
进阶课题:并行计算和内存安全语言
本章将简介 程序语言与程序范式 课程的最后一部分: 进阶课题. 我们将在这部分中首先介绍用于构造 智能契约 (程序被部署在网络上自动运行并通过信息传递互相交互) 的 Solidity, 并以此为契机引入一系列关于 并行编程 (Concurrent Programming) 的基本概念; 随后介绍一种较新的程序设计语言: 和 C/C++ 同样接近底层性能极高但内存安全的 Rust.
通过本章的学习, 我们将更深入地理解: 在现代程序设计语言中, 对资源的管理和利用愈发占据重要的位置.

下面首先讨论智能契约语言: Solidity.
1. Solidity
Solidity 是一门主要用于编写智能契约的程序设计语言. 我们下面对 “智能契约” 给出定义:
智能契约满足下列的四条性质:
- 被部署在 网络 上.
- 任何智能契约都具有 网络地址, 并可以通过网络地址被访问.
- 智能契约具有 不同的状态, 而且对于各种不同的状态都有对应的行为定义.
- 智能契约通过在网络上 发送和接受信息 和外界进行信息交互.
而另外一个显著特征是: 智能契约在被部署后, 就会 自动地 运行在计算机上.
Solidity 介绍
在 Solidity 中, 和面向对象程序设计语言中的 类 相对应的是 契约 (Contract), 本质上它所描述的是一个将会被部署到网络上自动运行的对象. 下面是 Solidity 中契约的基本结构:

可以看出, 和类一样, 契约也可以具有大量成员变量 (Member Variables), 而且也有自己的 构造器, 而契约和类之间行为差异的根源是, 契约具有 接收和处理外部信息 的功能.
我们应该近似地将契约中的每个方法和构造器都视为 Message Handler, 来自外部的信息可能会要求调用它们中的任一个.
和其他方法不同的是, 契约中的构造器只有在 这个契约的对象被创建 时才会被 这个契约的拥有者 (Owner) 调用 一次.
下面尝试在一个在线 IDE: Remix 中编译和运行上图中的例子.
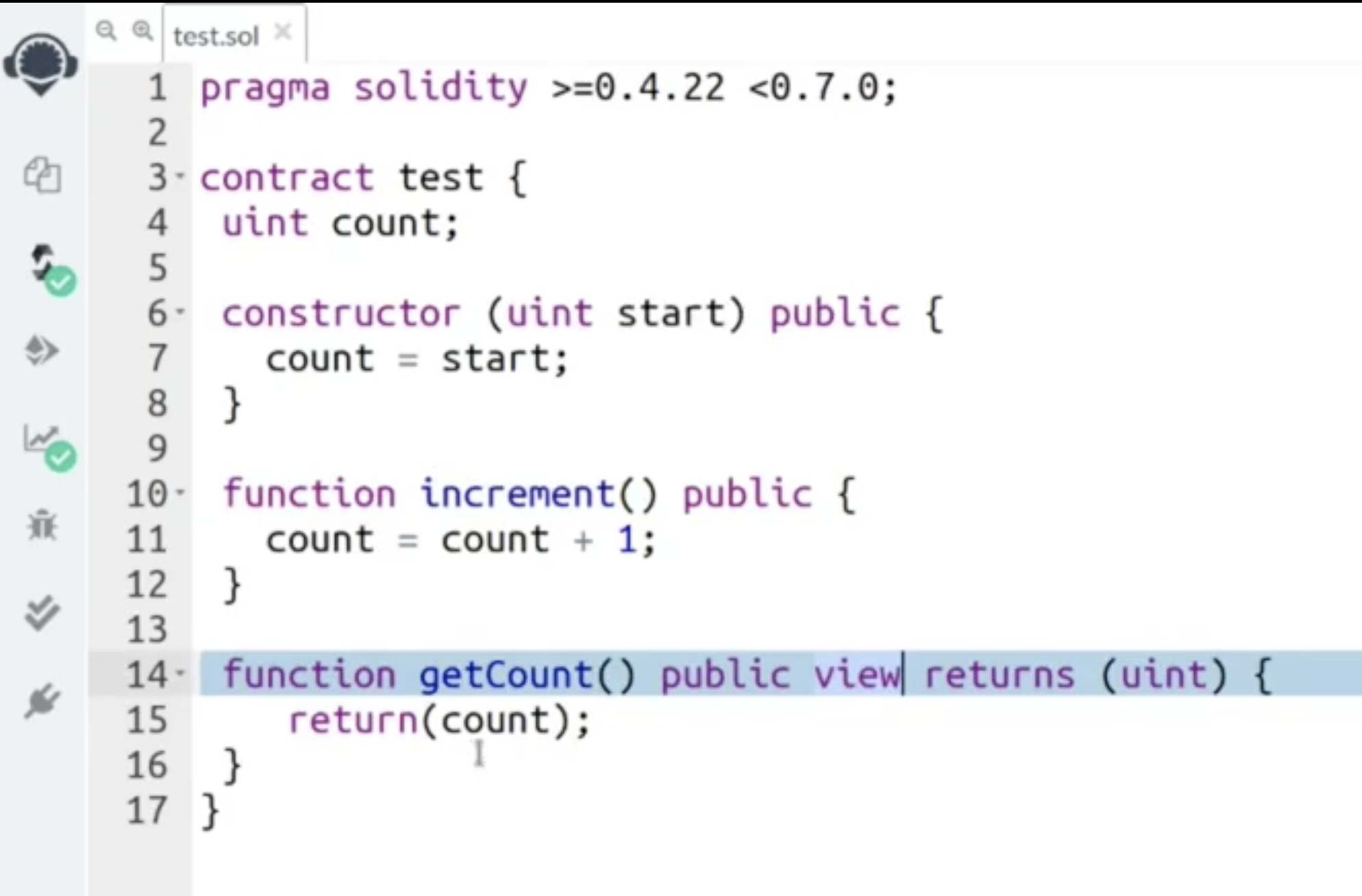
注意 view 标记表明, 被标记的方法 getCount() 被调用时 不会修改契约的当前状态, 而 returns (uint) 关键字表明该方法被调用时会返回一个类型为无符号整型的数据.
身份识别和不可分行为
契约语言需要具有 明确地表明下列三个对象的能力 :
- 信息发送者的身份.
- 不可再分的行为/操作/指令.
- 运行契约的成本和代价.
首先, 由于智能契约需要具备在网络中通过发送和接受信息从而实现交互和信息传递的功能, 任何信息都需要标记它的发送者 (Message Sender) 是谁, 这显然是和常规的程序语言中调用函数的过程完全不一致的.
其次, 由于我们同时需要考虑智能契约并行运行的可能性, 我们需要明确什么样的指令才能被视为不可再分 (不可以被任何同时在网络上运行的进程干扰和中断的指令), 需要以原子的形态参与并行运行时的任务调度.
最后, 由于智能契约运行在他人的计算机硬件上, 对系统资源 不具有控制权, 因此我们还需要能够具有明确任何契约运行产生的成本和代价的能力. 从而使我们能够为了让契约运行恰好支付相应的代价以换取相应的计算资源.
信息发送者身份的确定问题
回顾面向对象程序设计语言, 它们一般包含形如 this, self 一类的, 用于指示在某个类内部的类变量或类方法的关键字. 在 Solidity 中, 同样包括 this 关键字.
但它的使用场景略有不同. 首先, 它可被用于获取 当前契约的余额: address(this).balance, 可以进一步用于建模/构造某种意义上的 “在线交易”.
同时, Solidity 具有 msg 关键字. 它的其中一个作用是允许我们获取信息发送者的地址: msg.sender.
考虑下面的例子:
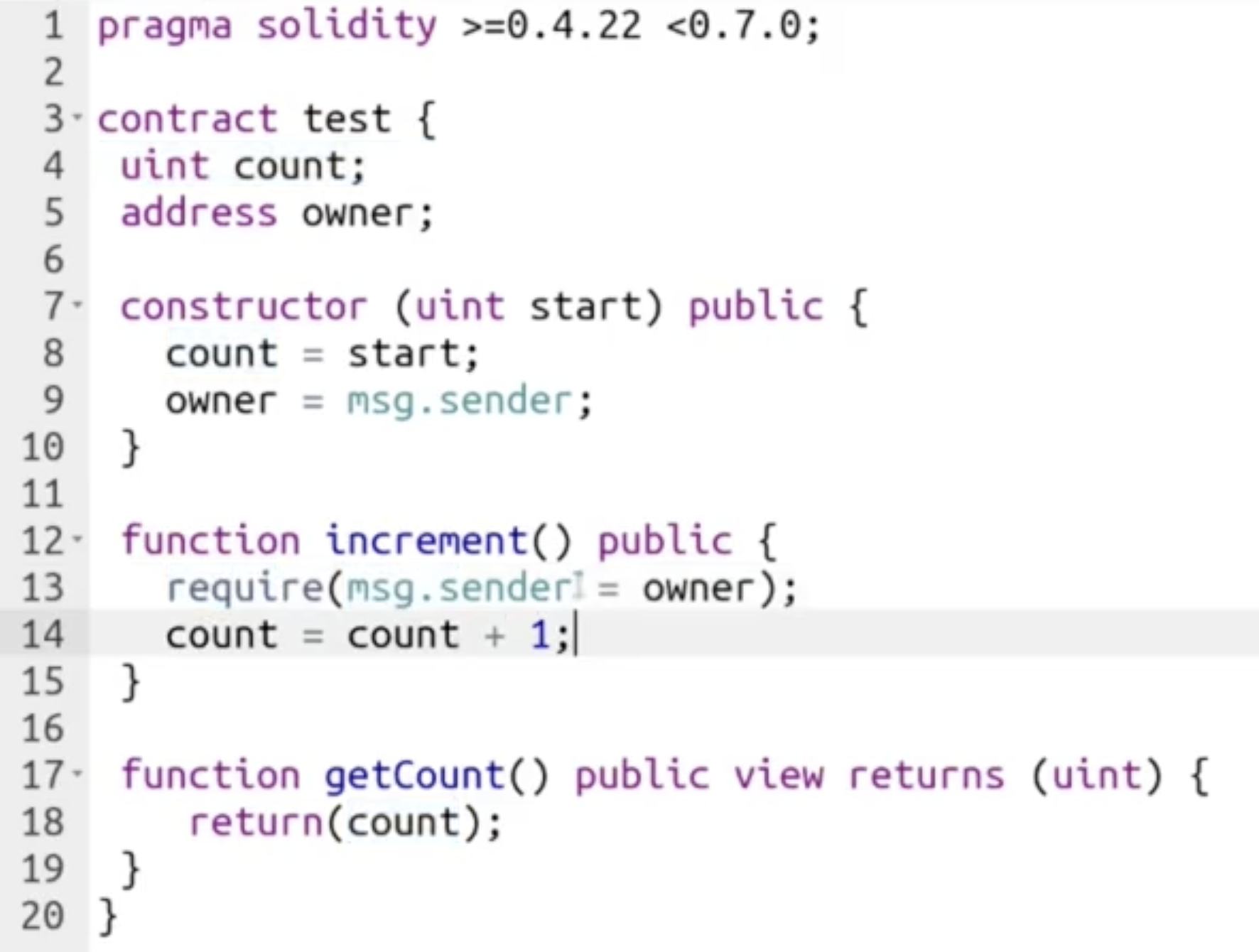
注意在 increment() 方法中我们对 要求调用这个方法的信息的发送者身份 提出了限制: 只有在要求调用本方法的信息的发送者是 owner (这通过检查地址实现) 时, 函数才会被执行, 否则 一旦发现要求不满足, 该方法此前执行的所有操作都会被 revert.
换言之, 此处的 require(msg.sender = owner) 实际上等同于:
1
2
3
if (msg.sender != owner){
revert();
}
而不同之处在于, 即使 require(...) 在上图的例子中被放在了 14 行后面, 只要条件不满足它也能 revert 此前该方法执行过的所有操作.
表示契约运行的成本问题
在上一小节中介绍了 msg 关键字, 它表示 传入契约的信息. 除了使用 msg.sender 获取信息发送者的身份外, 它还可被用于表示运行成本:
-
msg.gas表示了这条信息所携带的, 关于处理它所需代价的补偿. (payment for the cost of processing the message)在
Solidity中, 这样的代价被称为gas, 单位为wei. (实际上wei是很小的单位)Solidity中的 任何一条指令 都有对应的gas数额: 执行任何指令都会消耗相应数量的gas. -
msg.value表示了这条信息所携带的, 用于支付契约所将提供的服务的费用. (payment for the service)
考虑下面的例子:
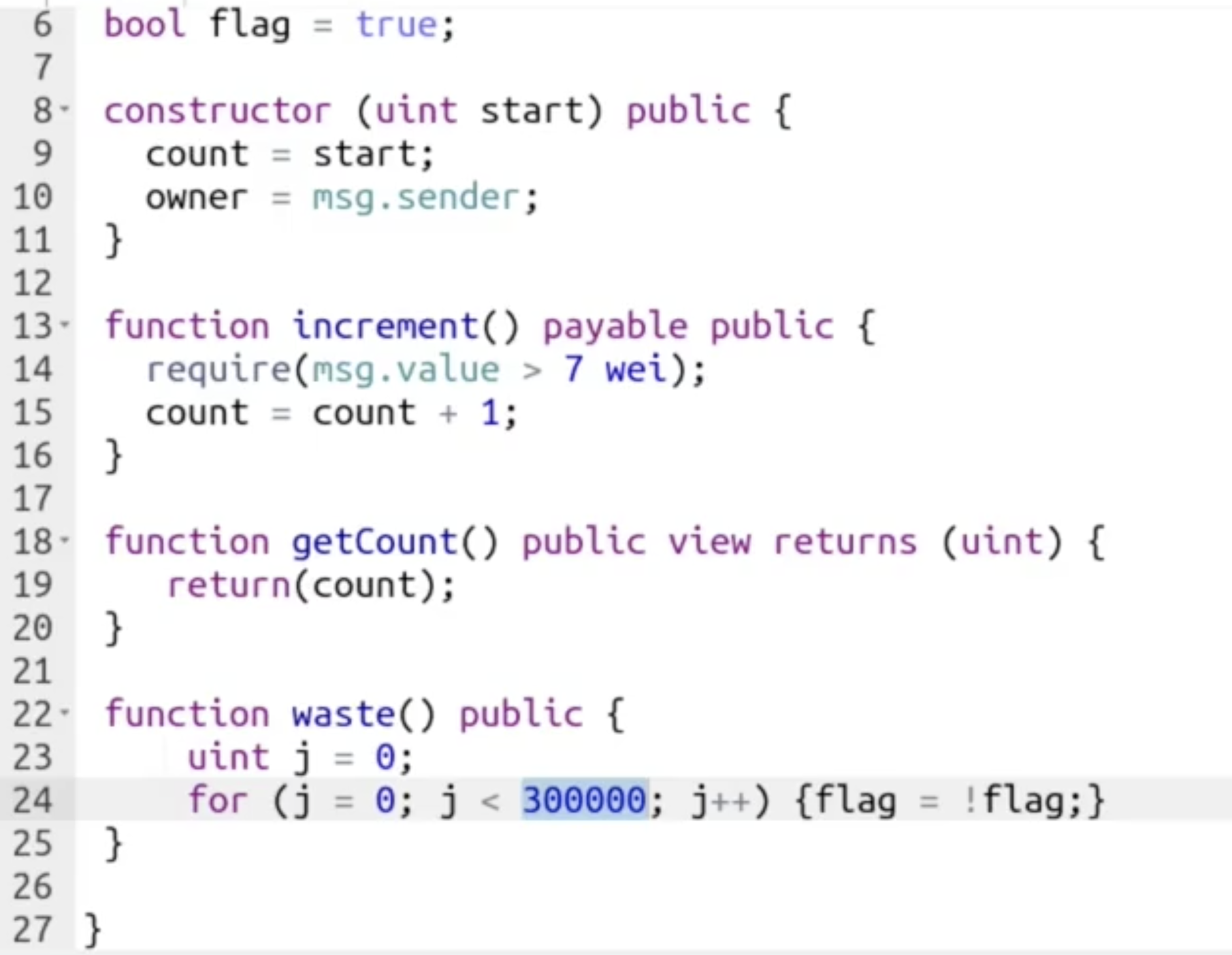
首先对于方法 increment(), 我们定义任何调用它的信息都需要携带不少于 7 wei 的支付费用.
其次, 对于方法 waste(), 它被刻意设计为执行大量指令以高效地浪费 gas. 如果我们限制 gas limit, 则它会因为资源不足而无法执行.
信息传递和并行执行相关的其他问题
本节我们讨论在 Solidity 中如何向其他契约发送信息, 并进一步讨论因为契约的信息交互所可能产生的两种 concurrency problem.
信息传递: 向其他契约发送信息
在 Solidity 中, 向其他契约发送信息的方式类似于面向对象程序设计语言中调用对象方法的方式:

而在上一节中可知, 在一些情况下还需要在发送信息时附上对目标契约服务的支付费用.

数据竞争问题 (Data-Race)
我们下面简要讨论数据竞争问题. 考虑下面的例子:

在上图所示的例子中, 左右两个线程 同时执行, 并 同时具有 对缓冲数组 buffer 的访问权限.
右侧线程将会持续从外界接受输入并存到 buffer[indexi] 中, 然后更新 indexi 确保它在 $0-9$ 内循环.
左侧线程则会持续先用同样的方式循环更新数组指针 indexo, 然后 输出 buffer[indexo] 存储的内容到外界.
上述线程的问题是: 二者的运行速度可能不同. 如果右侧线程运行速度极快, 则它会先于左侧进程完成对缓冲数组 buffer 的信息更新, 然后会覆写掉此前保存, 需要被左侧线程输出, 但还没有被输出的信息, 导致信息丢失.

上面的例子就是典型的 数据竞争问题.
我们下面给出数据竞争问题的定义:

注意在上面三点特征中, 导致问题发生的主要特征是: 不存在任何规范化信息读写顺序的机制. 如果信息读写可以被某套规则严格控制, 即使某个情况满足上面的前两点也不会发生数据竞争问题.
数据竞争问题在操作系统寄存器读写, 大规模并行数据库内容读写等场景中极为常见, 一般的程序语言都通过引入各种资源锁缓解或避免问题.
而 Solidity 的解决方法简单粗暴: 它彻底放弃并行性, 不允许任何契约同时执行….

重入问题 (Re-entrancy)
虽然在 Solidity 中数据竞争问题不存在, 但由于智能契约语言中不可避免会出现 remote function call, 因此还是可能出现 重入问题:

重入问题发生在两个函数中各自存在 相互调用 的关系时, 基于双方函数中的逻辑以及对变量进行的操作, 可能出现包括数据不安全在内的问题.
复杂并行问题
下面我们暂时超出 Solidity 的范畴, 从一般的角度考虑复杂的并行问题.
在本节中, “并行” 的定义是广义的: 指 大量计算 在 同时执行 的现象.
进程和线程
举例而言, 即使在 Solidity 中, 也可能出现 网络中 大量契约被同时部署 的现象.
但与此同时, Solidity 使用名为 Consensus Algorithm (共识算法) 的算法确保在任何时刻整个网络上只会有一个函数运行, 并且它还使用了一些加密技术确保任何实体都不可能违背这个顺序.

但对于需要并行的其他场景而言, Solidity 解决并行导致的问题的方法是不适用的. 我们下面介绍一些其他的解决方案: 进程 (Process) 思想, 线程 (Thread) 思想 或者让编译器自行优化.

注意:
- 进程相比线程独立性更强, 有属于自身的, 不可被外界观测和控制的状态, 天生适合原子化 (不可再分的) 操作的实现.
- 线程实现存在潜在的数据竞争问题, 它们通过修改和读取表示状态的公共数据 (
Public States) 确定数据是否可被安全读写, 避免数据竞争. - 让编译器自行优化实际上是非常复杂和困难的, 而且一般编译器自动优化的结果本质上就是进程思想或线程思想的实现.
信息传递问题
下面考虑和 Solidity 共通之处更多的 进程思想 中可能出现的问题.
Solidity 通过强行确定信息的顺序让它们具有原子化的表现, 但标准的进程思想不同, Solidity 不允许任何意义上的并行执行. 而这原本是状态私有不可被外界篡改的进程最适合执行的事.
而 Solidity 选择这种实现的原因是它可以从底层确保状态安全, 通过禁止并行执行, 就彻底消除了进程间状态不一致的可能性.
而为了确保信息通信的一致性, 同样有下列三种解决方案:
Remote Procedure Call远程程序调用: 和调用方法类似, 信息发送者发送信息, 并在收到 接收者 完成信息处理之后发送回复后 继续执行程序.Synchronous Messages同步信息: 信息发送者发送信息, 并在收到接收者 表明收到信息 的回执后就继续执行程序, 不关心接收者是否完成了信息处理.Asynchronous Messages异步信息: 信息发送者发送信息, 然后直接继续执行程序, 既不关心信息是否送达, 也不关心信息是否被处理完成.

共享内存问题
下面考虑线程思想中可能出现的问题.
由于线程思想中, 所有线程共用内存, 因此最直接明显的潜在问题就是数据竞争问题.
而解决数据竞争问题的实质是: 如何确保对信息访问的 互斥, 即如何避免对同一块内存的 同时访问?
-
将对数据的读写操作 原子化, 从而根除数据读写被中断导致数据污染或出现数据竞争的可能性. 这要求程序员使用特定的算法, 如
Peterson's Algorithm, 确保数据读写的互斥性, 主要问题是低效, 而且不能确保对互斥的实现适用于所有硬件平台. -
提供底层的, 原子化的, 对数据的
test_and_set操作其实质是实现原子化的
test_and_set方法, 实现在调用它时用 原子化的操作 将变量值修改为新的, 同时返回旧的值.由于实现了
test_and_set方法后就可以使用比Peterson's Algorithm简单的多的方法实现数据读写的原子化, 因此用这种方式可以一定程度上的提高效率. -
直接提供更高阶的同步方法, 如资源锁, 信号量等.
-
直接为程序或函数提供同步方法: 直接定义一段代码或某个方法需要被同步 (不可被干扰), 被这样定义的程序运行时禁止其他任何并行操作.

高阶的并行问题
需要注意, 互斥 (Mutual Exclusion) 并不能防止所有的并行运行问题. 虽然它可以预防 特定的底层并行问题, 但并不能预防其他的 高阶并行问题 的发生, 如 死锁/活锁.
(Dead lock: prevent anything to happen; Live lock: prevent useful things to happen but allow infinite number of useless things to happen)

如下面的例子中所示, 使用 Solidity 建模的哲学家问题就是一个死锁问题.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
pragma solidity >=0.4.22 <0.7.0;
contract philosopher {
enum State{hungry, gotLeft, gotRight, happy}
chopstick left;
chopstick right;
State state;
constructor(chopstick nleft, chopstick nright) public{
left = nleft;
right = nright;
state = State.hungry;
}
function getLeft() public{
require(state == State.hungry);
left.pickUp();
state = State.gotLeft;
}
function getRight() public{
require(state == State.gotLeft);
right.pickUp();
state = State.gotRight;
}
function eatNoodles() public {
require(state == State.gotRight);
state = State.happy;
}
function think() public {
require(state == State.happy);
left.putDown();
right.putDown();
state = State.hungry;
}
}
contract chopstick {
philosopher holder;
bool up = false;
function pickUp() public{
require(up == false);
holder = philosopher(msg.sender);
up = true;
}
function putDown() public{
require(up = true && holder == philosopher(msg.sender));
up = false;
}
}
举例而言, 创建三个 philosopher 契约, 每人均进行 pick left-chopstick 操作, 然后任何 philosopher 都无法再执行 pick right-chopstick 操作, 因为任何 philosopher 的右筷子总是另一个人的左筷子, 死锁形成. 在这一情况下, 任何操作都无法被执行.
在实际情况中, 我们除了考虑状态的 安全性质 (Safety Property) 外, 同时要考虑 生命性质 (Liveness Properties): 除了避免坏事发生之外, 我们还要确保好事终将发生.

2. Rust
在本节中我们将以 Rust 为例进一步讨论 内存管理的基本方法. 首先回顾其他程序设计语言中的内存管理策略.
在 C/C++ 中, 不存在任何主动的内存管理机制, 程序员需要使用 malloc() 和 free() 手动进行内存管理. 而显然这一机制可能会导致幽灵访问 (use after free) 和内存泄漏 (forget to free) 问题的发生.
在 Java 中同样有对象和变量的引用 (Reference) 机制, 解决内存管理问题的途径是引入 “垃圾回收机制”: 垃圾回收器 (Garbage Collector) 会自动地持续监测对程序中数据的引用, 若某个数据不再被程序中任何逻辑引用, 它就会被判定为 “垃圾” 从而被垃圾回收器自动回收.
通过引入垃圾回收机制, Java 避免了幽灵访问问题的发生, 也解决了潜在的内存溢出问题. 但由于垃圾回收器会持续检查引用, 因此这会带来性能损失, 导致程序运行效率下降.

从 C/C++ 和 Java 的例子上可以看出, 程序运行效率与内存安全之间存在 权衡关系, 在 C 中程序员通过承担确保内存安全的责任换来了高效率, 而在 Java 中让程序设计语言本身处理内存安全问题的代价是降低了程序运行效率.
但实际上程序运行效率和内存安全之间的权衡并不是无法调和的. 从 Java 来看, 我们注意在 Java 中仍然存在 NullPointerException, 这意味着 垃圾回收机制并不能从根本上解决所有的内存安全问题.
可以注意到, 当 两个变量引用了相同的数据 (也就是 aliasing) 时, 如果其中一个变量对该内存空间中的数据进行了修改而另一个变量假设数据没有被修改, 就会出现状态上的 不一致性.
注意在这里我们实际上可以把变量类比为线程.
考虑下面的例子:
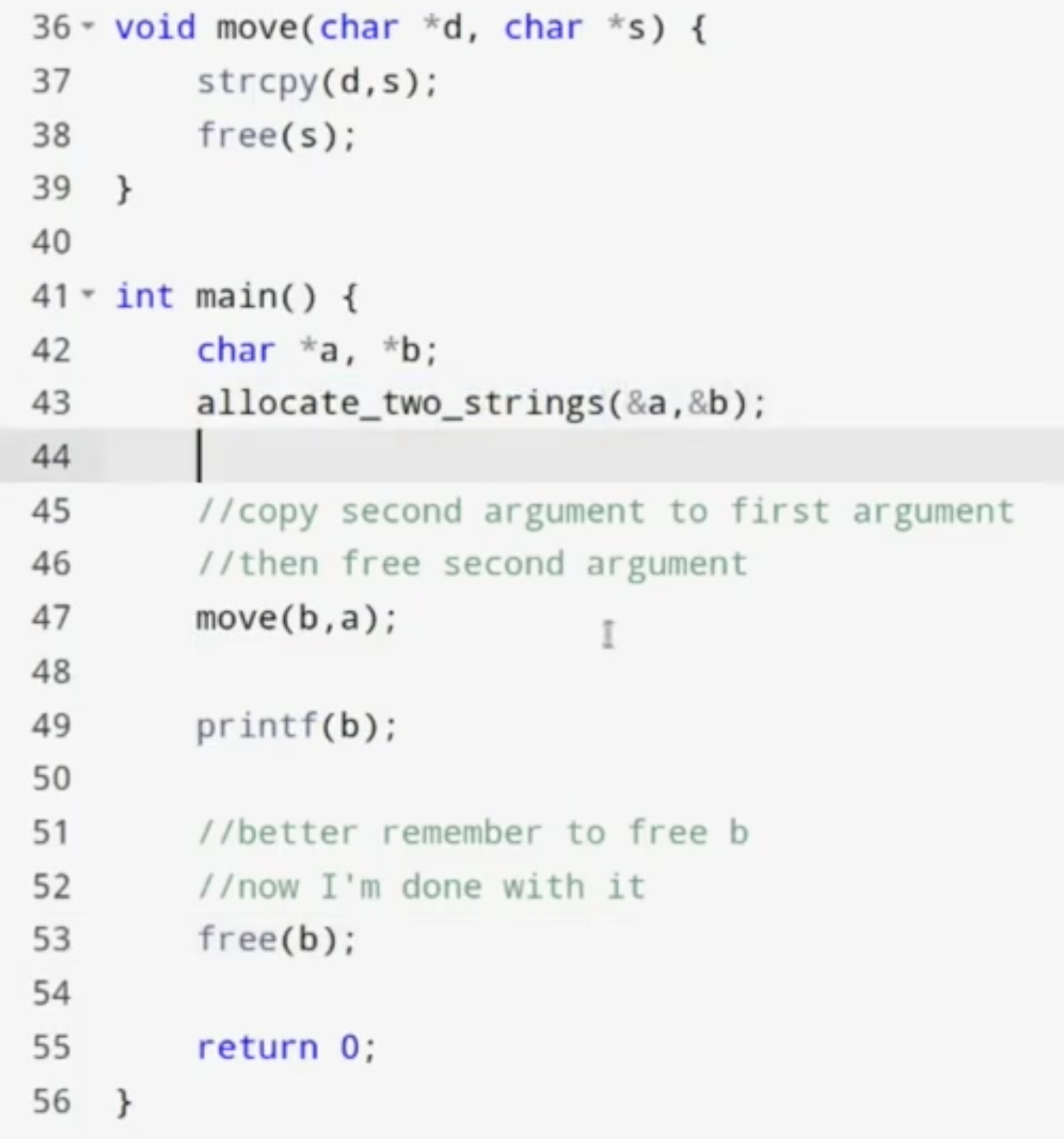
上述的代码看上去没有任何内存安全问题, 但编译执行的话结果如下:

原因在于, 在执行 move(b, a) 方法时, 我们隐式地假定了 指针 a 和 b 引用的内存空间不同, 但在下面的 allocate_two_strings 定义中可以看到, 我们将 a 和 b 引用的内存空间 设为了同一块.
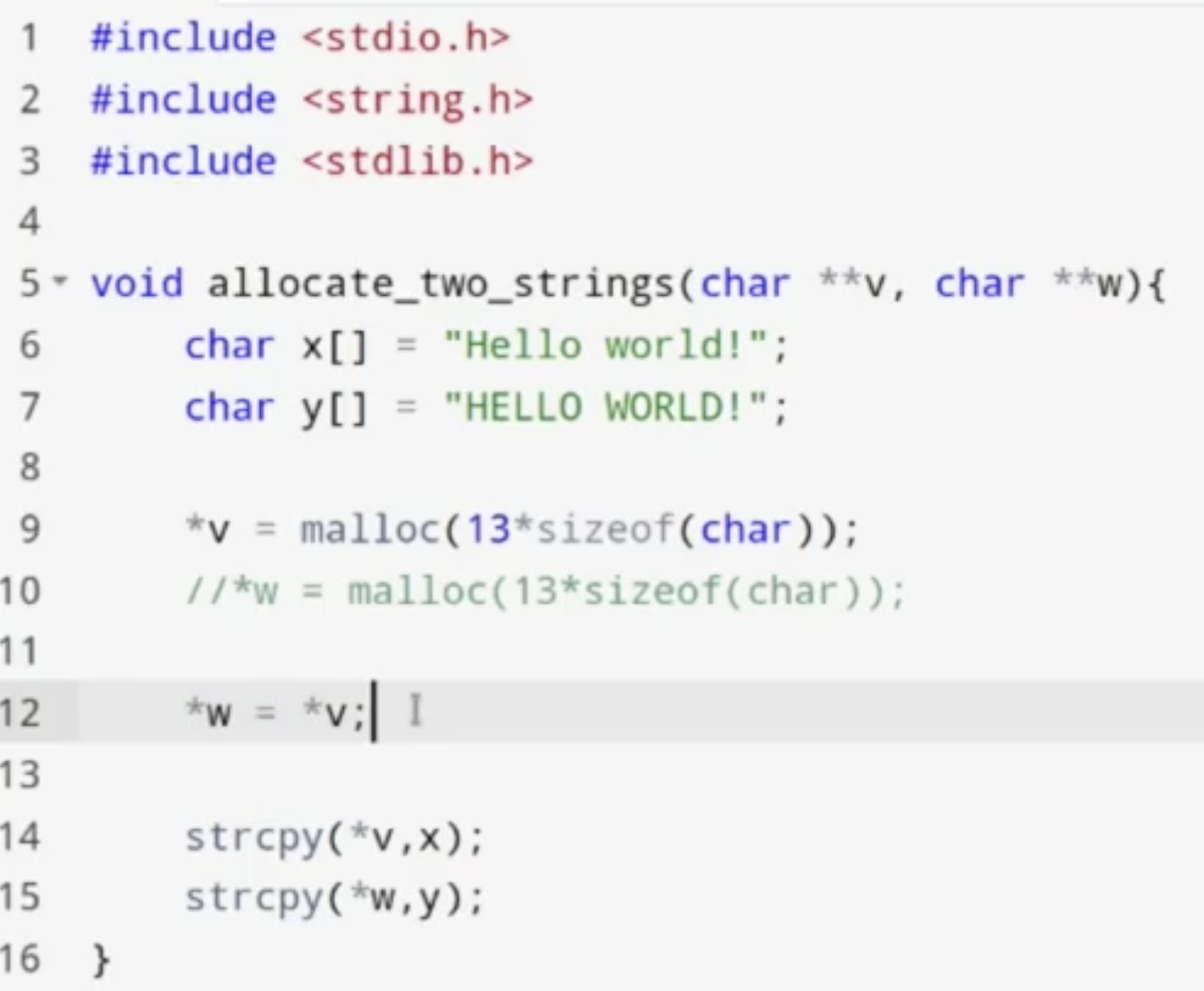
因此, aliasing 就导致了报错提示的, 双重内存空间释放问题.
Rust 中的内存管理
和 C/C++ 与 Java 不同, Rust 使用一套构建在 编译器中 的内存管理 规则 而非机制确保诸如 aliasing 一样可能导致内存错误的问题永不发生.

这套限制内存错误发生的约束系统称为 Ownership System. 它的细节如下:
数据所有权
在 Rust 中, 任何 引用类型的数据值 都有一个 类型为变量 的所有者 (可以近似地认为任何数据都有一个所有者, 这个所有者是变量). 进一步地, Rust 会确保:
- 任何数据都同时 有且只有一个所属者
-
若所属者离开了作用域 / 结束了生命周期, 则它拥有的数据占用的内存空间会被 自动释放.
注意, 此处所指的, 变量的 “作用域” 是指 从变量被声明的那行代码到右中括号包起来的范围内, 在
Rust中我们可以使用中括号{}人为指定变量的作用域. - 数据的所有权会通过 变量赋值 和 函数调用 在变量之间发生 转换 (
pass).

数据所有权租赁
进一步地, 为了避免频繁的在变量之间迁移数据的所属权, Rust 引入了 所属权租赁 机制.

基本数据类型和数据可变性 (Mutability)
在上面的小节中我们提到过, 在 Rust 中只需关注 引用类型 数据的所属权问题. 对形如 u32 ($32$ 位无符号整数) 一类的 基本数据类型, 我们无须关注它们数据的所属权, 因为这些基础数据类型在变量赋值时是被直接 复制而非引用 的, 因此无需关心 aliasing 问题.
但是需要注意的是: 在 Rust 中, 除非我们明确地声明它是可变的 (Mutable), 任何变量都是默认 不可变 (Immutable) 的. 这一规则不同于 Ownership System 作用域仅限于引用数据类型, 它的应用范围是 全体数据类型 (引用数据类型和基本数据类型).

如下面的例子所示: 由于 $10$ 是基础数据类型, 因此第 2, 3 行的操作不会导致 $10$ 的所属权从 $i$ 变为 $j$ 导致 $i$ 无法被输出; 而由于我们在定义变量时 没有明确说明它们是否可变, 编译器就默认声明的变量 $i$, $j$ 都是 不可变 的, 因此尝试修改 $i$ 的值时报错.
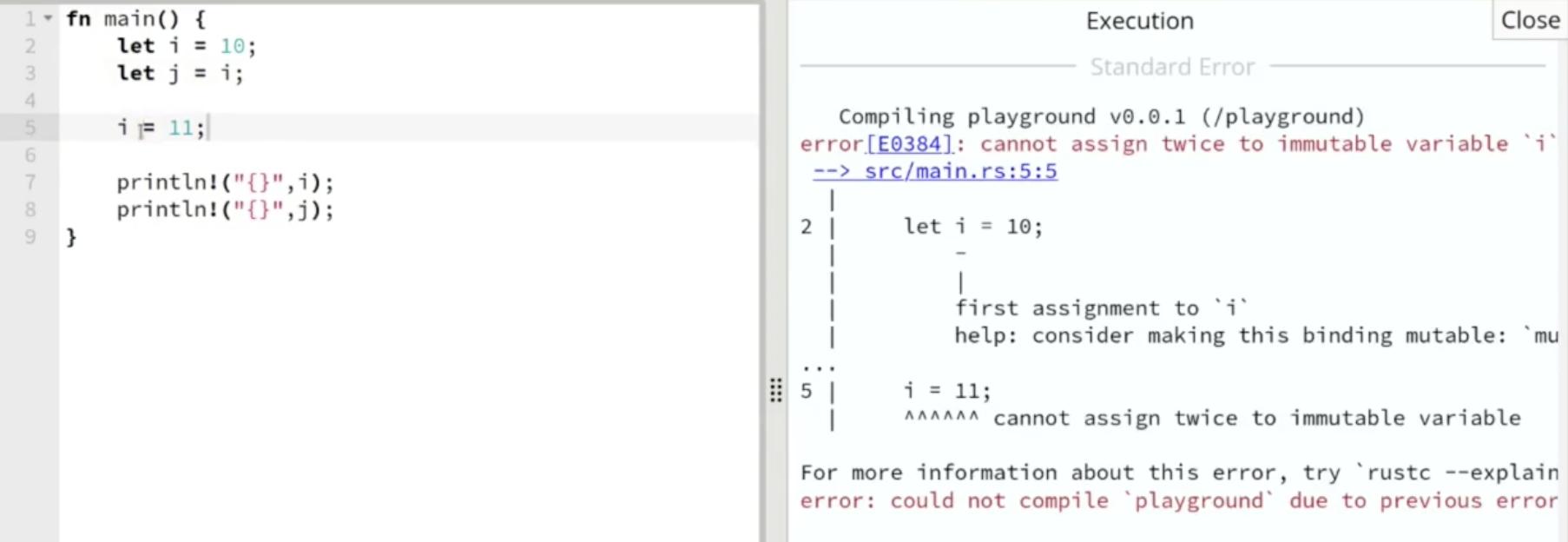
与数据可变性和数据所有权租赁相关的问题
由于声明变量类型为 可变 (mutable) 会导致变量数据可以发生变化 (换言之, 变量数据可以被修改), 而租赁变量的所属权又可能允许同一个变量的数据被多个访问对象访问和修改.
因此考虑多个变量同时租赁同一个可变的数值数据的情况, 将可变数据的所属权租赁 看上去可能会带来和 aliasing 类似的问题.
Rust 对这一潜在问题的解决方法是: 任何情况下, 在租赁某个数据值的所有权时都需要 明确声明以可变 (Mutable) 还是不可变 (Immutable) 的方式租赁所有权.
随后, 若声明了将以 可变形式租赁所有权, 则 该对象只能租赁数据所有权一次, 否则将被允许以 不可变形式租赁所有权无数次.

注意此处的 “租赁一次” 并不是严格意义上的, 只要在租赁开始和租赁的数据最后一次被使用之间的时间段中, 对租赁的数据进行的任何使用都被视为 “同一次”.
考虑下面的例子, 说明 在一个可变租赁内部进行对同一个数据的不可变租赁是不可行的:

由于字符串 s 被声明为可变, 因此我们可以对该变量所有的数据进行修改, 程序编译运行正常.
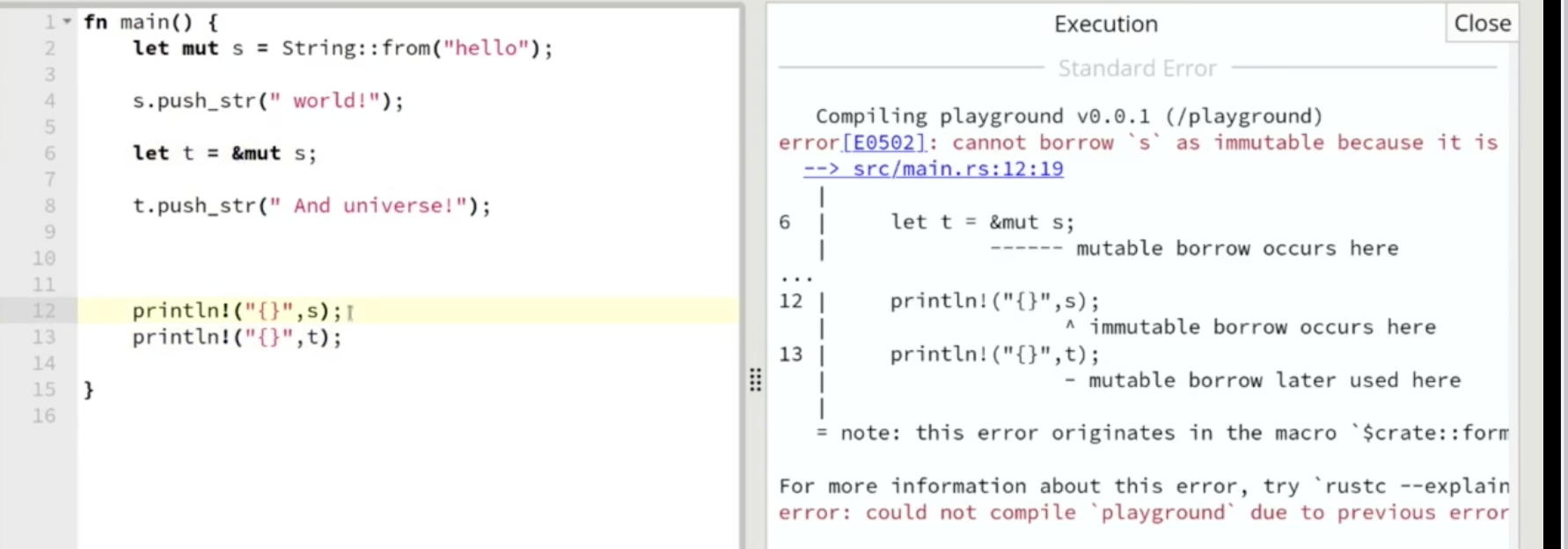
我们定义一个 可变的变量 t, 并让它以 可变的方式租赁变量 s 所拥有的数据的所有权. 根据 “同一次” 的定义, 在第 $6$ 行对这个租赁的声明开始, 到第 $13$ 行租赁的数据内容最后一次被使用为止这个租赁都是 active 的, 而 active 的可变形式租赁所借用的内容则不能被其他任何对象所访问, 因此第 12 行提示报错.
下面尝试在一个不可变租赁内部对同一个数据进行可变租赁:
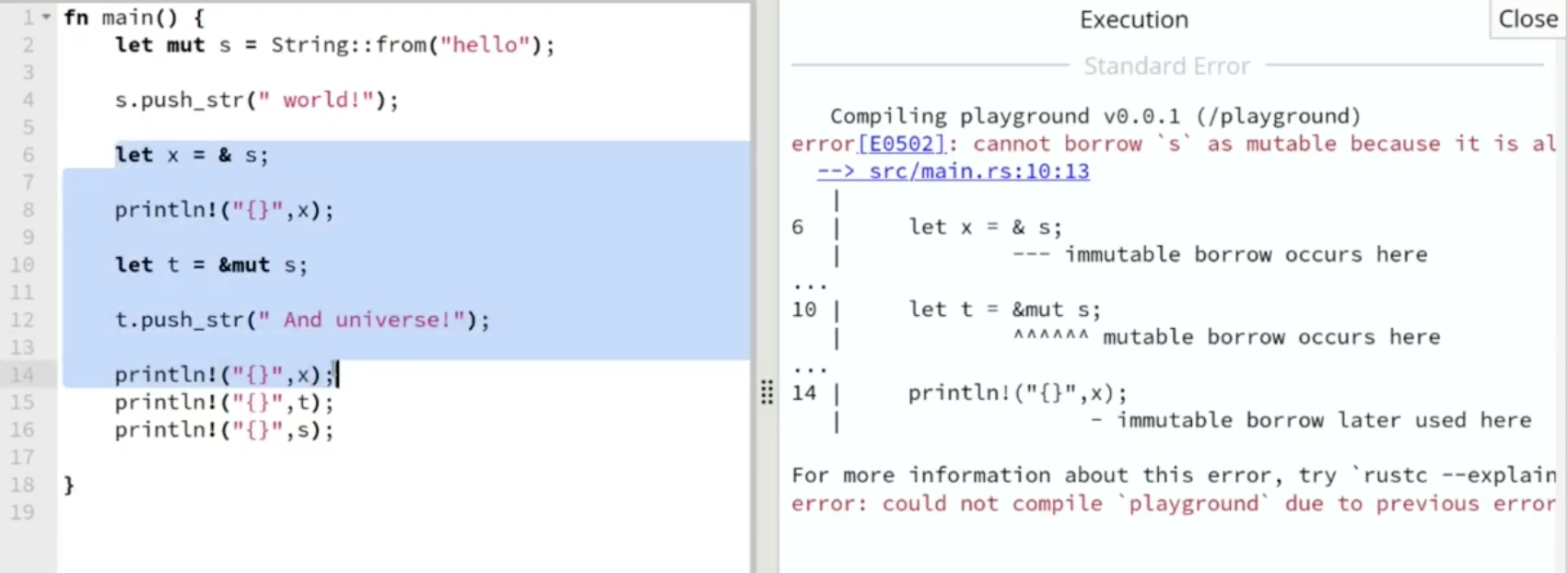
此时我们在第 $6$ 行声明了一个对变量 $s$ 的数据的 不可变租赁: 这意味着暂时借到了数据所有权的变量 $x$ 只具有对数据的 访问权限 而 不具备修改权限.
基于租赁 active 的定义可知, 上图中高亮段恰为这个不可变租赁的激活范围, 而右侧报错指明, 无法在这个不可变租赁内部对同一个数据进行可变租赁 (第 $10$ 行).
由此可知, 在执行可变租赁时, 我们可以安全地确保 只要此次租赁仍在激活范围内, 租赁数据所有权的变量就 恰为唯一具备对该数据修改权限的变量.
Rust 中租赁的生命周期
在 Rust 中, 租赁的生命周期恰为它的 激活范围. 考虑下面的例子:
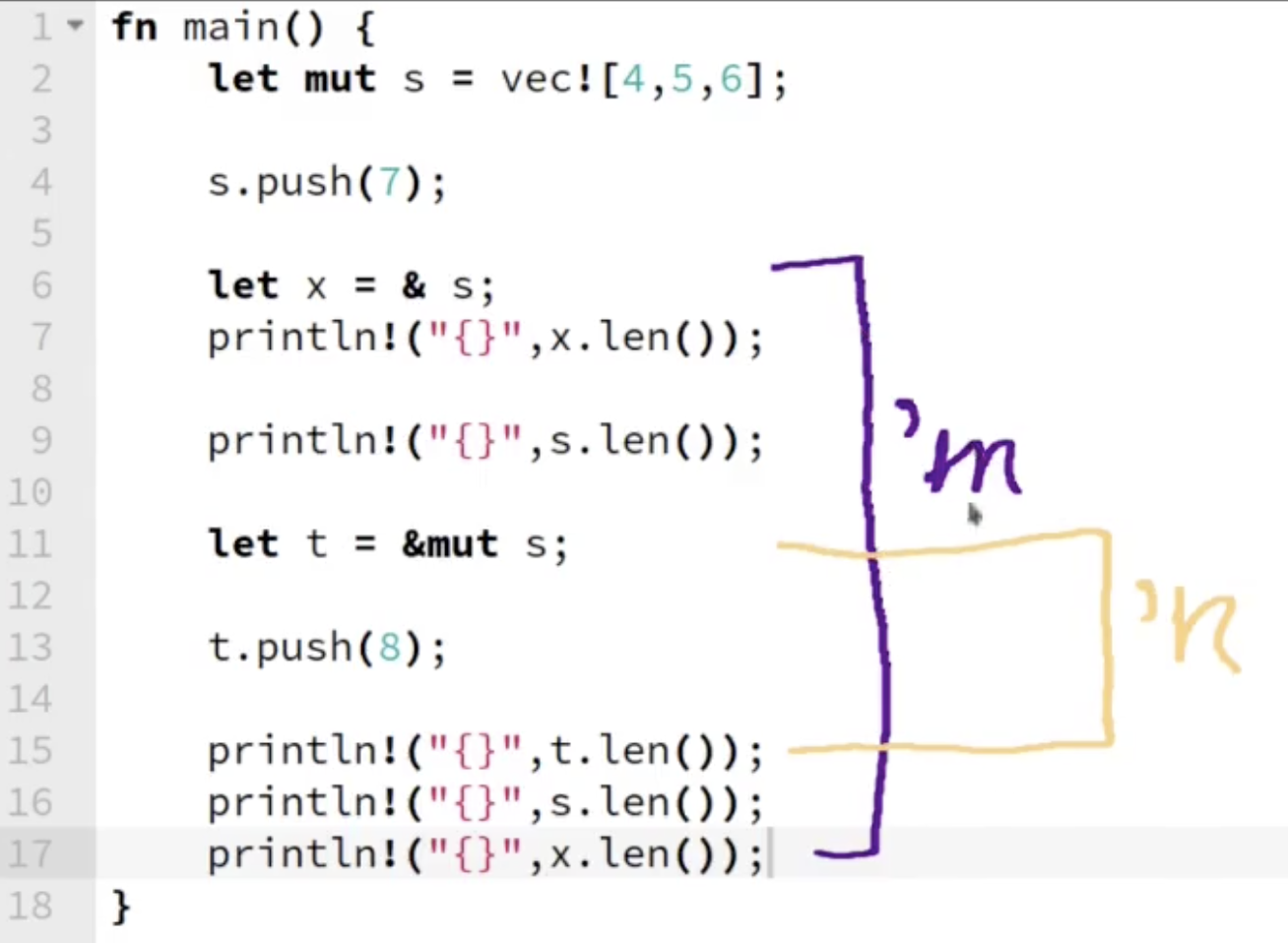
注意在 Rust 中, 我们使用 ' + 字母 的方式表示生命周期. 在上图所示的例子中, 对 $s$ 的不可变租赁的生命周期为'm, 而对 $s$ 的可变租赁的生命周期为 'n, 由于在 Rust 中, 可变租赁的生命周期 不能和其他任何租赁同数据的生命周期重合: “Mutable borrows are exclusive, though – a variable that is mutably borrowed can’t be used in any other way during the lifetime of the borrow.”.
解决方法是避免可变租赁的生命周期和其他租赁的生命周期重合:
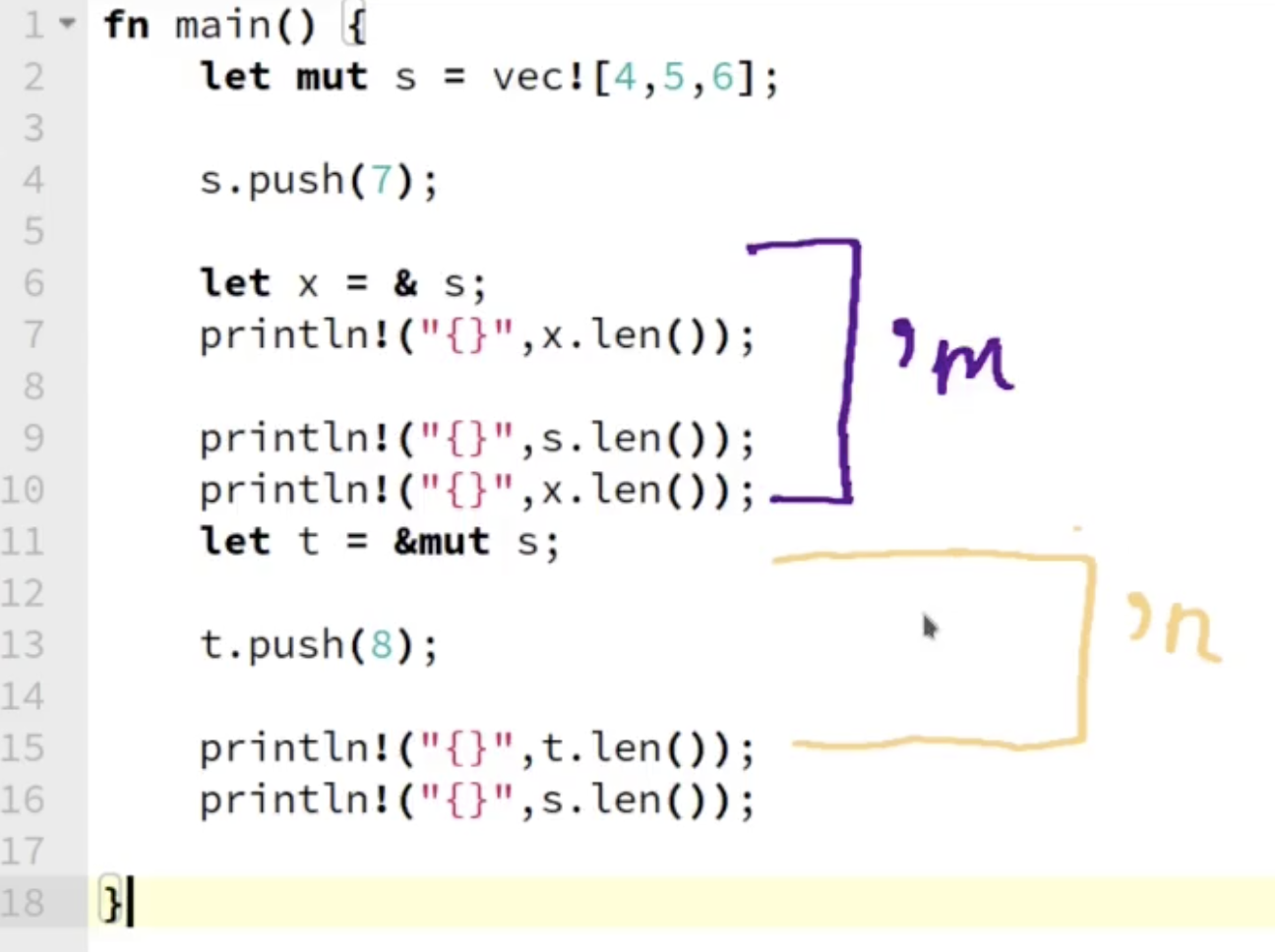
下面考虑更复杂的例子:
回忆在介绍变量的生命周期时我们提到过, 在 Rust 中我们可以使用中括号 {} 人为地构造代码段的域 (Scope).
考虑下面的例子:
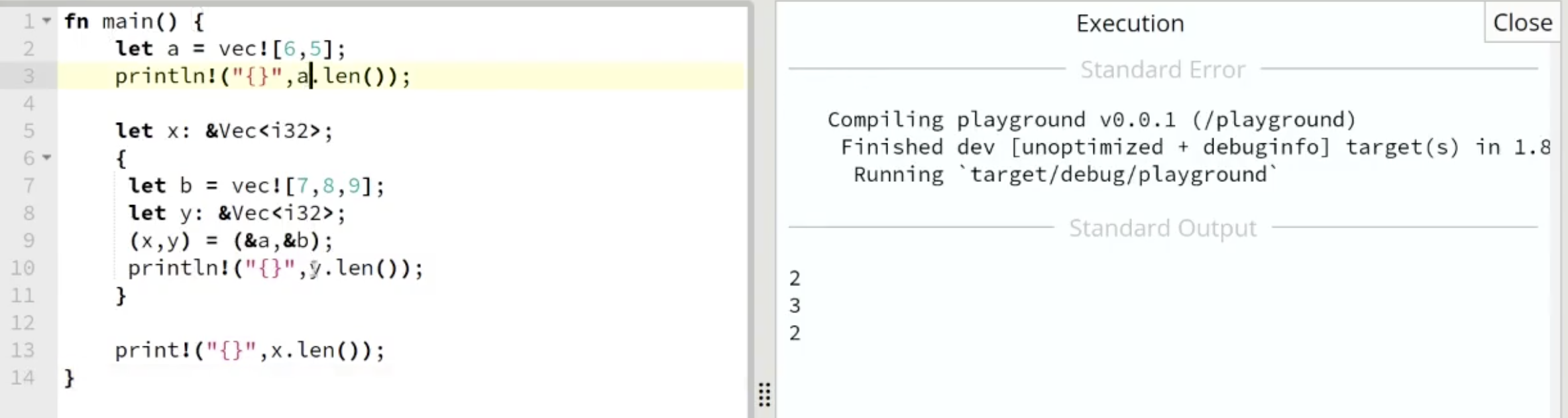
在上图中, a 被定义为一个长为 $2$ 的数组, 并且定义了 类型为对某个数组类型数据的引用的变量 x, 注意 $x$ 是且只能是引用.
不同之处在于, 从第 $6$ 行到第 $11$ 行之间的代码段被中括号 {} 隔离在了一个 单独的作用域中, 在作用域中我们额外定义了长为 $3$ 的数组 $b$, 以及另一个数组引用类型的变量 $y$, 并在第 $9$ 行应用了语法糖让 $x, y$ 分别 不可变地 借用了变量 $a$, $b$ 数据的所有权.
需要注意, 由于变量在脱离作用域后就会被回收, 因此在第 $12$ 行及以后的范围内 $y$ 和 $b$ 的内存空间都是被回收的, 但在域内执行的赋值操作仍然有效, 因此我们可以正常地在第 $13$ 行执行输出, 因为 $x$ 所引用的数据仍然在作用域内.
而若我们让 $x$ 借用数组 $b$ 的数据, 则会出现问题, 因为在 $13$ 行执行 $x$ 借用数据的输出时, $x$ 所借用的数据已经脱离了它的作用域而被回收.
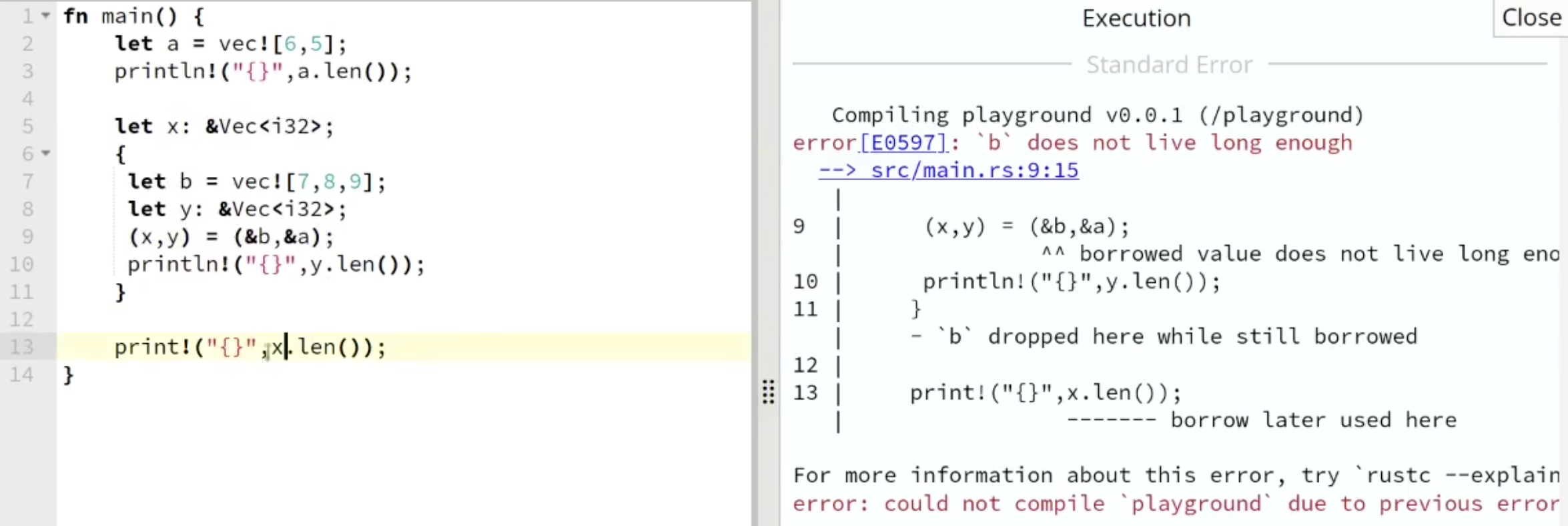 、
、
在上面例子的基础上, 我们考虑是否可以通过将引用内容藏在函数中对换从而骗过编译器摆他一道, 让本不该出现在作用域外的数据逃出作用域:
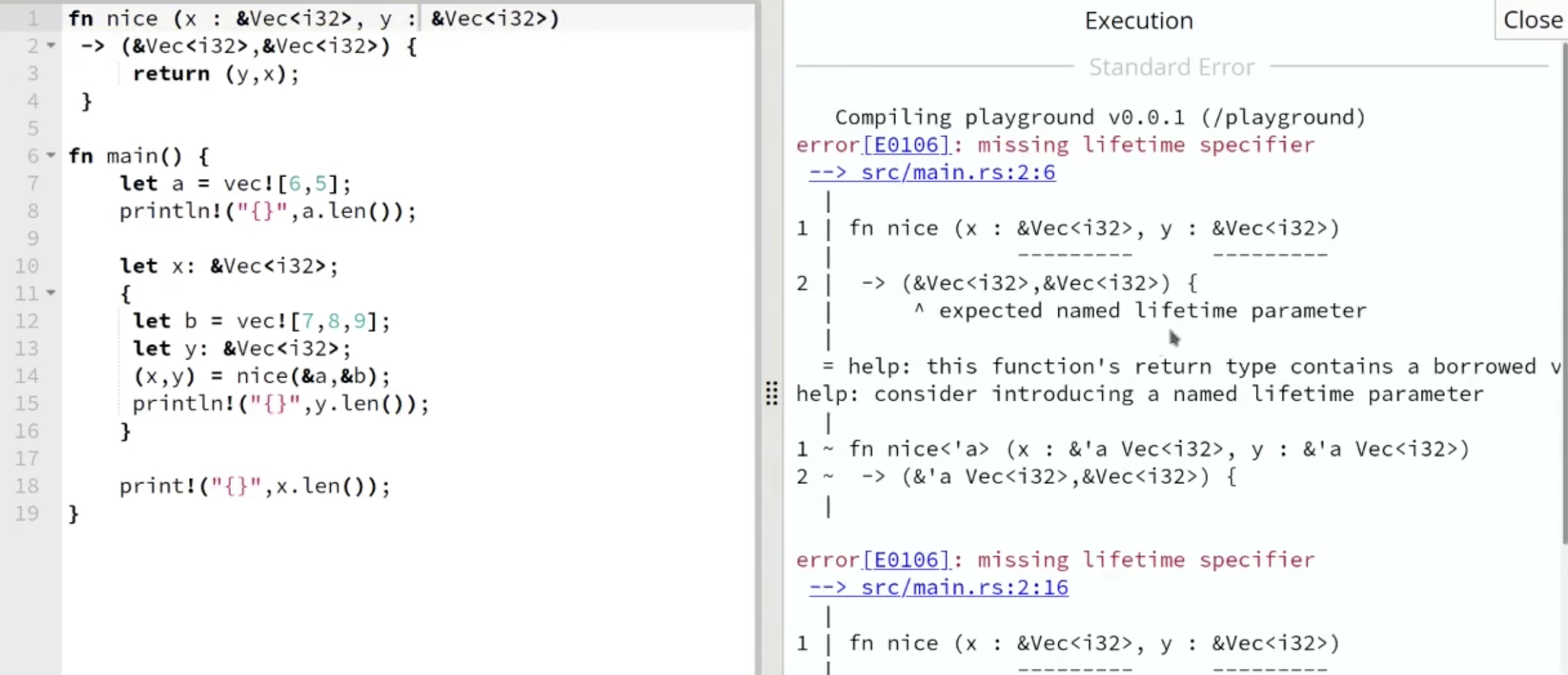
在上面的例子中, 编译器会直接报错: 要求我们为作为函数参数的每一个引用类型的变量都提供明确的生命周期.
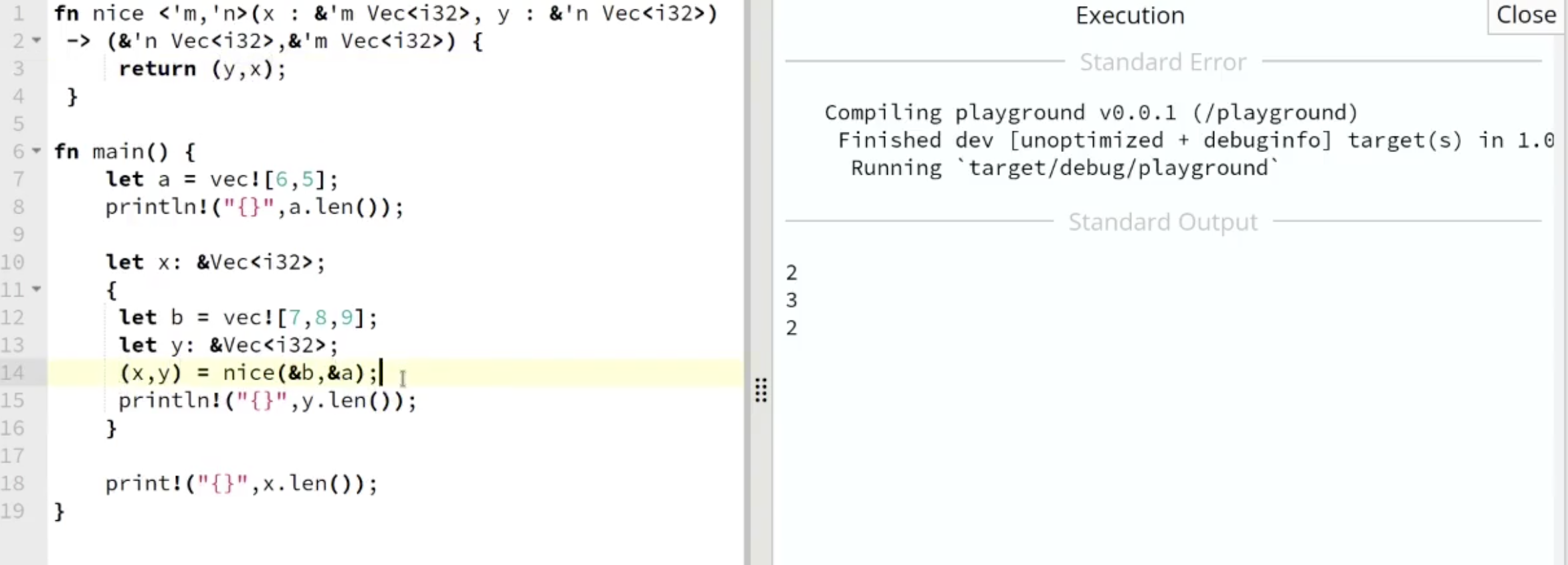
基于此前我们对 Rust 中生命周期表示法的介绍, 我们做了如上图所示的修改. 但由于我们将作为函数输入的两个引用 在函数定义中对换了一遍, 而在函数逻辑中 又对换了一遍, 负负得正毫无变化, 属于是被编译器摆了一道.
由此可知:
