导论与数据源
本章主要介绍自然语言处理领域的一般问题, 大致内容以及收集和分析语料数据的一般方法.
定义和应用
自然语言处理是机器学习和数据科学领域的一个细分方向, 其主要工作是将海量的 自然语言 作为数据进行数据分析和模型构造. 在当前, 随着互联网的进一步发展, 以文字为载体的信息量将持续以指数级增长, 并且通过自然语言进行的人机交流, 基于自然语言处理模型的会议/聊天主持/监督等落地应用将进一步地和人们的日常生活结合.
“自然语言处理”, (Natural Language Processing)“ 是 令计算机 ”理解“ 以自然语言表示的数据 的必须步骤, 一个程序是否能被定义或归类为自然语言处理程序, 关键在于看它 是否具备某种意义上理解自然语言的能力. 自然语言处理问题的主要方向包括:
- 文本发掘 (
Text Mining) - 文本分析 (
Text Analytics) - 计算语言学 (
Computational Linguistics) - 语言技术 (
Human Language Technology)
其具体领域有:



可见自然语言处理领域 应用场景广泛, 发展前景巨大.
主要问题和挑战
一般来说, 从多种使用场景中收集的信息主要可被划分为两类: 结构化的, 数字或程序化的信息 和 非结构化或半结构化的信息.
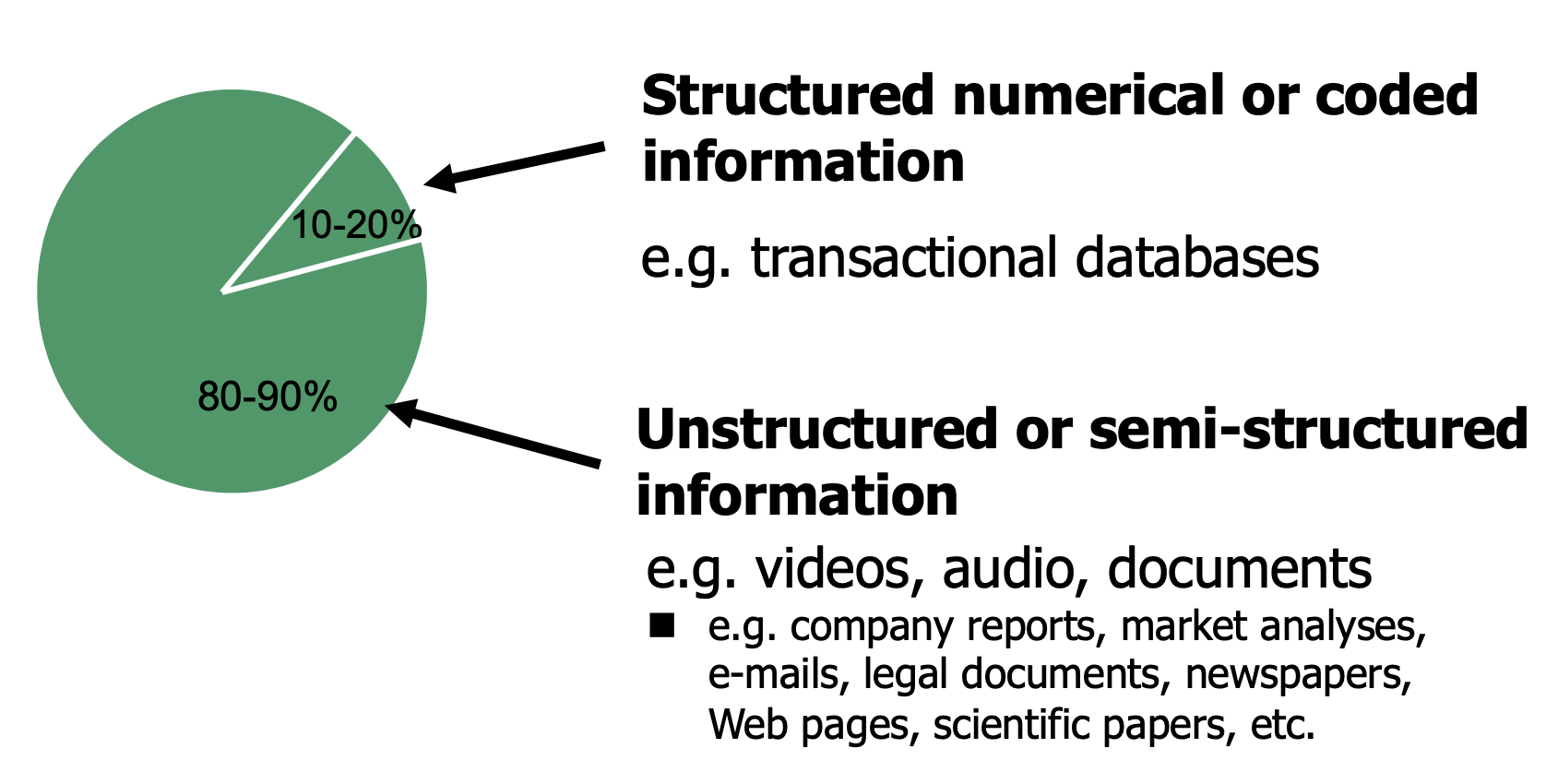
而文本数据 (Text Data) 的一大特征是: 它难以被准确归类为 “结构化” 或 “非结构化”: 对人类而言, 文本数据所包含的, 以语法组织的语义信息显然是结构化的, 但对无法理解自然语言的计算机而言则并非如此.
此外, 文本数据还具备 可变性 (Variability) 和 歧义性 (Ambiguity): 前者表示同一个物体可以被多种完全不同的表示方法所表示, 而后者代指相同的单词在不同的语境下可以有不同的解读方式.
进一步地, 歧义性还可被分为 单词级别的歧义性 和 句子级别的歧义性, 也就是 “一个单词可以被理解为多种含义” 和 “一个句子具有多重含义”.

歧义性的不同层级定义如下:

综上, 自然语言处理领域所包含的主要挑战如下:
- 在大多数情况下被处理的数据都不具备机器可分析的结构, 也就是
Unstructured. - 语言具有歧义性与可变性.
- 在语言中还有一些具备 特殊含义 的句段, 如成语, 谚语等.
语料数据源
下面讨论自然语言处理中数据的来源. 从概念上说, 可用的数据可以被分为下列的两种来源:
- 由 单词 或 短句 组成的 字典.
- 一系列由文本或语音组成的集合 (词库,
Corpus)

其中, 第二种语料数据的作用最大. 下面给出 词库 的定义:
定义 (词库, Corpus)
称由 大量 的 语言数据 的集合为 词库, 词库的组成称为 词素 (
Corpora).

而词素可被进一步分为多种类型:

词库可以是一系列原始数据的集合, 但在信息的角度真正具有价值的词库应该是 经过标注的词库 (Annotated/Labelled corpus).

一般地, 对词库中词素的标注可以包括 语法信息, 语义信息 等. 经过标注的词库既可作为机器学习模型的训练数据和评估数据.


由于对词库的标记需要 人为进行, 因此标注数据的质量将会不可避免地受到不同因素的影响.

因此, 为了最大程度避免这些因素对信息标注质量的影响, 就需要确定 信息标注的准则: Annotation Guideline.

我们同时也可以使用一些统计学上的技巧来确定 信息标注的共识.

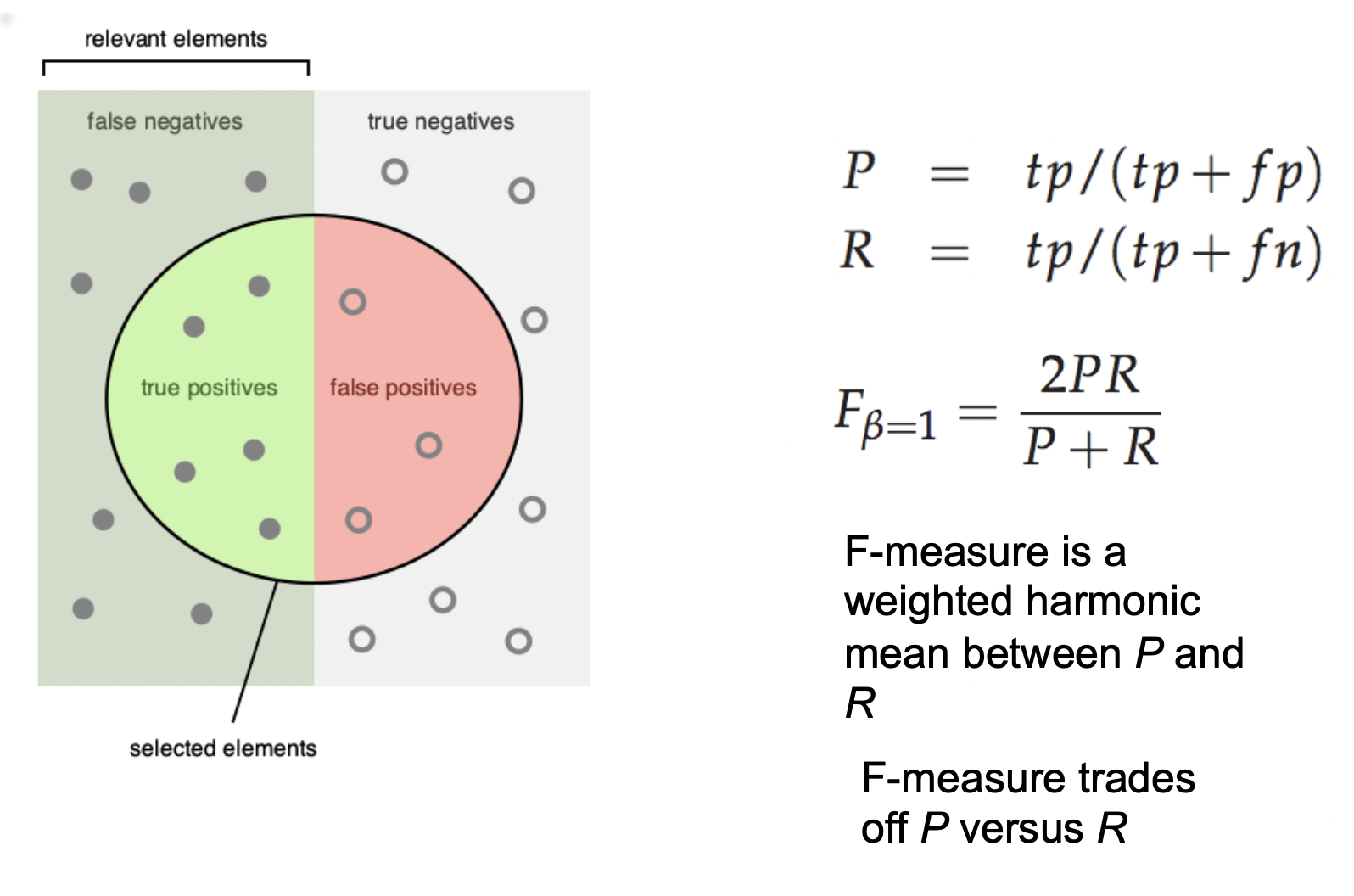
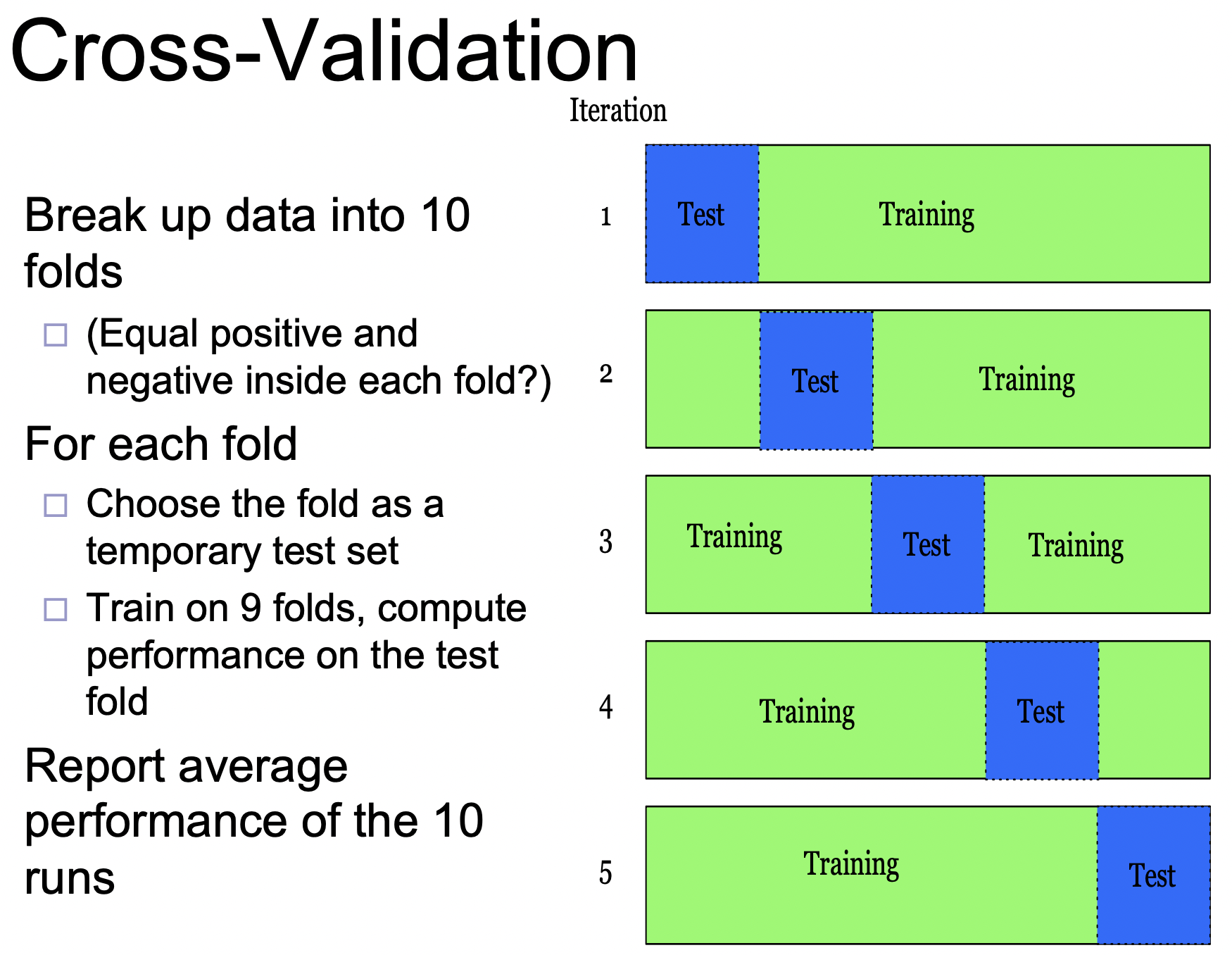
评估模型的基本方法
我们可以沿用机器学习领域的模型性能评估方法对自然语言处理模型进行评估: