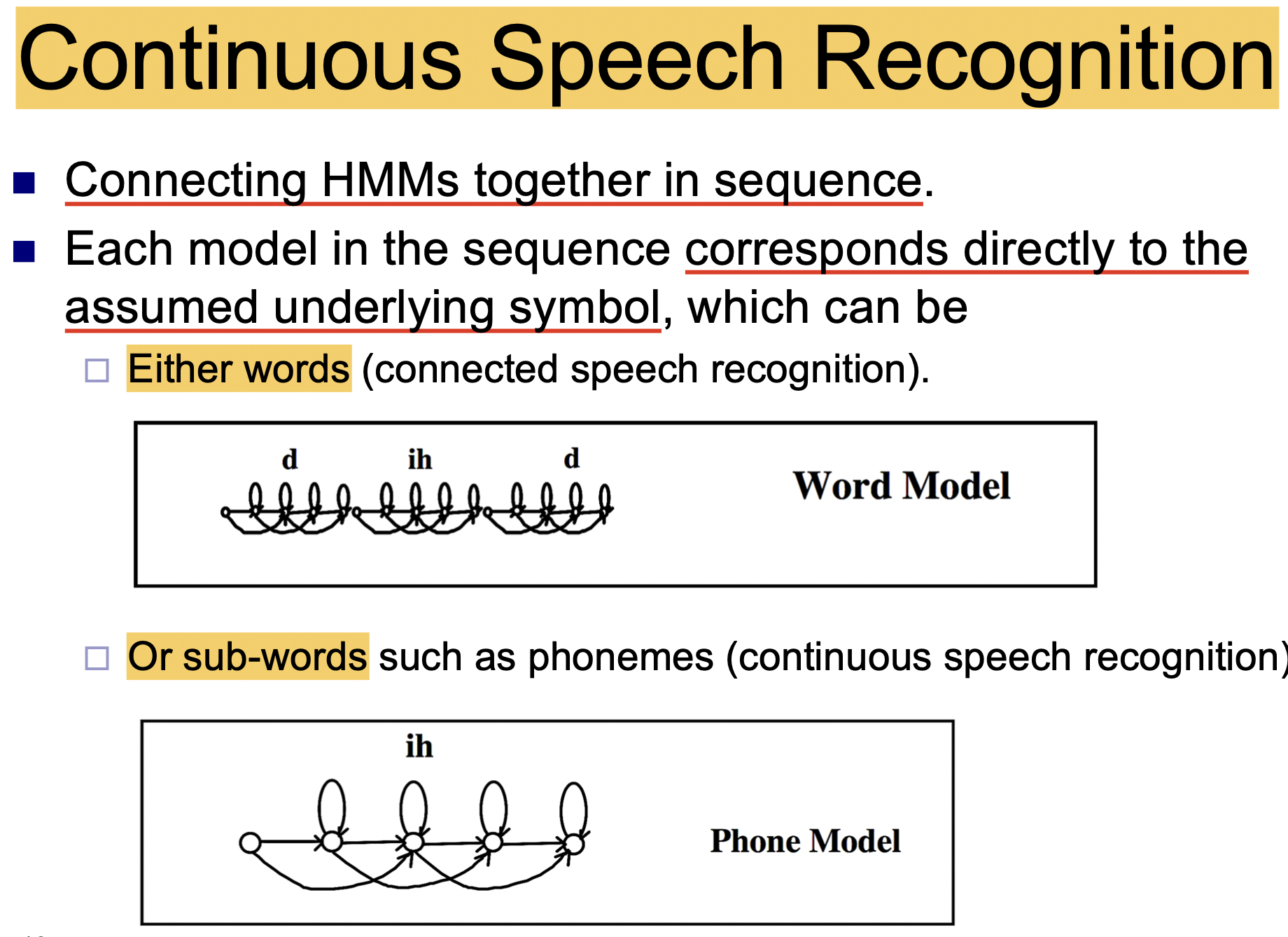
连续语音识别需要解决的问题是将音频信号转换为 某个或多个句子, 而非单个词组.
解决这一问题的方法是: 关于每个可能的文字符号 (单词或音素), 都构建相应的隐马尔可夫模型, 然后将得到的一系列马尔可夫模型 连接在一起, 确定给定的音频信号中在什么位置对应什么文字符号, 从而将音频信号转换为完整的句子.
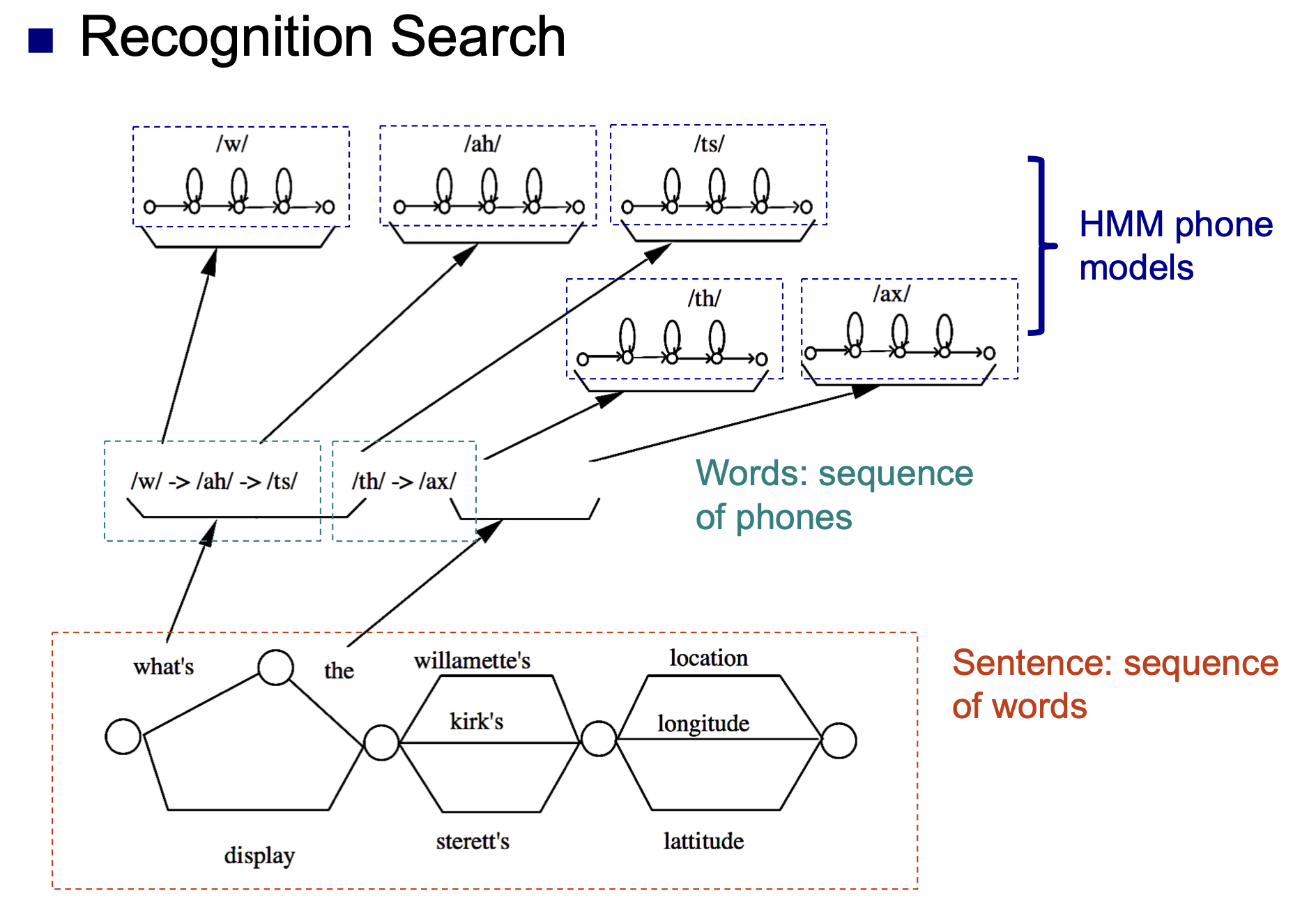
语音识别和维特比解码
在完成模型的训练后, 我们可根据模型计算得出每个候选状态序列对应的似然值.
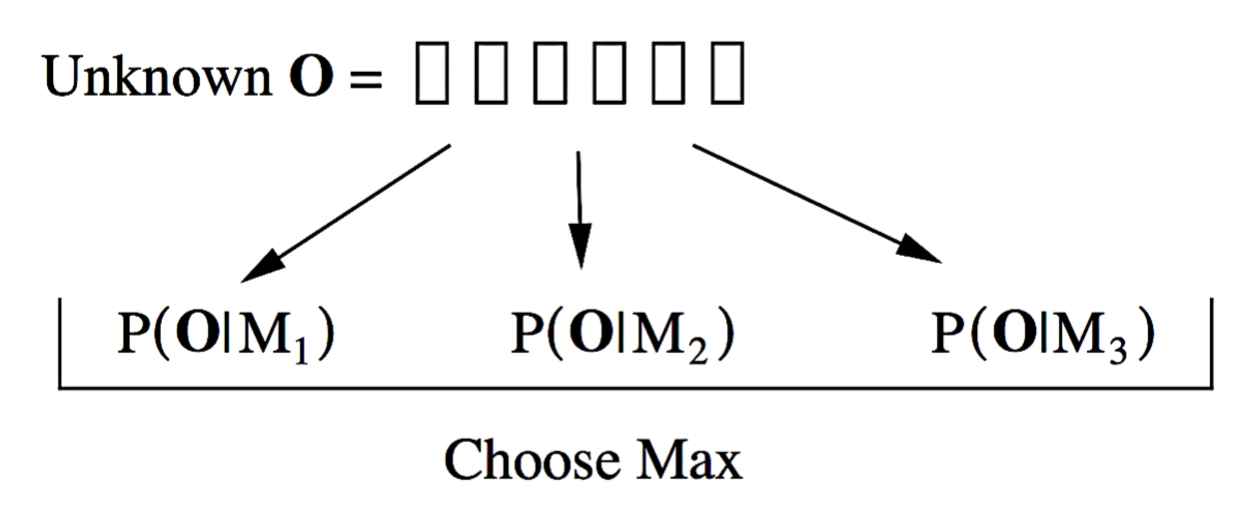
而 维特比算法 (Viterbi Algorithm) 就是用来寻找可以最大化
的状态序列的算法. 对式子中符号的解释如下:
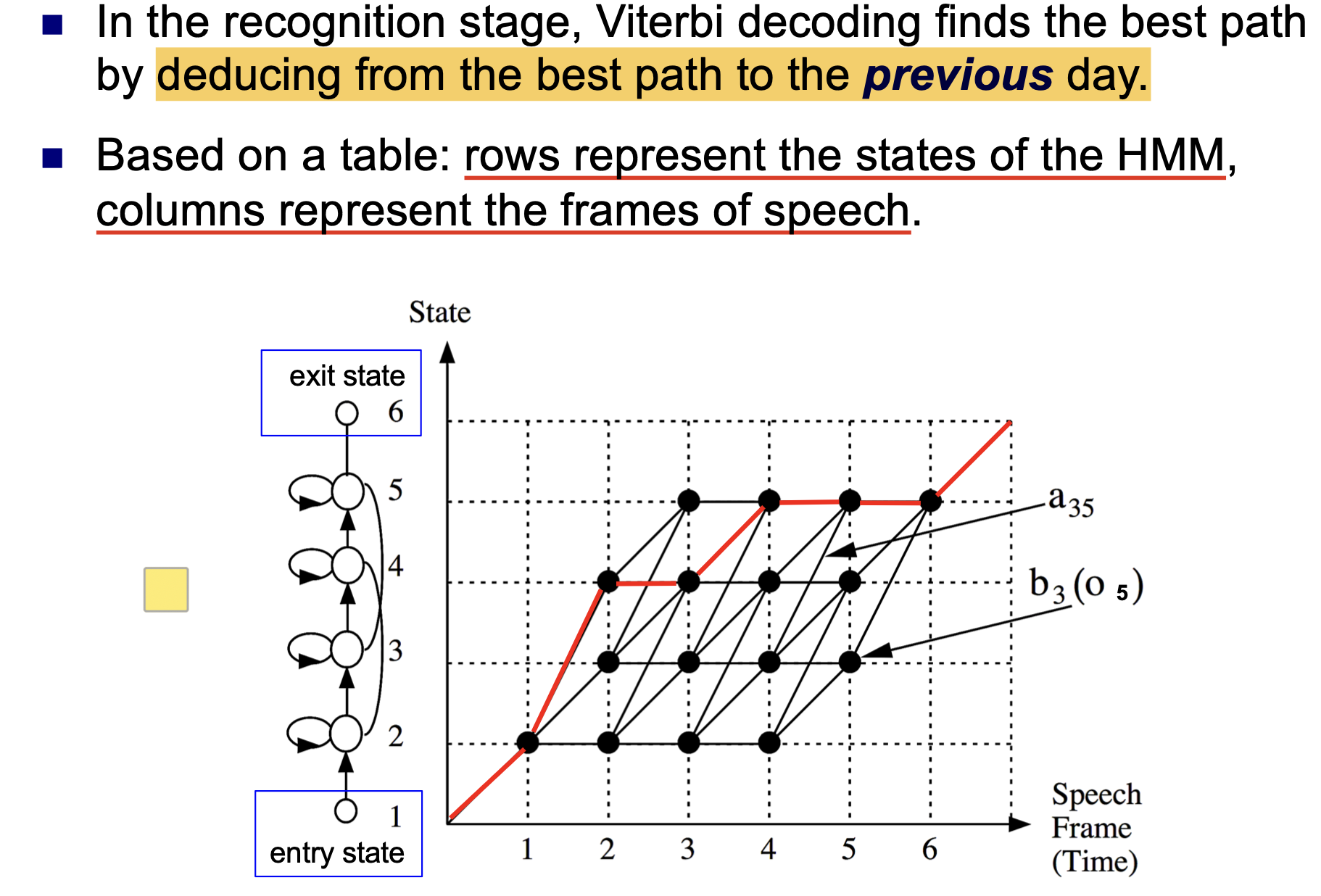
维特比算法在解码时, 始终 基于上一时间点的最优状态 推断 下一时间点的最优状态:
端到端的语音识别
除了使用概率模型外, 我们自然可以使用单个神经网络完成全部的解码和映射流程:
使用一系列 相互对应的特征向量-句子元组 作为神经网络模型的训练数据, 训练合适的神经网络模型, 如 RNN:
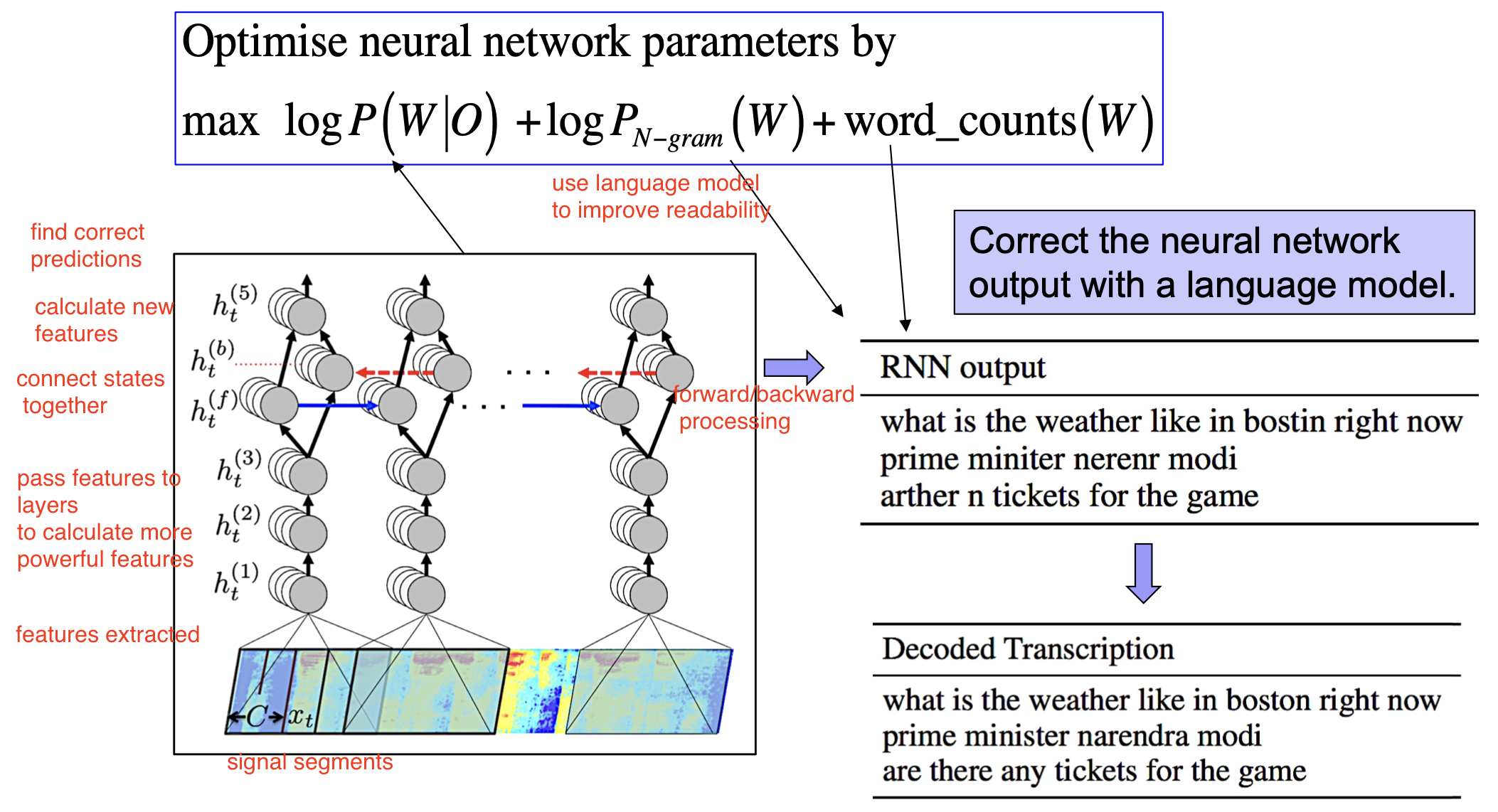
注意: 可能需要使用语言模型对神经网络的输出进行适当的修正.