
基于 Spring 框架的软件工程实践
Week1: MVC 架构模式
我们称程序的设计结构为 架构模式 (Architectural Pattern), MVC 就属于架构模式的一种.
MVC 意为 “Model, View, Controller”, 即 “模型, 视图和控制”. 在 MVC 中, 任何程序都在结构上被抽象成三个层级:
- 视图层: 程序的操作界面, 直接面向用户, 接受用户的指令并向用户显示信息, 负责人机交互.
- 控制层: 程序的核心逻辑, 连接一, 三两层, 负责基于所接收的用户指令执行实际的数据处理.
- 模型层: 储存程序所需
上述三层在功能上紧密联系, 但在结构上互相独立, 每一层只要对外提供对应的接口以供调用即可实现模块化.
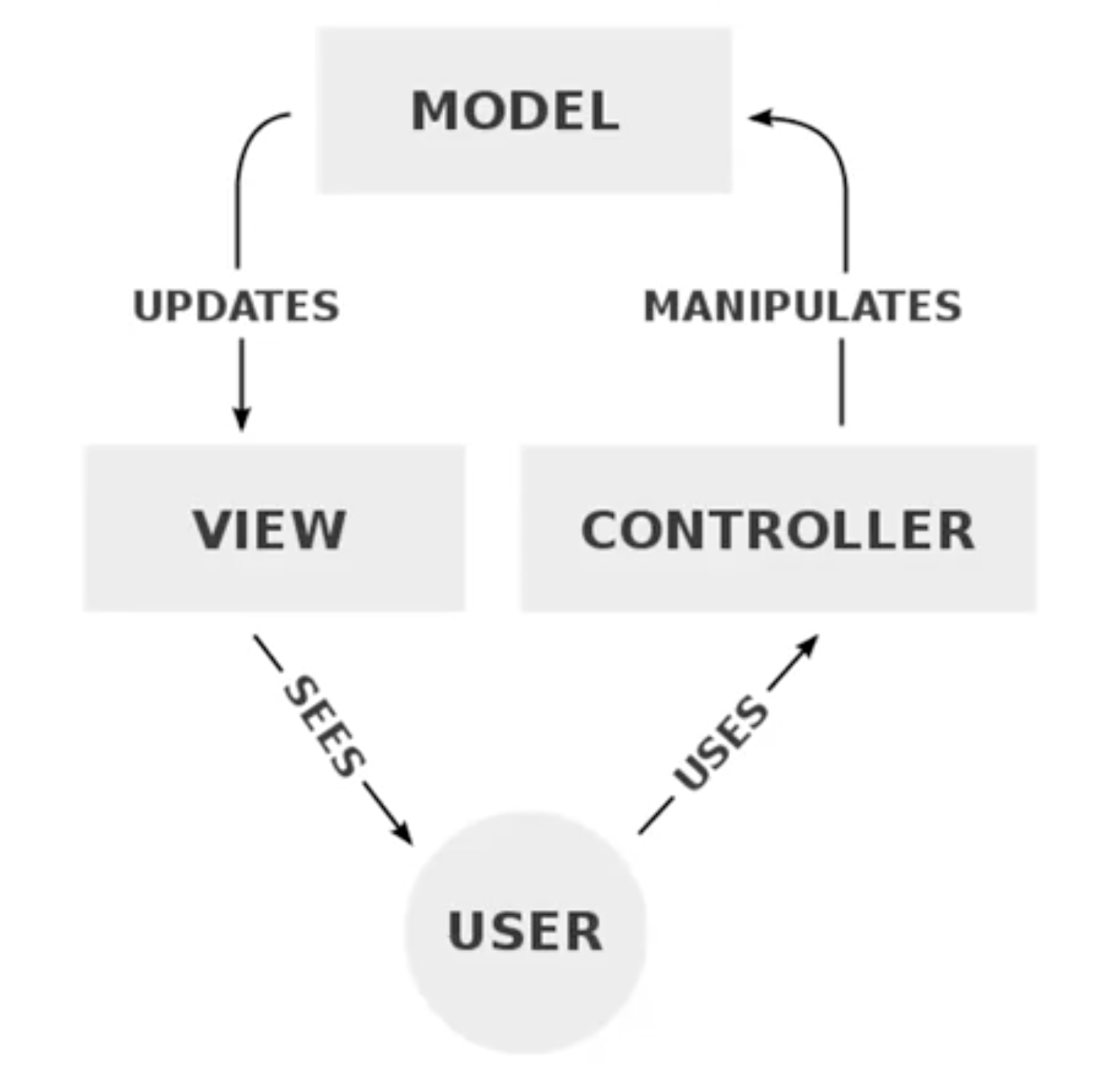
基于 MVC 的原始定义, 此外还需注意的是:
-
There should be a one-to-one correspondence between the model and its parts on the one hand, and the represented world as perceived by the owner of the model on the other hand.
-
A view is attached to its model (or model part) and gets the data necessary for the presentation from the model by asking questions. It may also update the model by sending appropriate messages.
-
The view will therefore have to know the semantics of the attributes of the model it represents.
-
A controller should never supplement the views, it should for example never connect the views of nodes by drawing arrows between them.
-
A view should never know about user input, such as mouse operations and keystrokes.
-
A controller is connected to all its views, they are called the parts of the controller.
-
Some views provide a special controller, an editor, that permits the user to modify the information that is presented by the view.
-
Such editors may be spliced into the path between the controller and its view, and will act as an extension of the controller. Once the editing process is completed, the editor is removed from the path and discarded.
(Editor “寄生” 在 Controller 和 View 之间, 可以修改 View 展示的内容, 用完即弃)
Week2: 设计用户界面
界面设计实质上是从用户需求向以设计为载体的最终成品的转化. 要着手进行设计, 首先需要理解用户需求.
对用户需求的理解可以从拆分需求中的 功能需求 (Functional Requirement), 即我们的程序必须实现的功能, 和 非功能需求, 如安全性, 程序性能, 易用性等尚未被明确作为需求的指标, 开始.
我们可以通过列举使用场景, 调查用户反馈, 将设计可视化等方式抓住需求的核心并检查/修补设计中可能存在的缺陷以及对需求的误解. 需要注意, 相同的需求有多种不同的实现方式, 因此在设计用户界面时无需拘泥于某个特定的模版或结构.
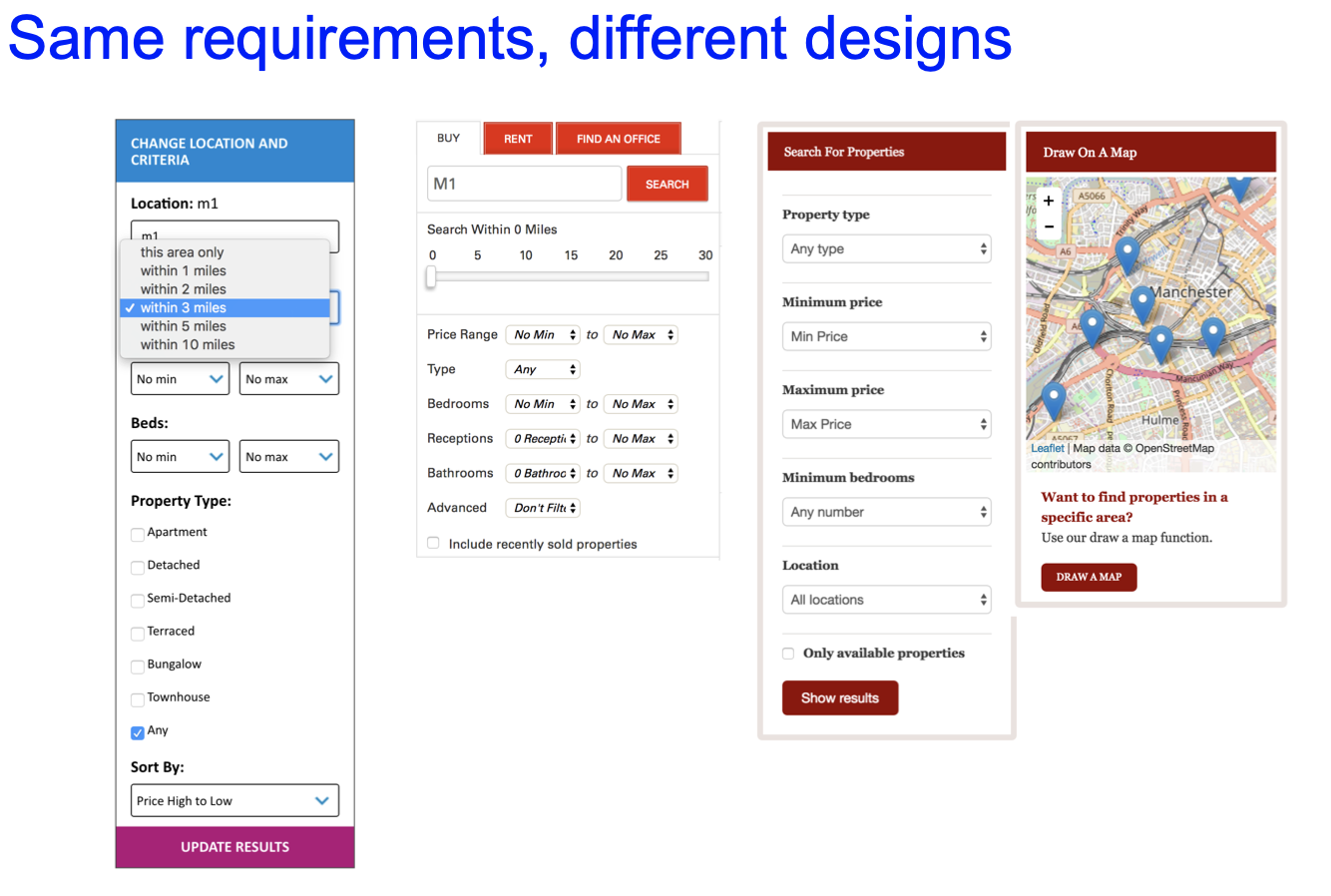
可见, 上述的不同界面都提供了相同的功能: ”Establish an area where user can search a property“.
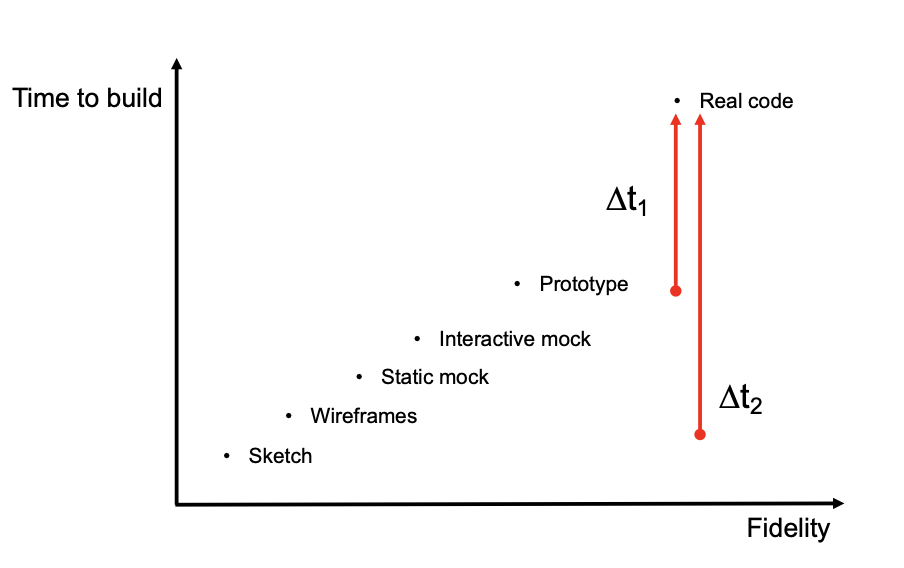
在将需求转换为最终设计的过程中, 我们的设计一般会随着对需求理解的逐渐深化和调整而变得愈发精确. 一般地, 用户界面设计会自底向上地经历下列的四个阶段:
- 草图. 它一般作为线框模型的草稿, 展示最初始的设计大纲, 不具备正式性, 但也是一种有效表达想法的方式.
- 线框模型 (
Wireframe). 相比草图, 线框模型更加正式. 它被用于模拟和规划界面元素的编排, 在这一阶段下界面板式和涉及元素被基本确定. - 样板模型 (
Mockups). 样板模型在形式上最接近于实际成品, 它在线框模型的基础上包含了界面设计所需具备的样式, 基本上就是实际设计的静态展示. - 原型 (
Prototype): 原型相比样板模型加入了基本的操作逻辑, 允许动态的用户交互, 实际上最接近于成品.
一般地, 程序设计的精确度越高, 所需要消耗的时间也就越多. 理想情况下, 大部分的时间应当被用于实现程序逻辑, 而非浪费在原型或可交互化样板模型的开发上.
我们下面对实物展示环节 (mockups) 存在的意义简单的总结:
- 我们可以在此过程中通过与客户进行交流确保我们的设计符合用户需求, 且可以在此过程中交换意见, 并为客户提供不同的选择.
- 我们可以利用这一过程及时消除设计和实现所存在的缺陷以及对用户需求的误解.
- 我们可以使用自顶向下地方法从用户需求中提取对应的任务.
下面介绍用户界面设计的八条黄金原则:
- 确保用户界面设计的一致性 (
Consistency). - 确保用户界面对绝大多数的用户群体而言都具备足够的易用性 (
Usability). - 用户界面所提供的任何反馈都应能提供有价值的信息.
- 为用户界面中的任何操作流程提供引导, 在流程结束时提供流程完结的反馈.
- 尽量避免用户执行错误操作的几率, 并确保在操作错误时提供合理的反馈.
- 提供明显的方法允许用户撤销操作.
- 为用户提供掌控感, 通过确保设计符合直观确保获得用户信任.
- 减少用户的短时记忆负担, 确保界面设计足够简洁.
Week3: 数据建模
本节介绍 Spring 的数据建模和数据持久化.
模型 (Model) 是用户在使用应用程序时所生成/需要调用的数据或方法, 它是基于 MVC 架构的程序中的核心组成部分. 下面讨论如何在 MVC 程序中构造和持久化某个模型.
1. 基本数据建模
我们下面考虑本课程小组项目中涉及的概念: Venue, 即事件发生的地点. 使用 Plain Old Java Object
对其建模的效果是:
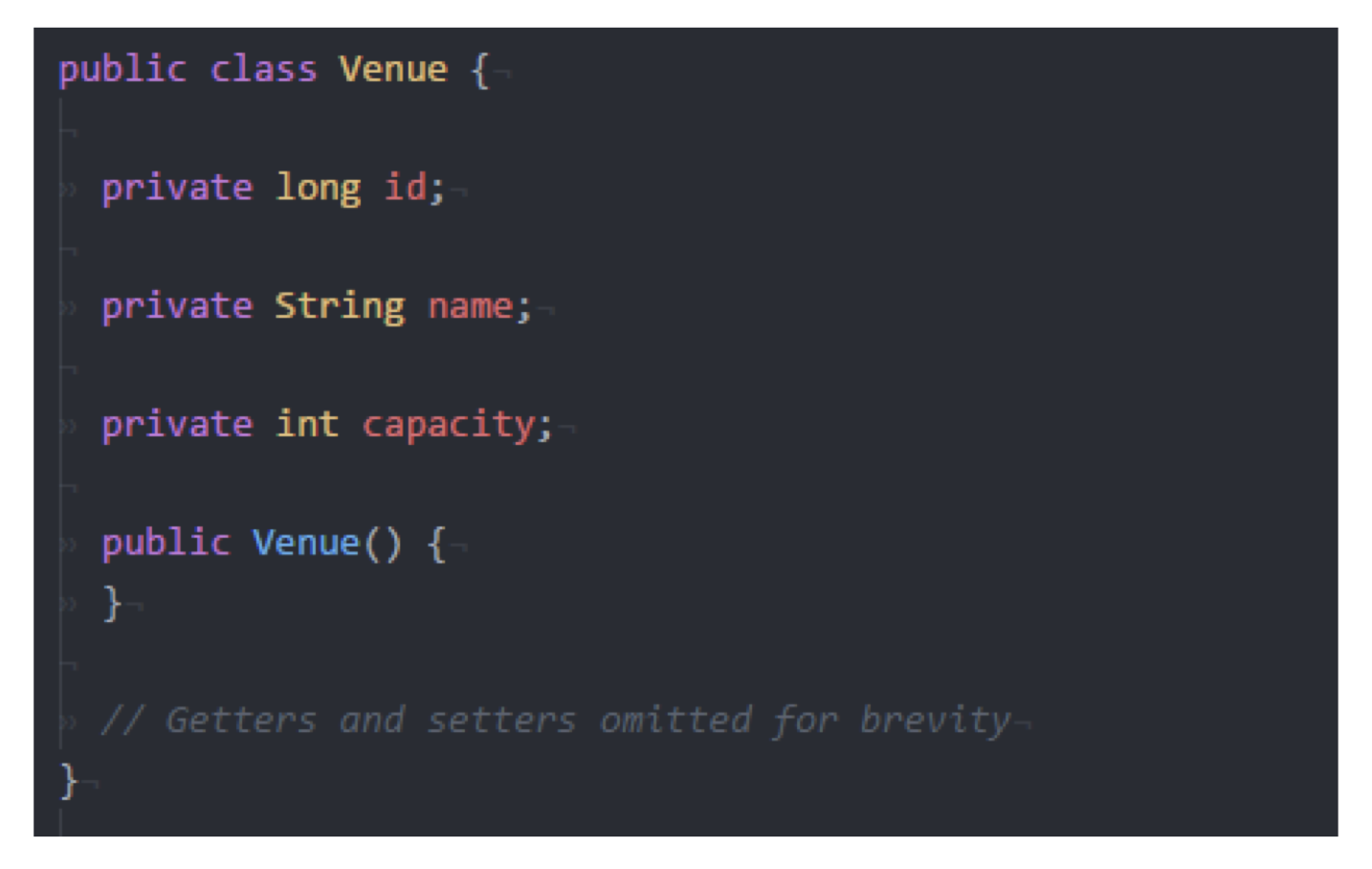
注意: 变量域需要设为 private, 必须有一个向外界暴露的构造器, 且变量的 getter 和 setter 的命名需要和 Spring 的常规一致, 如: getId(), setId(), 只有通过这种方式才能确保 Spring 知道你写的是什么.
要确保 Spring 知道如何将 Venue 对象存储到数据库中, 我们需要为这个类加上一些 标注 (Annotation):
- 使用
@Entity标注说明我们希望这个类作为数据库表的基础 (base). 每个该类的实例都将作为数据表的一行存储在数据库中. - 使用
@Table标注说明我们希望这个表的名称是什么: 在本例中它被标注为 “venues”.
在下面的例子中, 经过这样的标注, Spring 会生成一个名为 venues 的表, 自动构造出表结构分别存储 id, name 和 capacity, 并自行处理数据的序列化和反序列化.
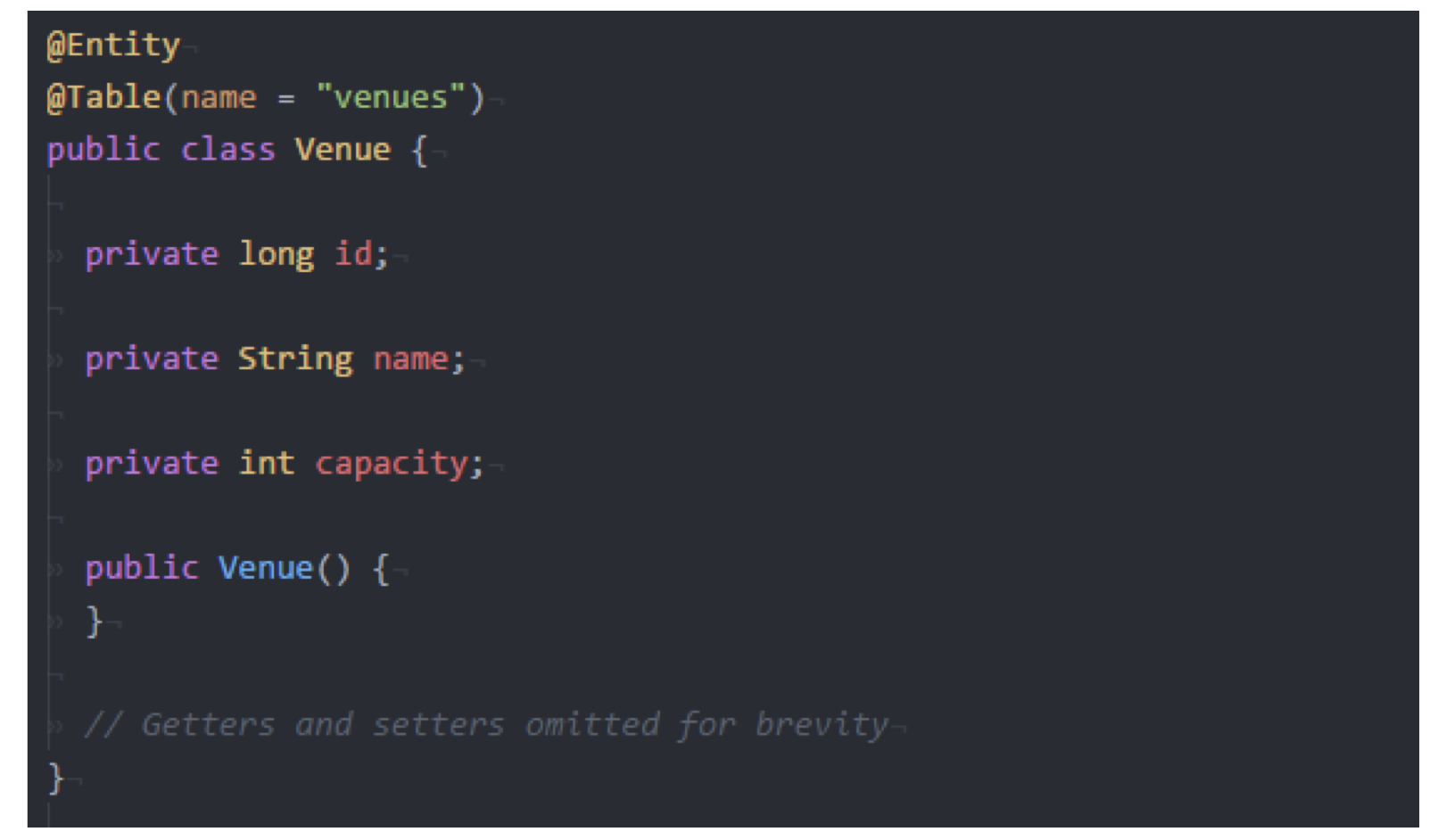
此外, 我们可以使用 @Id 标注该表的主键, 还可以将 @Id 与 @GeneratedValue 标注一起使用 (in conjunction with) 令 Spring 在这个模型被存储时自动生成主键.
2. 数据关系
我们接下来讨论数据关系. 在 Spring 中, 可以使用下列的标注表明对象之间的数据关系:

3. 数据存取架构
在完成对模型的建模, 确立了它和其他实体之间的关系后, 我们下一步需要考虑的问题是如何从 Spring 自动为我们创立的数据库中存取 (Storing and Retrieving) 信息.
下面介绍 Spring 的数据存取架构. Spring 在数据库和实现程序逻辑的 Controller 之间建立了抽象层, 因此我们无需关系数据库的具体实现.
在 MVC 架构中, 对数据的处理逻辑位于 Model 部分中, 而在 Spring 中数据处理逻辑独立于用于隔离数据库的抽象层而存在.
注: DAO stands for Data Access Object. It’s a design pattern in which a data access object (DAO) is an object that provides an abstract interface to some type of database or other persistence mechanisms.
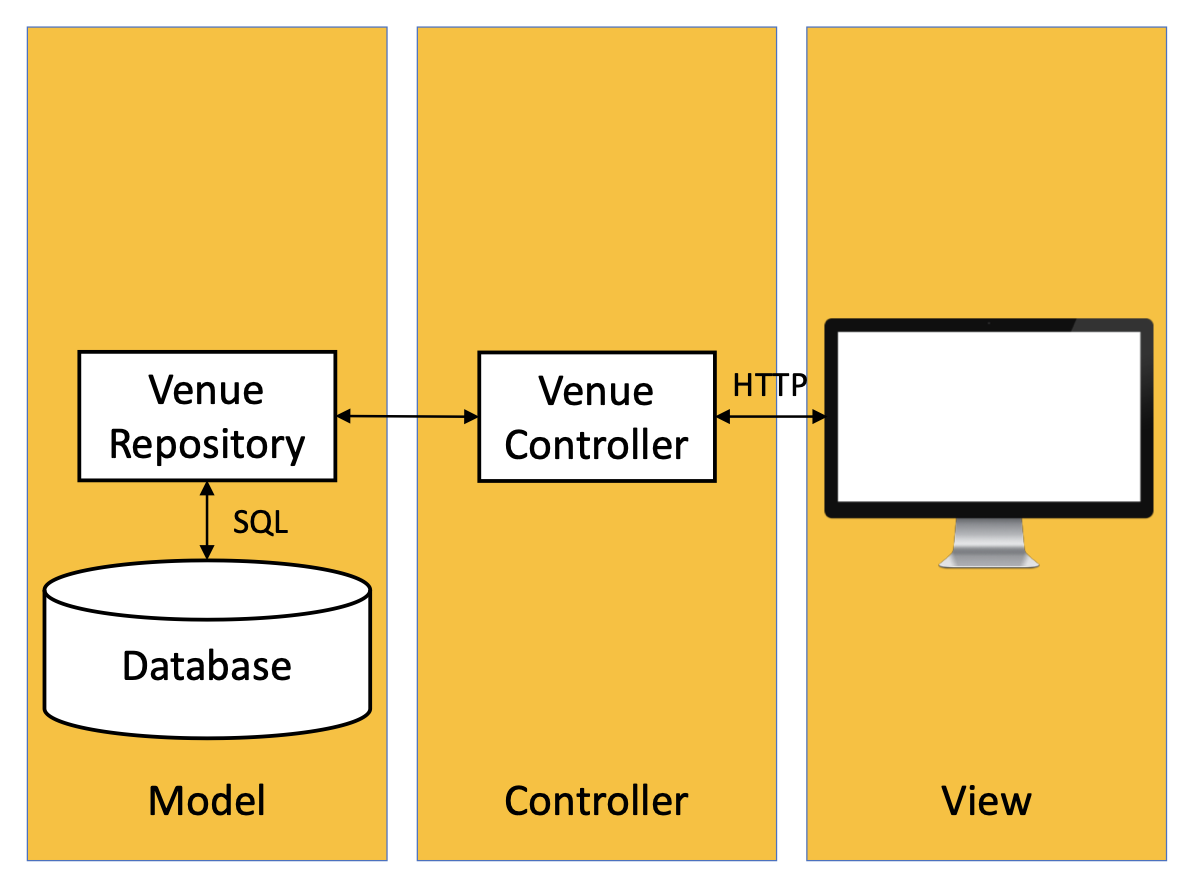
因此, Spring 将 Model 进一步拆分成负责数据库实现与数据库存取指令抽象的 Repository 层和负责数据的处理逻辑的 Service Layer 层.
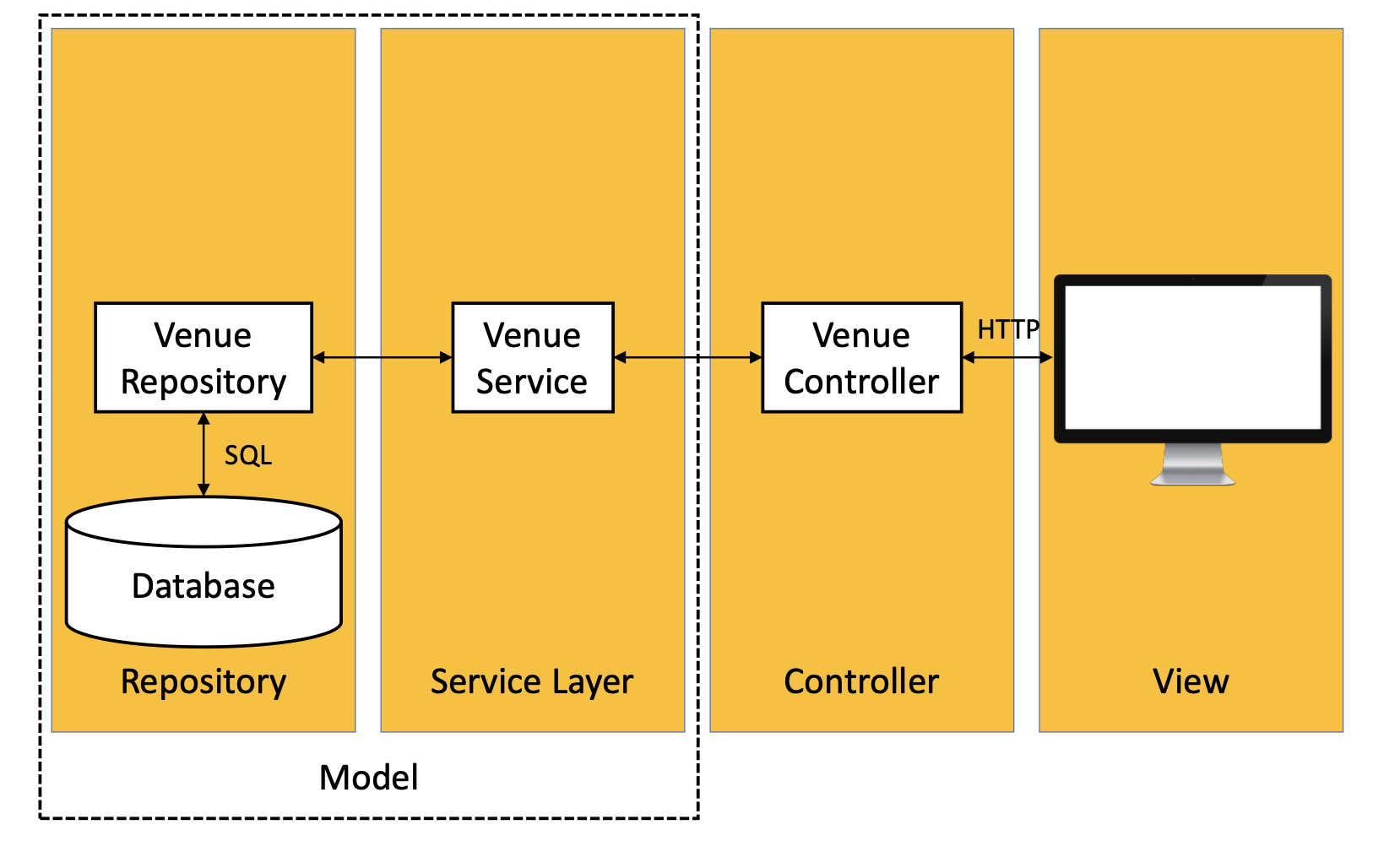
需要注意:
-
Spring充分利用Interface标记不同类型. 由于我们无从得知Spring在Repository中对数据库的抽象, 即Venue Repository Impl是如何实现的, 我们使用@Autowired标注让Spring自行基于我们构造的Interface寻找到合适的实现. -
在
Service Layer中, 我们同样使用一个Interface来控制Repository层向Controller暴露的方法有哪些, 而这样的架构会在每一个存储于模型中的实体上应用, 因此在我们的例子中它除了出现在Venue实体上, 还会应用在Events上. -
我们可以通过这种方式控制每个实体类型所可使用的操作, 甚至可以为不同的实体类型分配不同类型的数据库.
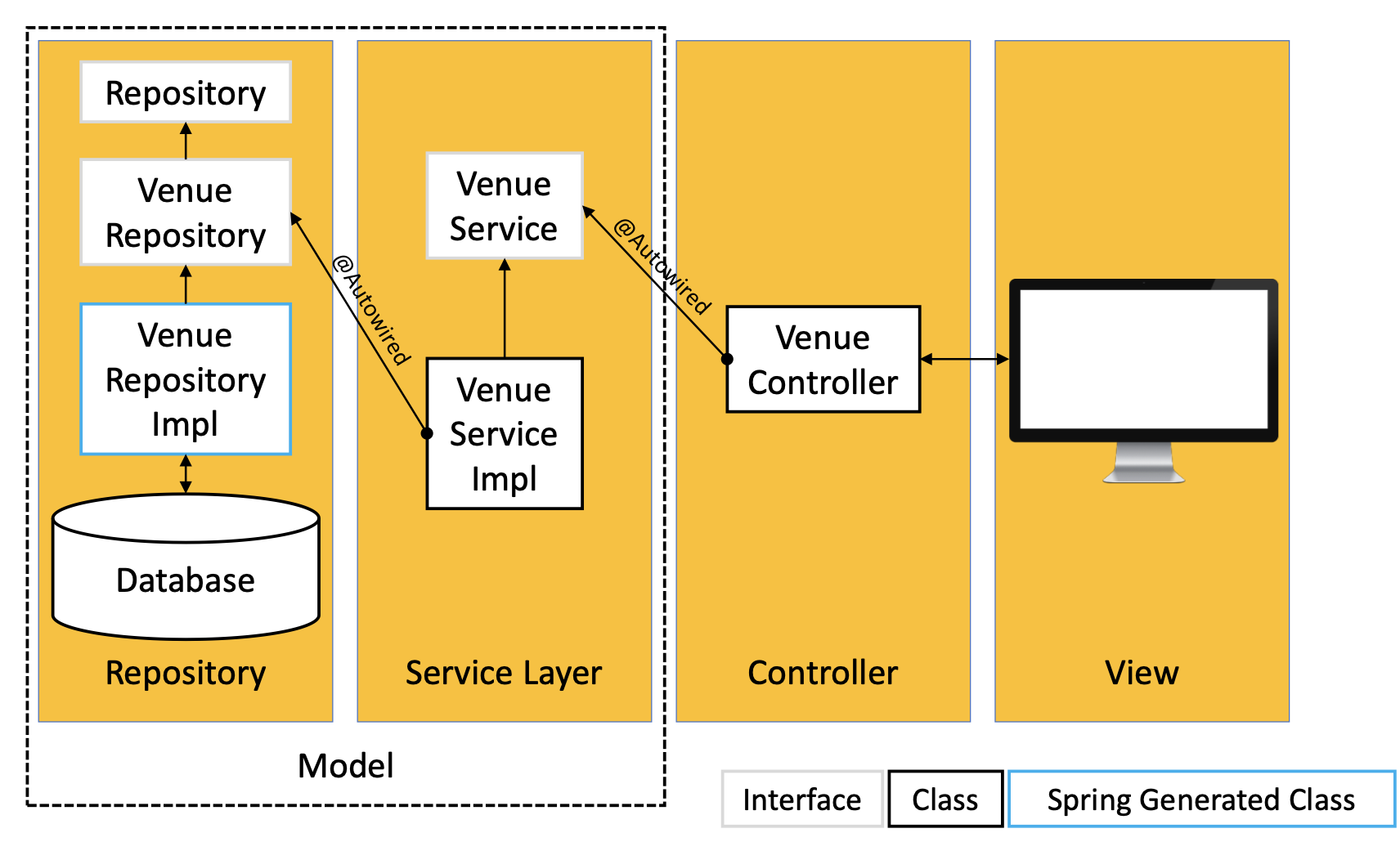
下面讨论如何定义 Repository, 并且简单介绍 Service 界面的基本特征.
Spring 提供了多种 Repository 实现, 如:
1
2
3
4
5
public interface VenueRepository extends CrudRepository<Venue, Long> {
// CRUD: create, read, update, delete
// Note: `Venue' is the entity type that we want our repo to store
// `Long': the type of the entity's primary key
}
我们只需要声明这样的 Interface, 即可构造出 Venue 实体的 Repository. 这样的模式也被称为 Marker Interface: 它相当于告知 Spring 自动为对应的实体生成具体的实现.
默认情况下, 该实现会为我们提供下列的预定义方法:

而我们只需要为 Venue Repository 定义一个 Marker Interface 就可以得到这一切, 无需多写半行代码.
我们也可以在这个 Marker Interface 中定义其他的自定义方法, 如:

需要注意: 这些自定义方法均遵循 Spring 的自动转换规则, 能够将这些符合条件的空方法转换成预置的具体实现.
此外, 这些方法的参数类型和返回值类型都需要和相关的对象的类的变量域的类型保持一致.
在第四周的小组项目任务中, 我们可以利用 findByNameContaining() 方法.
我们最后讨论如何通过 Service Interface 查询数据. 该层的存在意义在于:
- 将具体的数据操作逻辑和
Repository层隔离. - 即使我们希望重定义查询语句的功能或封装较为复杂的数据查询操作, 我们也同样不希望这些实现被放在
Controller层中破坏不同功能层间的隔离性. - 控制哪些方法被直接暴露给
Controller.
在下面的例子中, 可见 findAll() 方法被直接暴露给 Controller. 而若我们只希望返回经过字母顺序排序后的搜索结果, 我们就可以重新定义 findAll() 方法来实现这一点. 这样, 我们就可以实现逻辑隔离并确保 Controller 尽可能地简单.
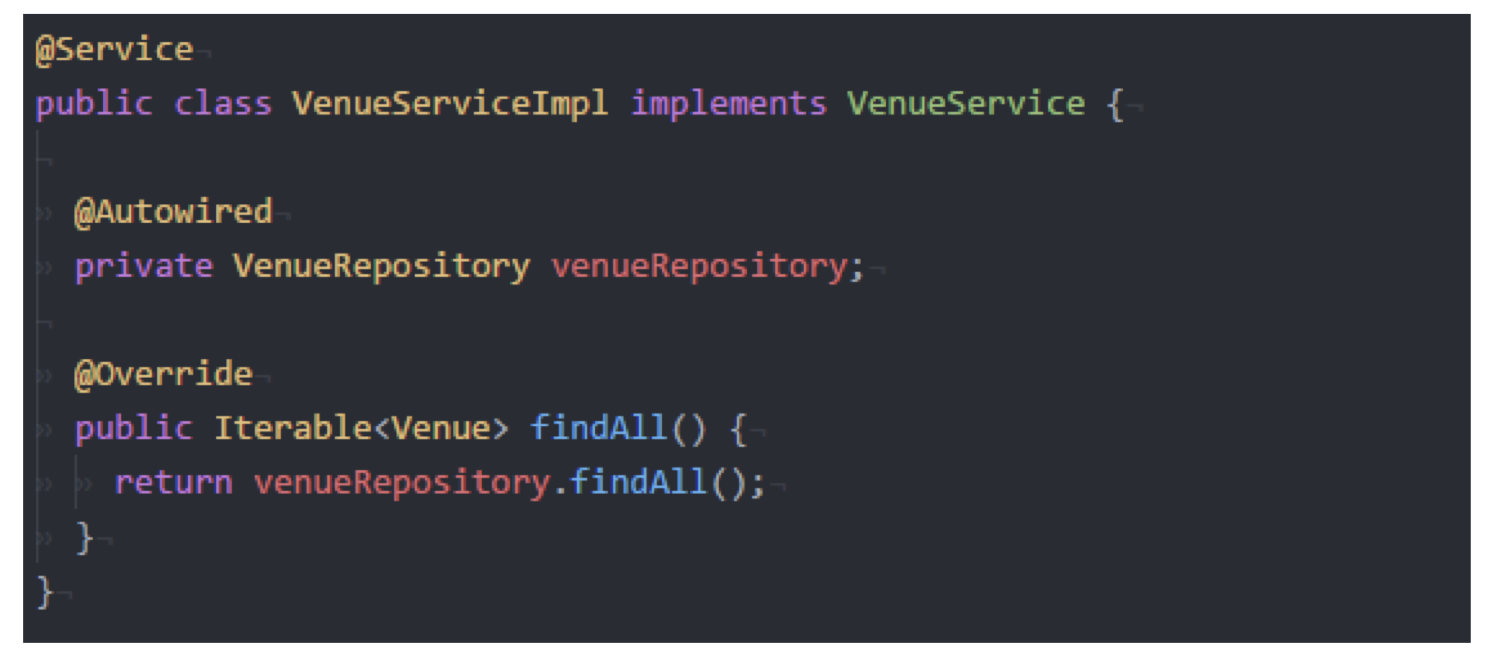
最后补充一些其他的 Annnotations:
Bean 相关:
@Autowired: 自动导入对象到类中.@Component,@Repository,@Service,@Controller: 负责将类标示为 可用于@Autowired注解自动装配的类, 分别是: 通用注解, 和数据库相关的DAO层, 服务层 和 控制层.@RequestController: 表示被注解的是Controller Bean, 自然位于Controller中.
对 HTTP 请求的处理
@GetMapping和@PostMapping: 实际上等价于方法分别为GET和POST的@RequestMapping.@PutMapping和@DeleteMapping: 实际上等价于方法分别为GET和POST的@RequestMapping.@RequestMapping: 处理映射请求, 将view发送到后端的Request和Controller绑定, 出现在Controller中.
前后端传值
-
@RequestParam和@PathVariable: 用于 前后端传值, 前者提取和解析请求中的参数, 后者用于获取路径参数, 都出现在Controller中. -
@RequestBody: 用于读取Request请求的body部分且格式为json的数据. -
@ResponseStatus: 用于修饰一个类或方法, 一般修饰异常类.当其方法被调用时, 指定的状态和错误原因会被返回到前端, 出现在Controller里.
数据操作相关
下面的字段都出现在 Model 中:
@Entity: 声明一个类对应一个数据库实体.@Table: 设置表名.@Id: 声明一个字段为主键.@Column: 声明字段.@Transient: 声明 无需和数据库映射 的字段, 在保存时不需存入数据库.@OneToOne: 声明一对一关系.@OneToMany: 声明一对多关系.@ManyToOne: 声明多对一关系.@ManyToMany: 声明多对多关系.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
@Entity
@Data
@NoArgsConstructor
public class Person {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(unique = true)
private String name;
private Integer age;
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
}

Week4: 数据安全和隐私
本节讨论网页程序的数据安全与用户隐私问题.
我们首先明确在网页程序的讨论范围内, 需要被保护的东西是什么: 一般地, 我们需要妥善保护包括用户信息, 程序文件等在内的实体资产和公司声誉等无形资产.
我们其次明确为了保护资产, 所需要对抗的对象是什么. 可能的威胁或攻击者可能是半桶水的脚本小子, 心怀不满的竞争者, 想捡大漏的用户甚至奇妙深刻的境外势力.
一般地, 这样的设计模式被称为 Security-By-Design Approach, 设计步骤分为:
- Identify Assets
- Perform Threat Modeling
- Choose Mitigation Techniques
- Design and Test
潜在的安全威胁种类无法估量. 下面是2017年排名前十的安全威胁类型:
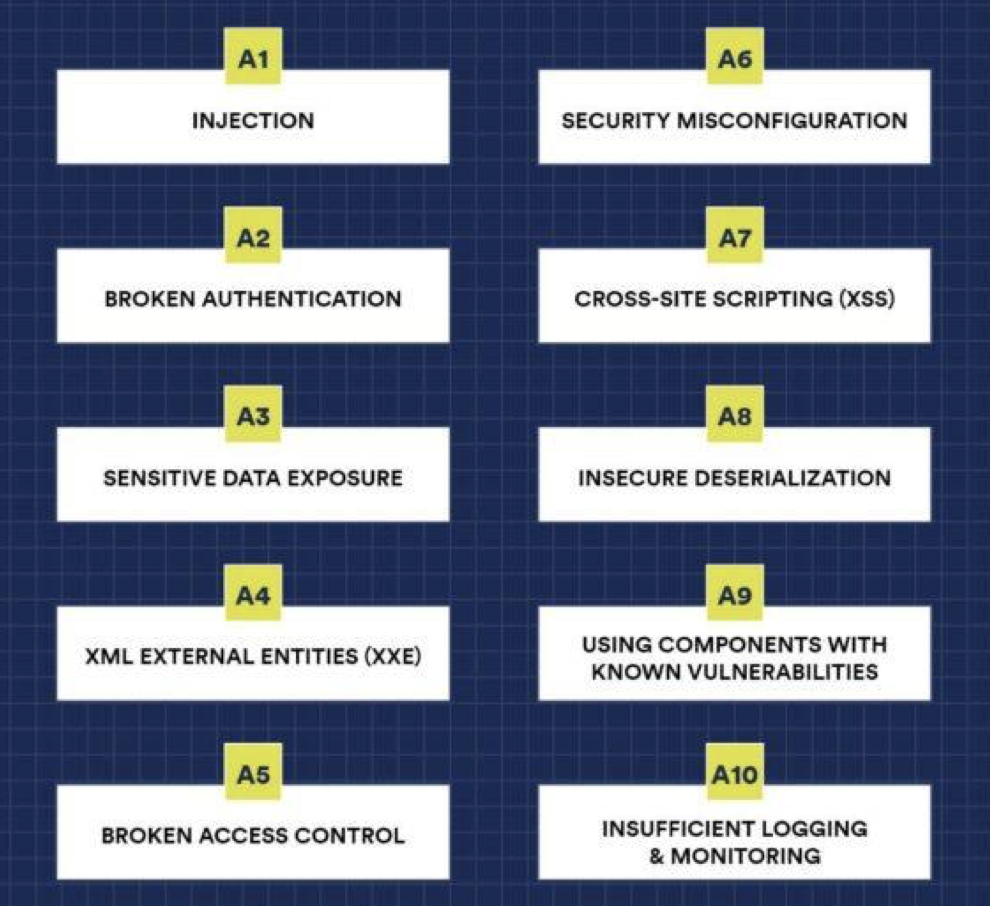
在此之中, 我们主要讨论 功能残缺的身份验证 和 注入攻击.
1. 身份验证
首先给出 身份验证 (Authentication) 的定义: 我们称确认用户身份的过程为身份验证, 它所预防的是 欺骗身份攻击 (spoofing identity attack).
其流程是: 将用户所提供的身份验证信息和存储在安全数据库中的信息进行比对, 只放行能够提供可以在数据库中匹配的安全信息的用户.
基本上, 身份验证信息的构造基于三个可能的思路: Who we are , What we know 和 What we have. 例如:

我们下面以当前仍然最为常见的 用户名-密码 验证方式为例讨论其安全性.
最简单的实现方式是将密码 明文存储 在后端数据库中. 其安全风险是: 一旦后端数据库发生信息泄露, 掌握数据库的恶意一方可以立即获得所有的用户信息并获得对账户的完全掌控权.
改进的实现方式是在前端使用哈希函数将密码进行哈希编码. 由于实现合理的哈希函数具有单向性, 因此恶意方及时掌握了泄露的数据库数据也基本不可能从哈希值入手反向计算出实际的用户密码.但这一方法仍然存在风险: 由于作为哈希函数输入的密码尚未进行任何处理, 因此 相同的密码将会以相同的形式存储在数据库中. 因此攻击者即便难以从数据库得知明文密码, 他们仍可以得知 ”不同用户使用了相同的密码“ 这一信息, 而它可以作为破译密码的入手点.
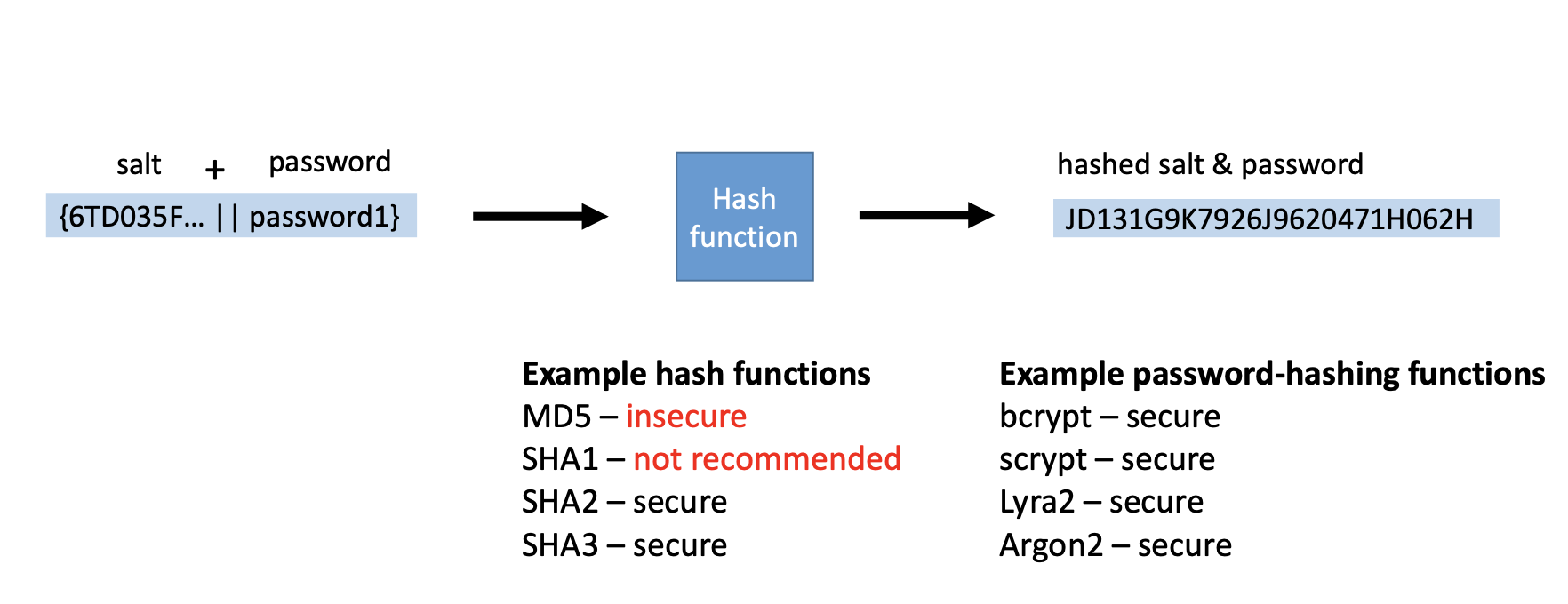
因此为了确保安全, 我们需要在前端对用户的密码进行 哈希加盐. 其实质是: 对每个用户我们存储一段与之对应的 盐值 (Salt), 而安全数据库中所存储的信息则是 盐值和明文密码以及用户名连接后作为哈希函数的输入所计算出的哈希值.
盐值一般是 一一对应于每个密码 的, 重复使用相同的盐值会降低安全性. 一种常见的做法是: 将 明文密码本身哈希值中的固定几位 作为它对应的盐值, 和明文密码与用户名拼接之后执行第二次哈希, 再把得到的结果送进数据库里存储或匹配.
2. 授权
下面讨论 授权 (Authorisation) 的安全性问题.
我们将 授权 定义为: 指定对特定资源的访问权限的过程, 它主要防护的是 提权攻击 (Privilege Escalation Attacks).
我们一般使用 基于身份的认证 来实现授权保护. 常见的用户身份及其权限等级为:

3. 注入攻击
随后我们讨论注入攻击:
我们定义注入攻击为 攻击者通过注入不受信任的输入并使这些输入作为查询或指令执行 的行为.
常见的注入攻击有 CSRF (跨站请求伪造), XSS(跨站脚本漏洞) 和 SQL 注入等. 导致注入攻击能够成功的一半原因是站点并未实现完善的用户输入验证.
因此, 避免注入攻击最有效的方法是: 坚持 永远不要相信用户端输入 的原则, 尽可能多地对用户输入进行 限制, 控制 和 监测 (Restrict, Control, Monitor).
4. 在基于 Spring 的网页应用程序中应用安全原则
作为功能完善的后端框架, Spring 提供了对主流 Web 安全实践的完整支持:

在小组项目所涉及的 Web 应用程序中, 安全性设置受 config 包中的 Security 类所控制. 在该类被 @EnableWebSecurity 标注时, 其安全系统会被启用, 并且我们可以在 WebSecurityConfigurerAdapter 类中重载相关方法以微调安全设置.
当前, 网页应用程序的安全设置是:

我们可以使用下列的方式新增/调整用户权限等级, 并调整哪些页面和指令不受安全系统的监视:

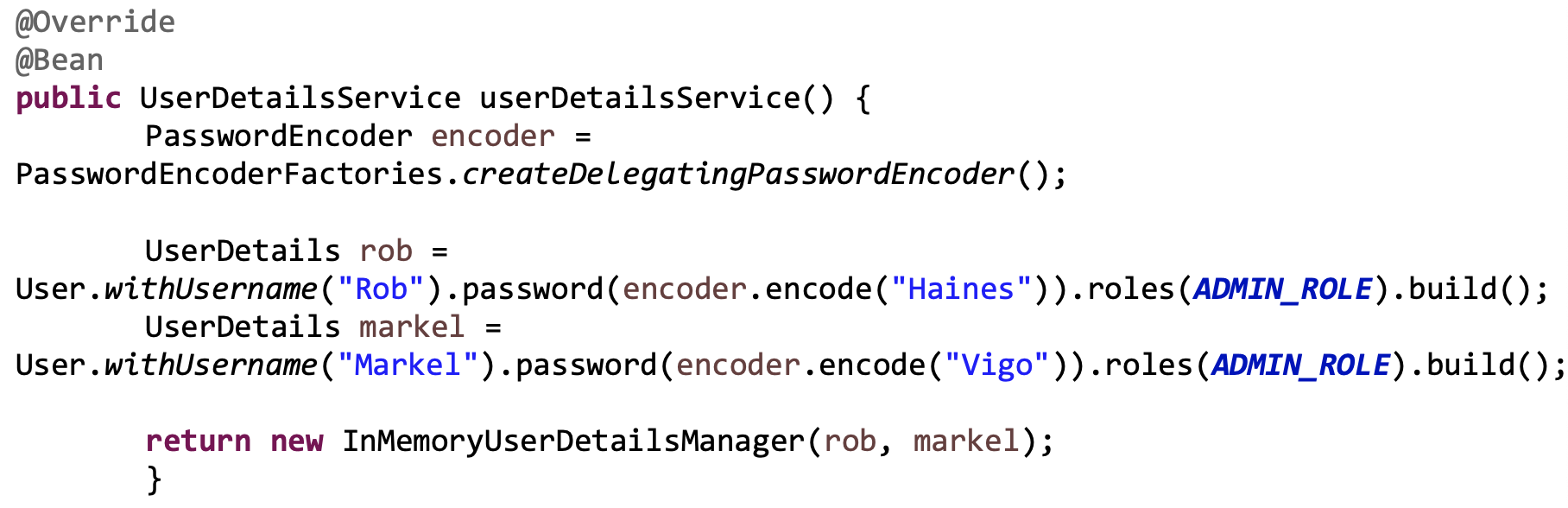
负责登录/登出的代码段:

负责用户信息存储的代码段:
5. 用户隐私问题
我们下面讨论用户隐私问题. 回顾安全威胁排名, 不难看出和用户隐私息息相关的 “敏感信息泄露” 问题位列第三, 因此用户隐私同样是我们需要关注的重点.
“敏感信息” 包括身份信息 (如身份证号, 家庭住址, 户籍信息等), 其他隐私信息 (如健康状况), 财产信息(如银行卡号, 信用卡号, 银行账户), 身份验证信息 (如用户名, 密码等). 这些信息都需要被妥善保护避免泄漏.
为了避免用户敏感信息泄露, 我们可以遵循 Hopeman's Eight Privacy Design Strategies:
-
简化: 尽可能地在程序的流程中 减少对用户个人信息的处理. 只要我们从一开始就不收集敏感信息, 就不会有敏感信息的泄露问题.
如: 不收集无需收集的数据: 视频网站无需收集用户的身份证号, 文件转换程序无需收集访问者的ip地址. 程序可以定期清除非活跃用户的数据, 而无需将它们和其他用户的数据一同存储.

-
隔离: 在逻辑上和物理上隔离对用户信息的处理, 人为地制造攻击者整合个人信息的难度.
如: 将用户的个人信息和会员信息分别存储在不同的物理机上, 而非在一台服务器上同时存储.

-
抽象化: 尽可能地去除受处理的用户信息的指纹特征. 我们所处理的用户信息越模糊, 隐私风险就越小.
如: 网站只需要知道用户是否大于 $18$ 岁, 而无需知道用户的生日; 我们可以将年龄层次相近的用户统一划分为一组处理, 这样即使信息泄露我们也不知道这组用户中具体都有谁.

-
隐藏: 确保用户信息不被公开, 并确保用户信息不可被关联. (
Unlinkable)如: 将用户数据以加密形式存储; 禁止对个人信息的未授权访问; 在逻辑上而非物理上 将用户的个人信息之间的关联打散.

-
告知: 在合适的时间和场合主动告知用户网页程序收集和处理其个人信息所可能带来的风险.

-
控制: 为用户提供合理的, 控制程序对其个人信息收集的方式, 将选择权交给用户决定, 是否提供信息, 以及如果要提供的话, 他们愿意提供多少/哪些信息.

-
强制执行: 确保正确的, 处理用户信息的原则和流程被强制执行, 从管理层到开发者, 公司上下都需要具备对用户信息的保护意识.

-
展示: 向外界展示处理用户信息的方式, 将对用户信息的收集和处理透明化, 公开化.

Week5: 实例化需求
实例化需求 (Specification By Example, SBE) 就是从使用场景出发, 以用户的操作实例来说明和解释需求. 和常规的规格说明相比, “实例” 更加场景化, 其典型的形式是: “在什么情况下, 执行什么操作, 所期望得到的结果是什么”.
因此, 使用实例化需求的方法解释产品需求时, 一般需要经历三个步骤:
- 用具体的例子 分析和说明 需求.
- 将第一步中涉及的例子 转化为具体实现的测试用例.
- 使用第二步中构建的测试用例验证产品实现, 检测产品是否满足了需求.
Spring 允许我们通过 对实体进行检测 和 对 Controller 检测 来判断需求是否得到了满足. 如:
在对实体进行检测时, 可通过下列的标记检测实体的期望属性:

同时也可以通过检测 Controller 来判断:

Week6: 隔离化功能测试
本节讨论如何将程序的不同功能与其他功能模块 隔离, 从而确保它可以被 完全独立 地测试. 下面以 Spring 应用程序中的控制器举例说明, 如何通过构造单元测试样例实现这一点.
1. 软件测试的基本概念
我们首先回顾软件测试的基本概念:
软件测试就是一种检验程序功能或性能是否达到要求的手段和方法, 有助于开发团队在同一个程序库中协同工作, 并确认彼此的工作进度. 其基本途径是 确认 (Validation) 和 验证 (Verification).
基本上, 确认 这一步需要我们明确, 我们是否构建了正确的软件, 以使其符合客户的需求. 而 验证 这一步需要做的事是, 确认我们是否以正确的方式将其构建, 以及它是否不受各种 缺陷 (Defect) 和 故障 (Failure) 的影响.
故障 的发生往往意味着软件中存在亟需修正的缺陷, 但反过来即使软件在运行中并未发现故障也不能确定它就没有缺陷, 这可能只是因为恰好包含缺陷的代码段没有被执行, 或出于纯粹的运气在此次执行中没有触发故障.
广义上, 软件未能达成客户需求, 软件的非功能性特性, 如可扩展性, 易用性和性能不足, 也算作软件缺陷.
我们可以通过设计模拟多种情境, 注入多种不同数据的测试样例来减小 “因为运气原因未能发现软件中潜藏的缺陷” 的概率.
虽然完整地测试所有对象, 考虑所有情境实际上是不可能的, 但我们可以通过将不同级别的测试组合起来, 最大化我们的测试范围, 并排除因为运气而无法发现缺陷的情况.
下面讨论测试的两种类型: 静态测试 (Static) 和 动态分析测试 (Dynamic Analysis).
在静态测试中, 我们实际上并不会运行程序. 静态测试的例子包括 代码审查 (Code Review), 对代码段逻辑和语法的自行检查 (Inspection) 等.
而在动态测试中, 我们一般使用 测试套件 (Test Suite) 在给定数据的情况下运行程序并检查对应的运行结果. 和静态测试一样, 这一过程既可以是手动的, 也可以是基于测试框架自动执行的.
测试基于 测试者能否看到他们所测试对象的内部结构 而又被分为 黑盒测试 与 白盒测试.
在白盒测试中, 我们可以对被测对象的内部方法和结构进行测试, 这一类型的测试适用于我们需要检查被测对象结构的情形.
而在黑盒测试中, 我们对其内部结构一无所知, 因而只能检查 “黑盒吐出的结果”, 由此这一类型的测试适用于我们需要从方法使用者的角度检查被测对象的情形.
通过将静态测试和动态分析测试相结合, 编写黑盒测试与白盒测试, 我们可以最大程度地确保被测对象不包含明显的程序错误, 缺陷和故障.
下面讨论如何基于不同的 层级 对软件进行测试.
基于不同的层级, 测试可被分为:
- 单元测试 (
Unit Test): 针对每个独立的代码块进行测试. - 集成测试 (
Integration Test): 将多个模块组合起来进行测试, 确保多个组件可以正确交互. - 系统测试 (
System Test): 进一步将所有的模块整合为一个系统, 确保作为整体时软件可以正常工作. - 验收测试 (
Acceptance Test): 检查软件是否满足了用户的需求. - 回归测试 (
Regression Test): 在经过整合后重新执行单元测试, 确保对模块的整合与修复不会影响之前已经通过检测的任何单元.
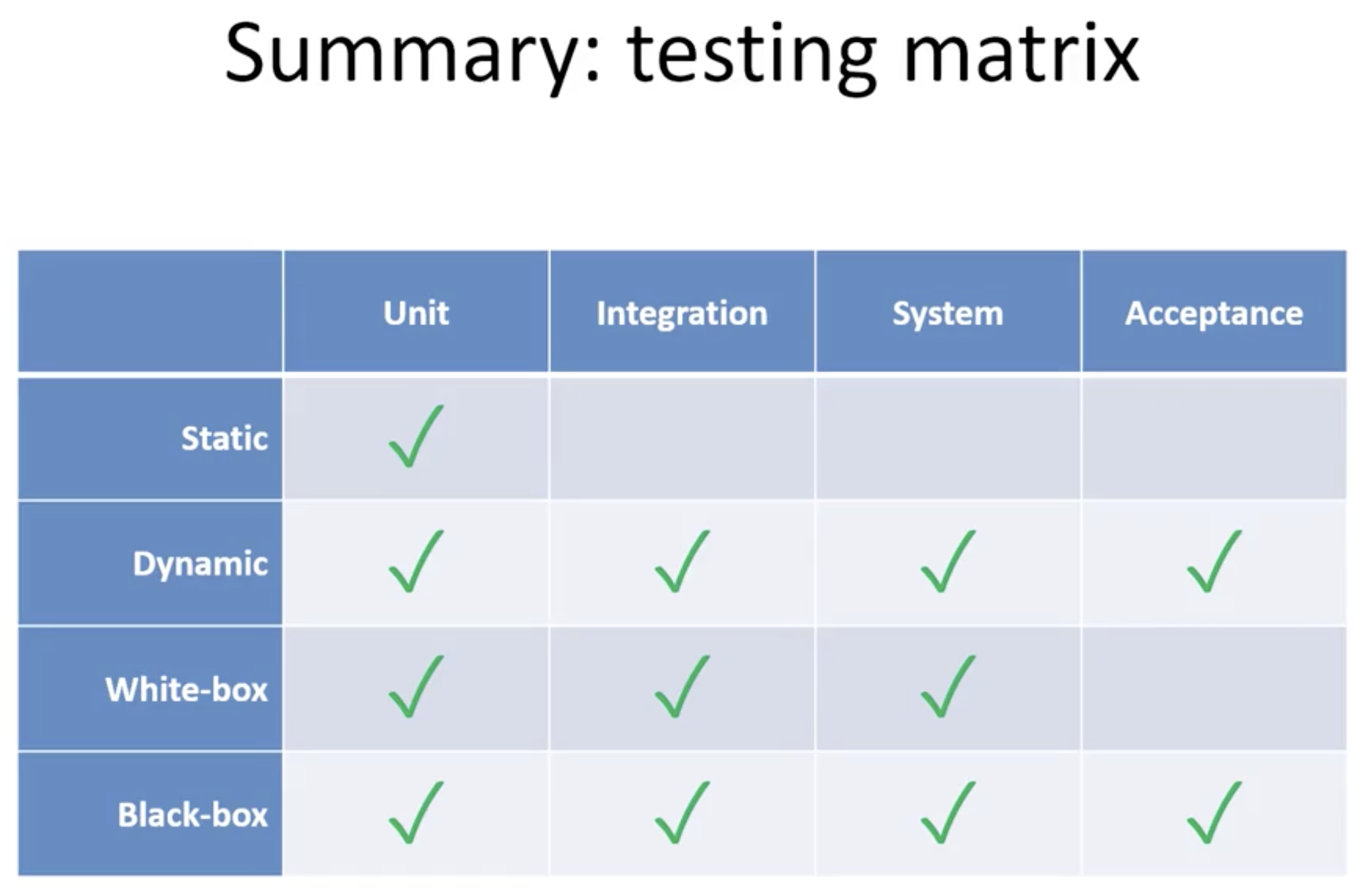
2. 基于隔离原则的功能测试
下面我们介绍如何设计测试使它能够 完全独立地 对所需项目进行测试的方法和技术, 我们将通过以 Spring 网络程序的 Controller 为例展示如何隔离针对它的单元测试.
将隔离作为功能测试的原则的原因是: 对于单元测试 (Unit Test) 而言, 一个合格的单元测试不应当基于其他任何测试之上, 而应当在 只测试某一个特定项目 的同时 位于由测试任务划定的类, 进程或网络范围内.
考虑下列的例子:
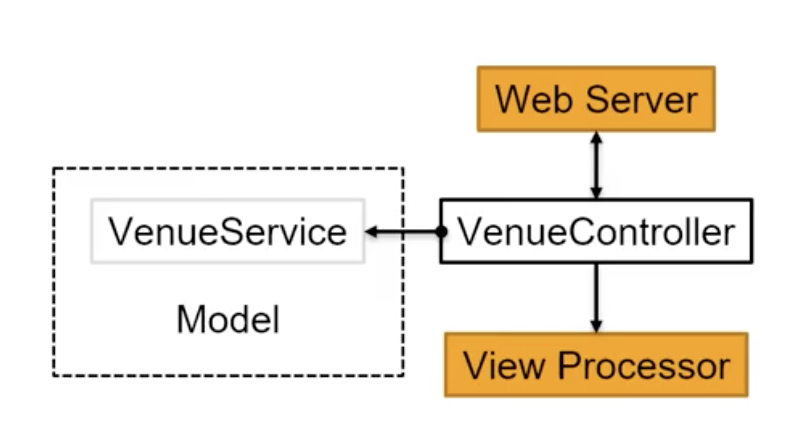
在上述的 MVC 架构中, 如果要对 VenueController 进行单元测试, 在不进行隔离的情况下就会不可避免执行对 Web Server, VenueService 和 View Processor 的调用, 破坏了单元性. 为了将程序模块和外界的其他作为依赖的模块或数据在测试时隔离开, 我们可以使用 Test Double 将它们模拟出来.
Test Double 依据复杂性被分为四种类型:
-
Dummy: 不参与待测方法/类的任何数据或逻辑操作, 只是起到占位符的作用, 往往在构造类, 实例化对象或调用方法时作为不会被实际使用的参数传入. -
Fake: 一般指代 (在测试环境下能够满足调用需求, 但复杂度和安全性等重要性质被弱化或忽略, 因此不适用于实际生产环境中的) 数据, 数据库或方法, 如 “不安全地在内存中存储数据库的数据库管理系统”.
-
Stub: 一般用于提供预设且无法更改变化的数据, 如某个被设计为永远返回 $0$ 的, 回传温度传感器读数的方法. -
Mock:Mock是具有逻辑的Stub, 它能依据预设的逻辑依次或在不同的状态下向被测方法/类/对象提供不同的数据.
下面介绍 Stub 的例子:

可见在上图的例子中方法 readTemperature() 就被设计为一个 Stub, 为了满足测试的需求, 它的返回值永远为 $0$.
下面介绍 Mock 的使用:

我们使用 Mock 来构造具有逻辑的 method stubs, 注意此处在 mocking Java 对象时, 所使用的注记为 @Mock, 而 mocking service layers 时则需使用 @MockBean. 通过这种方法我们即可用被模拟出来的 mock 替代和被测类/对象/方法相关联的其他类/方法/对象或所需要的数据, 进而实现被测者和外界环境的完全隔离.
默认状态下对 mock 的 service layers 的各种方法进行调用时, 回传值均为 null, 如: 尝试调用 eventService.findAll() 就永远会得到 null. 要让特定的服务层方法或类方法以指定的方式返回特定的值, 就需要人为定义它们的返回逻辑.
首先我们可以自定义 在何种情况下返回什么数据, 如:

注意对 event.getName() 返回值的定义: 上图例子中的定义实际上定义的是该方法被先后调用两次时所需返回的不同结果, 第一次抛出异常, 而第二次返回 “Hello”.
同时还可以对调用某些方法时所执行的行为进行检测(verification). 检测发生在对应方法调用之后, 验证该方法是否执行了我们所希望执行的行为.

最后引入一个实际的例子:

首先, 要对该需求进行测试, 我们需要实例化 venue 和 venueService. 上图中的测试分为四个部分:
-
对
venue的性质进行建模: 使用stub定义所模拟的venue中不含任何event. -
对
venueService的性质进行建模: 调用venueService.findOne(1L)时所回传的恰为在第一步中所定义的venue. -
执行删除方法, 尝试删除所建模的
venue. -
对删除方法进行行为检测: 若程序满足需求, 由于建模的
venue中不含任何event, 因此它 可以被删除. 因此行为检测这一步中, 需要检测在第三步中的删除方法执行成功后该venue是否真的被删除.
Week7: 集成外部 API
本周以 在 Eventlite 中引入 Mapbox API 为例, 介绍如何在 Spring 网络程序中引入, 集成和调用外部 API.
在 MVC 架构的网络应用程序中引入第三方 API 的主要原因是我们可以复用现成的问题解决方案, 从而节约开发时间和程序复杂度. 第三方 API 引入的主要问题是: 寻找到满足需求的合适 API, 以及将它集成进应用程序的过程, 其中以第一点最为重要.

在选择 API 时, 除了需要考虑上图中涉及的代码/开发参考指南质量, 功能性, 社区支持度等维度外, 更要结合自己的需求而定. 如:

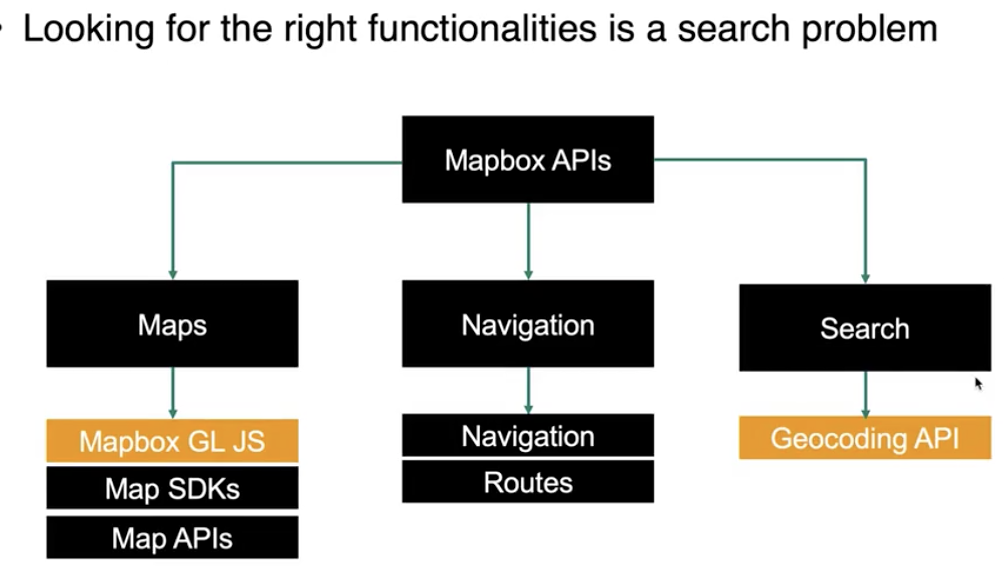
根据我们的实际需求, 就可以确定我们需要集成 Mapbox GL JS 和 Geocoding API. 不难得出, 我们可以使用下图所示的方式集成它们:
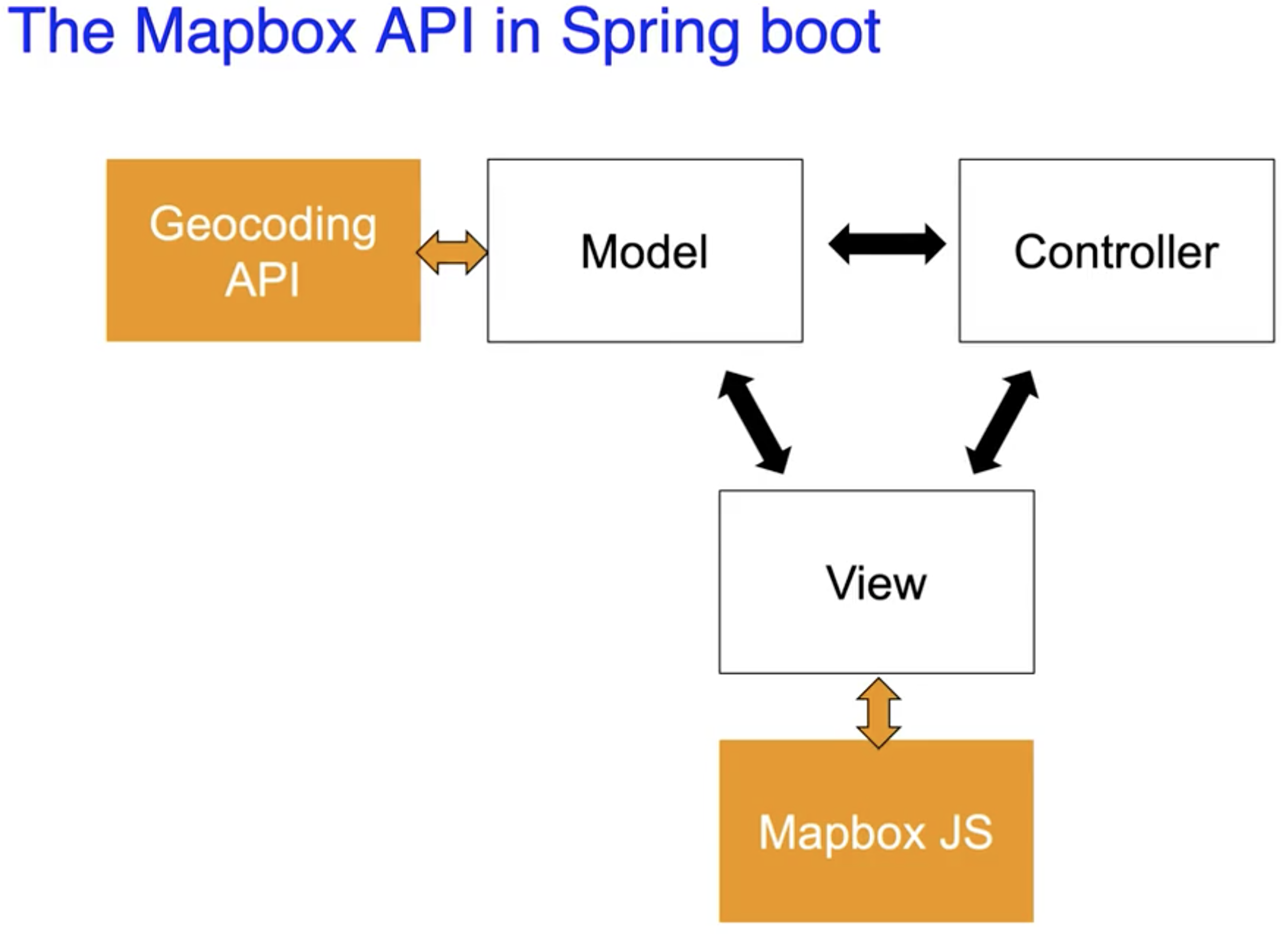
在结合外部 API 时, 我们可以基于现成的使用例以借鉴的方式将 API 集成入我们的程序中:

这里注意 GeoCoding 的定义: 将真实地址 编码.


Week8: 集成外部服务
本周我们以 将 Twitter 使用 Twitter4J Library 集成入 Eventlite 为例介绍如何将外部服务集成入 Spring 网页应用程序中.
和集成外部 API 相同, 我们首先需要基于需求决定集成什么样的外部服务.


(注意概念: SaaS: Software as a Service, API + resources+Interface.)
“Software as a service (or SaaS) is a way of delivering applications over the Internet—as a service. Instead of installing and maintaining software, you simply access it via the Internet, freeing yourself from complex software and hardware management.
Essentially, SaaS is a subset of cloud computing.”
其次我们同样需要结合 开发者社群活跃程度, 功能是否全面, 开发文档是否完备 等因素综合考量选择合适的外部服务.

在选择了合适的外部 API 后, 我们就需要根据希望实现的功能确定它在我们当前的 Web APP 的 MVC 架构中的位置. 显然, 由于在此处我们希望在界面中的不同位置展示推特信息流或发送推特, 就需要由 控制器 从 Model 中使用对应的 API 基于 API Key 从外部服务取出数据, 然后传递给 View; 而同时从 View 传来的请求也需要被反过来传递进 Controller 处理. 因此, 相关的 API 需要集成在 Controller 中.
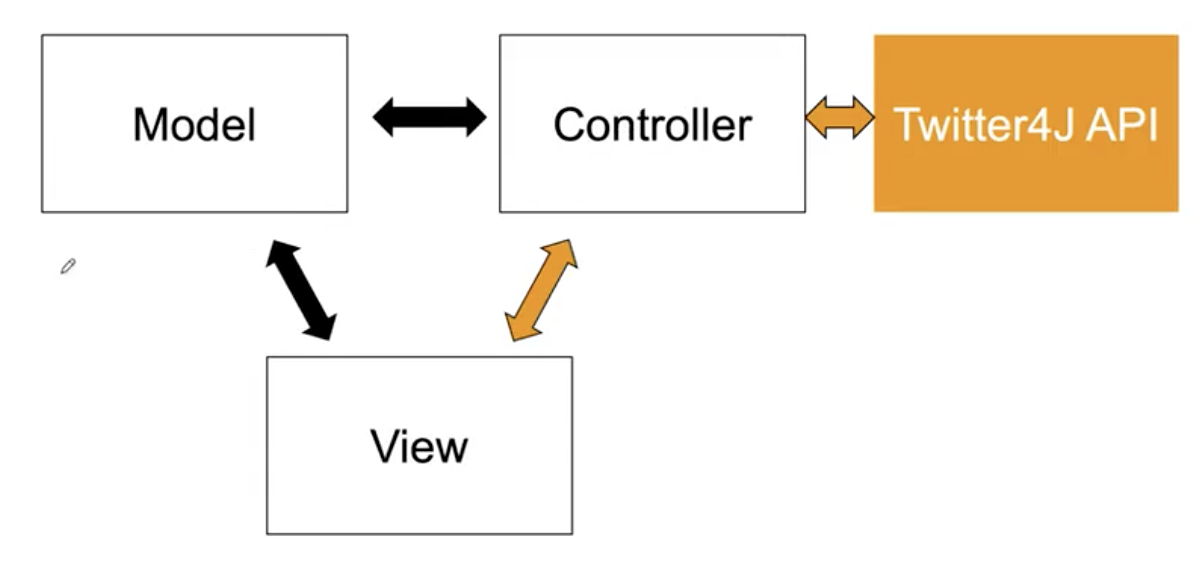

最后以本周 Lab 需求收尾. 需要注意: 使用外部服务的过程实际上是 外部服务提供商, 外部服务应用开发者 和 最终用户 之间的三方交互过程, 从 Web App 开发者的角度看我们属于 外部服务应用开发者.
对外部服务的集成往往不止需要我们在自己的 Web APP 中进行相关的 API 嵌入, 我们往往还需要从对应的外部服务处得到对 API 的访问权限.

Week9: 提供 REST API
REST (REpresentational State Transfer, 表达性状态转移), 是一种 抽象的软件架构风格 和 针对网络应用的设计开发模式, 可显著降低系统开发的复杂性和系统的可扩展性.
REST 由一系列 架构约束条件 和 原则 组成, 我们称 任何满足这些约束条件和规则的应用程序或协议设计 都是 RESTful 的.

REST 架构的核心元素和基本假设是:
-
资源:
资源 是
REST架构的核心元素. 基于URI规范, 定义资源是 任何有被引用的必要 的东西, 它可以是一个具体的事物, 也可以是抽象的概念; 或者将资源理解为任何 可以被操作(获取, 更新, 删除, 提交) 的数据, 资源的集合同样是资源.在
Web中可以认为, 资源是URI(Unique Resource Identifier) 所标示的东西. 我们使用URI指定被操作的资源, 若一个URI不仅能标示这个资源, 还能 定位 它, 则称这个URI也为URL(Unique Resource Link). 需要注意, 每个资源对应的URI是 独立且唯一 的. -
资源表示:
资源是抽象的概念, 无法被直接传输, 而只能 用不同的方式 (如
JSON,XML,HTML…) 传输 资源的表示 (Representation), 具体选择什么样的传输方式取决于服务器的供给能力和客户端的实际需求, 而且传输的表示 不一定就是服务器存储资源时所使用的表示, 如服务器以压缩方式存储资源, 在传输时将其解压并转换为JSON后传输.由此我们也可知道, 对给定的资源可以有 多种不同的表示.
-
状态转换:
在
Client-Server服务模式下, 客户端负责维护全部的应用状态 并且负责确保 客户端向服务端发送的请求 包含服务端用来理解该请求所需要的 全部信息, 同时服务端 不负责维护应用的状态, “浏览器作为服务端需要负责记录用户在当前网页上的前进和后退状态” 就是一个这样的例子.


REST 架构的基本原则:
-
统一接口:
使用通用的协议对资源进行获取和进一步地操作, 如使用
HTTP Method对资源进行CRUD; 对资源进行统一命名, 定义统一的链接格式和数据格式. -
客户端和服务端 彼此独立:
客户端与服务端互相隔离, 互不影响, 彼此通过调用
API进行交互.对客户端而言, 只需通过
API从服务端获取对应资源即可, 接触不到也不关心服务器端资源供给的具体实现.对服务端而言, 只需提供一致的
API接口即可, 内部实现可以自由决定, 接触不到也不关心客户端对API的使用方式.也就是 “前后端分离”.
-
无状态性:
各个服务之间的
API调用应该是 无状态 的: 服务端 不负责保持API调用的状态, 不储存任何历史记录和任何关于客户端的信息, 用户的状态信息在 客户端 进行存储和维护. -
可缓存性:
REST规定, 对于可缓存的资源需要明确标注 它是可被缓存的. - 系统架构分层
- 按需编码

(HATEOAS: Hypermedia As The Engine Of Application State.)
“HATEOAS is a constraint on REST that says that a client of a REST application need only know a single fixed URL to access it.”
“Any and all resources should be discoverable dynamically from that URL through hyperlinks included in the representations of returned resources.”
“REST is the set of constraints. RESTful refers to an API adhering to those constraints.”
“A REST API are stateless because, rather than relying on the server remembering previous requests, REST applications require each request to contain all of the information necessary for the server to understand it.”
“Storing session state on the server violates the REST architecture’s stateless requirement.”
“The vast majority of RESTful systems are implemented over HTTP - the Hypertext Transfer Protocol - and almost certainly none of us will have used any that aren’t over HTTP.
REST is not limited to HTTP, it’s just the most commonly used transport at the moment.”

相关习题解析
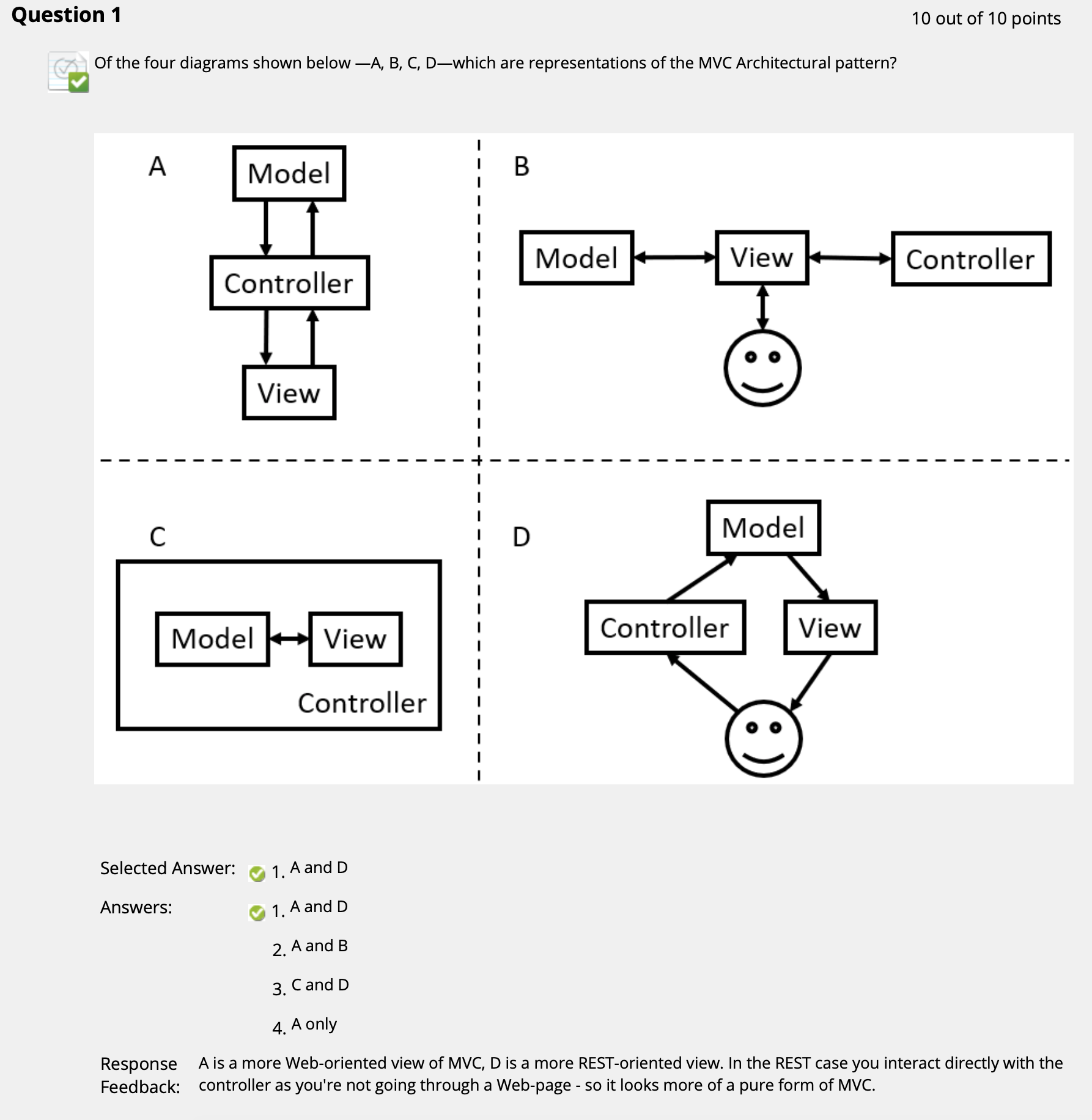
($\uparrow$ 明确 MVC 的基本定义, 可知显然 B (Controller 对 Model 施加影响) 和 C (Controller 与 Model, View 之间并非包含关系) 错误. 此处同时注意 D 的表述更接近 REST-Oriented.)
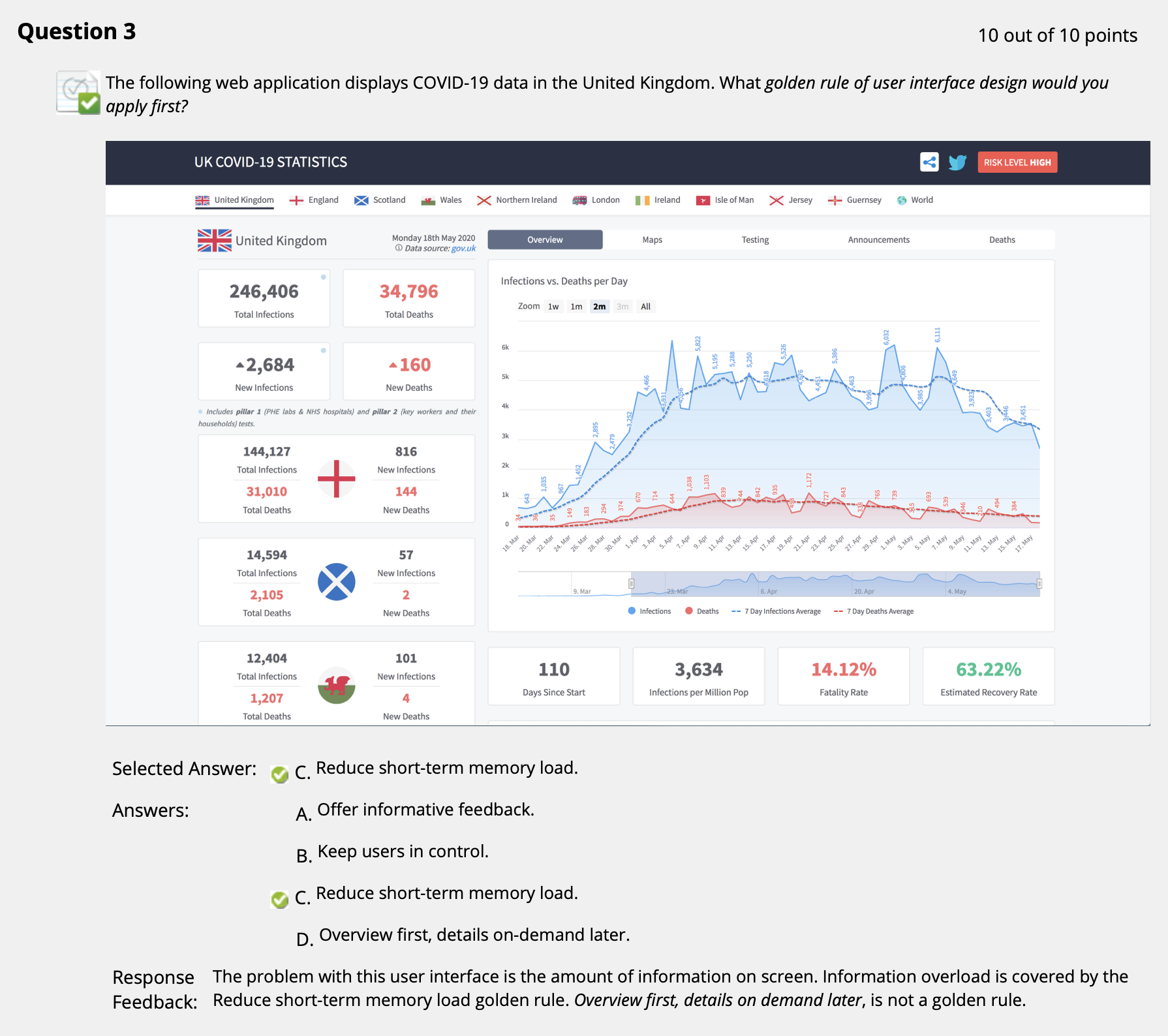
($\uparrow$ 此处需要注意的是应当对八条黄金界面设计原则非常熟悉. 不仅需要熟知哪些属于设计原则, 还需分辨出那些 “表述相近但并不是” 的规则, 比如图中的 D 选项.)

($\uparrow$ 看不清, 不好用, 所以需要改进界面让人能看清, 变得更好用一点)
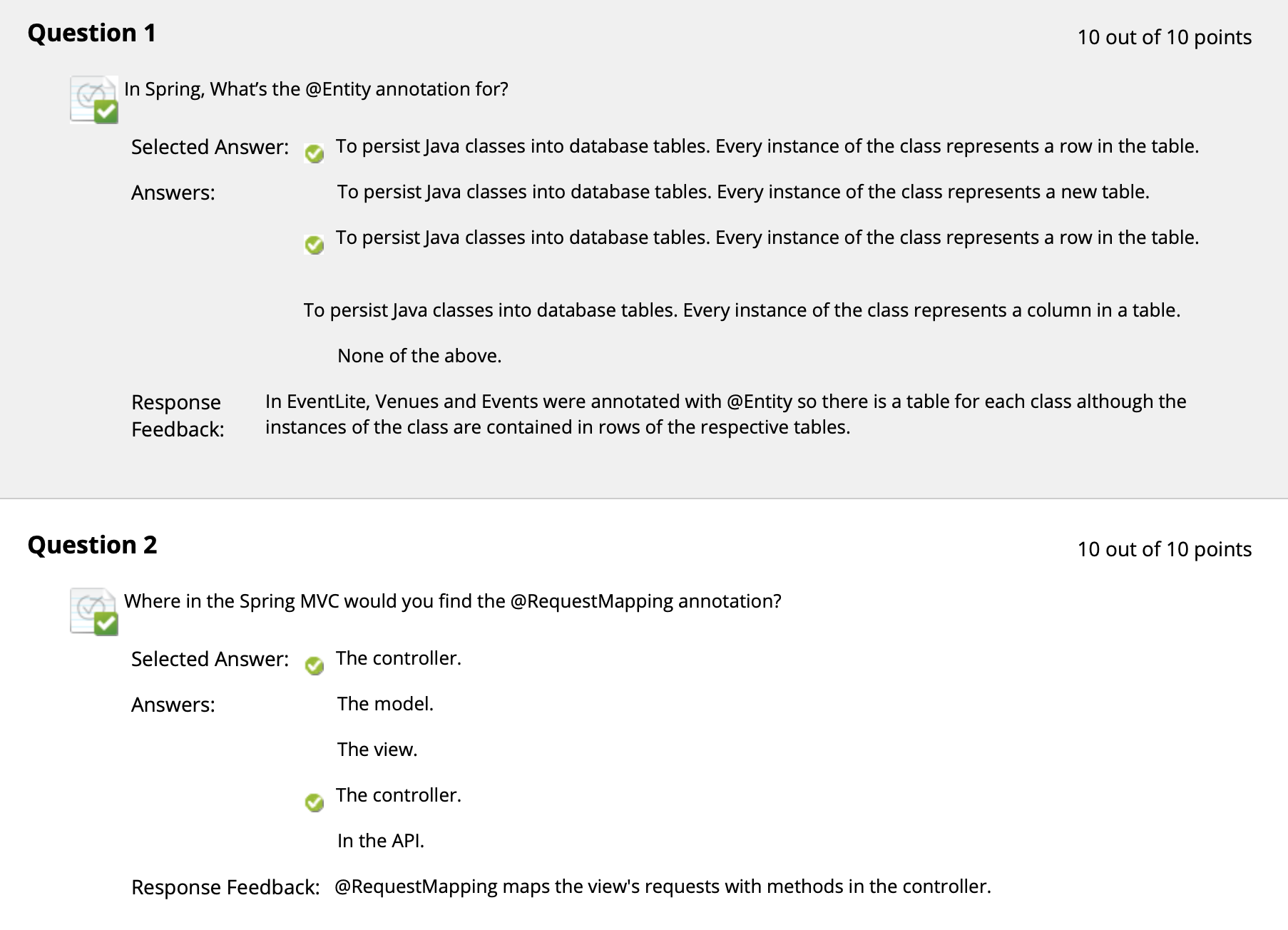
($\uparrow$ 务必熟悉 Spring Boot 常见的 Annotations 的作用和位置!)


($\uparrow$ 结合 Examinable Readings 中的安全设计原则蓝书理解.)

($\uparrow$ 回顾课上所说内容, 结合常识逻辑即可得出正确答案.)

($\uparrow$ 务必熟悉各种测试类型和隔离测试中涉及的全部概念)

($\uparrow$ 注意识别选项中 “可疑的, 过于绝对的” 表述)

($\uparrow$ 如果写错了必然没听课. 真正的考试中也可能出现和 RESTful 其他定义相关的题, 务必确保理解 REST 的基本约束和定义.)