
COMP23111 REVISION Ch4
4. 其他数据库
我们将在本章中对本课程涉及的其他三种非关系数据库进行介绍. 这种介绍基于功利性质, 主要信息来源为部分 Slides 内容 + Lab 内容, 并且逻辑结构可能极其混乱.
4.1 非关系类型数据库: Couchbase
Couchbase 是一种主要用于数据存储和缓存的, 分布式 非关系型 (NOSQL) 数据库.
Couchbase 使用 JSON 存储数据, 因其作为一种通用的数据传输格式具备高度的灵活性 (Flexibility)且具备良好的性能.
Couchbase 的查询语言为 完整融合了 SQL 和 JSON 的, **兼容 SQL92 标准的 N1QL, 它 **使用 JSON 存储数据, 而使用 SQL 语法执行查询.
Couchbase 同时支持两种满足 ACID 性质的数据库事务: N1QL 和 Key-Val, 其中 N1QL 型数据库事务和 SQL 中的数据库事务极其相似:

Couchbase 可用于构建 数据库, 搜索引擎, 键值对存储 和 缓存.
4.2.1 Couchbase 中的键值对存储
Couchbase 同样支持数据库分划 (Database Sharding). 其基本架构被称为 Master/Master 或 Masterless, 细节为:
Couchbase将最高数据库分划片数限制为 $1024$.- 在数据被存入数据库中时,
Couchbase使用CRC32算法对数据进行哈希, 并基于计算的哈希值自动将数据分配到某个存储在某个节点 (Node) 的分划中 (这样的分划被称为vBucket), 从而确保数据基本均衡地被分划, 结构自然地被优化, 从而确保无需再人为地对数据库进行重分划. - 在连接节点集群 (
Cluster) 查询数据时, 客户端会 预先下载完整的节点表, 从而在查询数据时可以快速地确定 某个vBucket被存储在集群中的哪个节点 (Node, 物理机) 上.
因此, Couchbase 中的信息检索流程类似于:
- 给定信息, 计算出其
CRC32哈希值. - 基于计算的哈希值确定该信息 (如果确实存在数据库中的话) 位于哪个虚拟分划 (
vBucket) 中. - 基于预先下载和维护的节点表确定这个虚拟分划被集群 (
Cluster) 中的哪个节点 (Node) 所存储. - 直接向对应的节点发送数据查询请求.
和常规的 Master/Slave 架构不同, 由于不存在中心节点, 因此在 Couchbase 中不存在某个特定节点下线后导致 “牵一发而动全身” 的情况, 意味着它具有更好的健壮性 (Robustness).
Couchbase 将以文档 (Document) 为形式存储的数据置于 存储桶 (Bucket) 中对它们进行分类和管理. 任何一个 Bucket 都承载多个 名为作用域 (Scope) 的容器 (Container), 而 作用域同时承载名为集合 (Collection) 的容器, 集合中 存储 JSON 文档.
集合 (Collection) 是在存储桶 (Bucket) 中的 Couchbase 服务器上定义的数据容器. 每个集群 (Cluster) 最多可以创建 $1000$ 个集合. 而所存储的项目名称在其所属的集合中必须是唯一的.
作用域 (Scope)是用于对多个集合进行分组的机制. 每个集群最多可以创建 $1000$ 个作用域. 集合名称在其作用域内必须是唯一的.
文档 (Document) 是存储在 Couchbase 中的数据点 (Datapoints). 它们由用来引用数据项的键和与键关联的数据值组成: 该值必须是二进制或 JSON 文档.
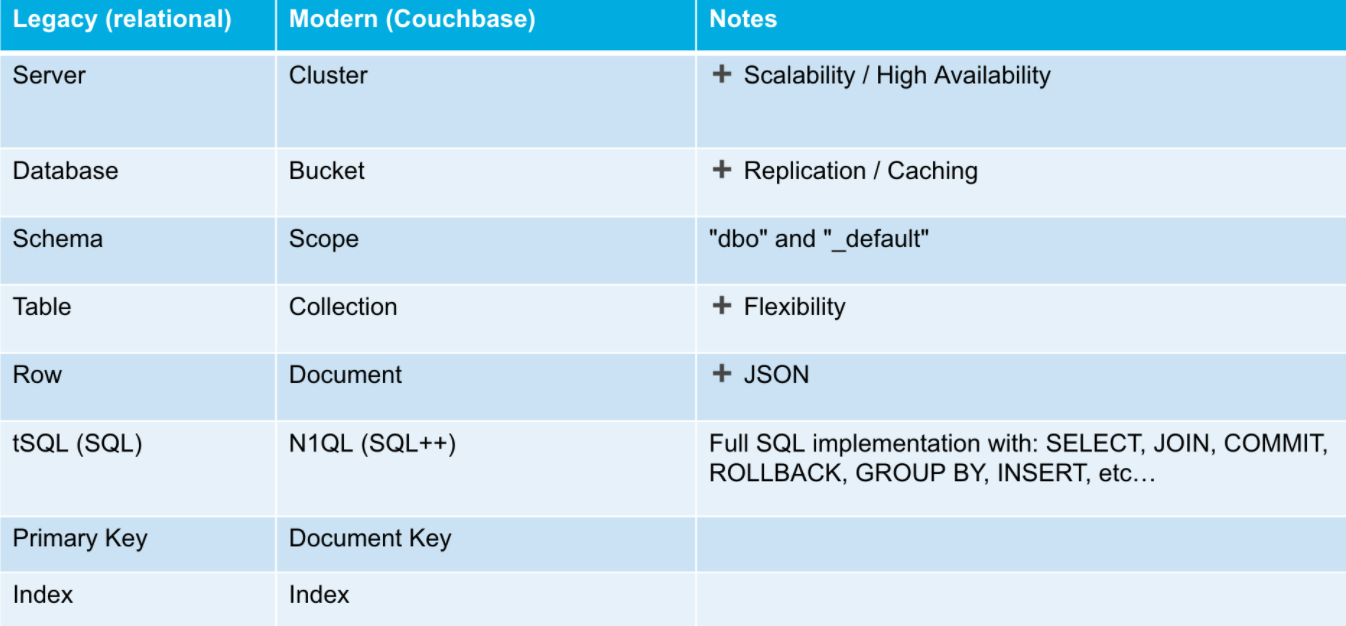
Couchbase 的文档存储结构与关系型数据库之间的类比如下:
4.2.2 Couchbase 中的数据建模
相比关系数据库模式, 由于 Couchbase 使用 JSON 作为存储方式且不对实体间复杂的关系建模, 因此对表结构的修改可以视为对新数据 JSON 结构的修改, 同时:
- 只要表结构修改方式得当, 两种结构不完全相同的数据在库中可以共存.
- 此外, 我们也可以选择将库中现存的旧格式数据全部转换为新格式.
4.3 Couchbase 的 一些潜在考点
-
durability + cas:
类似于checksum, 或 “版本号”, 在对象被修改时同步改变, 反映该对象 (document) 的当前状态, 相当于metadata. cas: “COMPARE AND SWAP”. 在执行mutation时couchbase会检索app提供的文件的cas和服务器端的cas是否相同, 若相同才能允许mutation操作顺利执行.
-
upsert:
used if want to overwrite a document with the same key in case it already exists.
if it doesn’t exist, a new doc will be created with the specified key.
-
Document Expiration:
在couchbase中可设定文件在一定时间后过期 (expire), 这个时限可在创建文件时被指定.一旦在数据库的定期cleanup process执行时或查询时发现任何文件过期了, 该文件就会被删除, couchbase server会maintain一个墓碑 (tombstone) 作为记录. 墓碑就是对任何已被删除的item的记录, 维护墓碑的作用是确保节点之间和集群之间的eventual consistency.
-
index (索引)
是在couchbase中执行搜索操作所必须的. 正确创建文件的索引有助于提升数据库的性能.
index的类型: 主要看covering index: covering index是一种包含该索引所指向域中数据值的索引, 由此无需通过索引再去取值, 而是将索引中包含的数据直接使用, 有助于减少查询语句的消耗时间, 提升数据库性能. indexing是异步的.
-
sub-document operations
sub-document operations 可用于高效访问和修改数据的一部分: 只从数据库中提取出所需要被检索和改动的部分文件而非直接获取所有文件, 降低带宽要求减少性能浪费. sub-document operation是原子化的, 若一个sub-document mutation失败, 所有的都会失败.
-
N1QL的惰性原则 (Queries are executed lazily):
只在查询结果被处理的时候执行查询.
-
Place Holder:
占位符用来在查询 (query) 中指代那些我们希望被用变量代替的常量的位置.占位符有两种:
- Positional Placeholder: use an ordinal placeholder for substitution
- Named Parameter: use variables
named parameter是用来代替 WHERE, LIMIT, OFFSET 的占位符.
注: 二者的调用方式也有所不同:
Named parameters refer to the variables specified in the query while the positional parameters are always referred to by the order in which they are specified.
-
Scan Consistency:
QueryScanConsistency.REQUEST_PLUS被选择时查询解释器会花更多的时间进行查询, 但会返回确定是最新的结果. -
OFFSET/LIMIT使用 OFFSET/LIMIT 过滤返回的查询结果:
- LIMIT ==> 前 n个
- OFFSET ==> 跳过前n个
如果二者同时出现, 效果是LIMIT先于OFFSET
-
Aggregate Function:
Aggregate Function: 聚合函数. 只能在 SELECT, LETTING, HAVING, ORDER BY 语句里用上.
4.2 图数据库: Neo4j
和 Couchbase 不同, Neo4j 名为 “非关系数据库”, 其核心却在于使用 图 (网络) 将数据间的关系抽象化表示, 且数据建模以数据间的关系网络为主:
Neo4j是 开源 的, 图数据库.Neo4j是基于JVM的 非关系数据库.Neo4j是具有管理多个数据库能力的数据库管理系统 (DBMS).
4.2.1 图数据库表示基础
在图数据库中, 数据被表示为存储在图 (Graph)中的 节点 (Node, Vertices) , 边 (Vertices) (一般表示关系) 和 属性.
其中, 节点 (Nodes) 一般 作为实体的抽象, 因而 节点可以具有属性.
边 连接两个节点, 一般作为 关系的抽象, 需要注意 边也可以具备属性. 但是, 任何边都 具备且仅具备一种关系属性 (Relationship Type).
举例而言: 考虑 关系类型 ACTED_IN, 则在下图中有如下结论:
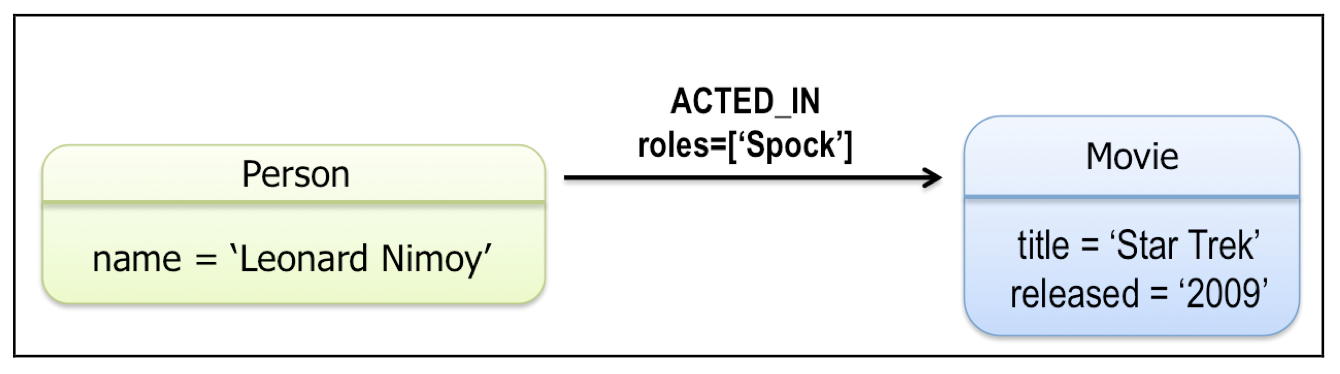
- 节点 “Person” 具备属性 “name”, 值为 “Leonard Nimoy”, 该节点为 源节点.
- 节点 “Movie” 具备属性 “title” 和 ”released“, 值分别为 “Star Trek” 和 “2009”, 该节点为 目标节点.
- “Leonard Nimoy” 节点具有一个 传出关系 (
Outgoing Relationship). - “Star Trek 节点具有一个 传入关系 (
Incoming Relationship).
显然, 在某个图中遍历的行为可以被视作 沿着各种各样的关系遍历节点的行为.
在上面的例子中, 显然我们可以从 “Leonard Nimoy” 节点开始, 沿着关系 ACTED_IN 遍历到目标节点上, 该遍历结果是标记为 “Star Trek” 的节点, 而返回值为一个长为 $1$ 的路径.
长为 $0$ 的路径显然是最短路径, 它表示在该路径中只包含一个节点, 并且不包含任何关系.
一般地, 节点名 首字母大写, 关系类型名 全部大写, 而属性名 全部小写.
4.2.2 图数据库查询语言 Cypher
Neo4j 的查询语言是 Cypher, 它基于 模式 (Patterns). 下面介绍它的基本语法:
-
节点表示
Cypher使用一对括号表示一个节点. 一般括号内需要含有节点名. -
关系表示
Cypher使用一对间隔线--表示 无向关系. 有向关系表示为<--或-->, 关系的属性用一对中括号包裹, 属性需位于两个间隔线之间, 如:-[...]->. -
节点创建
CREATE (newnode) RETURN newnode -
关系创建
CREATE (a)-[r:NEWRELATIONSHIP]->(b) RETURN a, b, r -
数据删除
可以使用
MATCH语句删除数据:MATCH (n) DETACH DELETE n -
创建/更新数据
可以使用
MERGE语句创建或更新数据:MATCH (a), (b) MERGE (a)-[r:RELATIONSHIP_TYPE]->(b) SET r.property = ['value'] RETURN a,r,b -
条件匹配
可以使用
MATCH语句基于 复杂条件语句 搜索匹配:1
MATCH (n) WHERE some-criteria-goes-here RETURN n
MATCH语句还可以在图中搜索满足给定模式的关系取得节点或节点的属性:1 2 3 4 5 6 7 8 9
# 基于模式匹配取得节点, 可以从两个方向搜索 # 方向: a --> b MATCH (a)-[r:RELATIONSHIP_TYPE]->(b) RETURN a,b # 方向: b --> a MATCH (b)-[r:RELATIONSHIP_TYPE]<-(a) RETURN a,b # 可以直接取回节点的属性值 MATCH (a)-[r:RELATIONSHIP_TYPE]->(b)<-[r:RELATIONSHIP_TYPE]-(c) RETURN c.property
也可以使用内建的最短路径算法
shortestPath()取得从给定节点之间的最短路径:1 2 3 4
# 调用内建算法 shortestPath() MATCH p=shortestPath((bacon:a)-[*]-(b)) RETURN p # 其中节点a被取别名 `bacon', `b' 为另一个目标节点, 返回的是 `a' 和 `b' 之间的最短路径
4.2.3 Slides部分内容摘抄




Centrality 中心度:
- Degree Centrality: “度中心”: 度最大的节点
- Closeness Centrality: 离得最近 (相隔边数最少) 的节点
- Betweenness Centrality
- Importance Centrality (Pagerank)
4.3 数据搜索和分析: Elasticsearch
-
query string query:You can use the query_string query to create a complex search that includes wildcard characters, searches across multiple fields, and more
-
term string query:You can use the term query to find documents based on a precise value such as a price, a product ID, or a username.
Avoid using the term query for text fields: use match query instead.
-
wildcard query:不能查日期, 只能查text, keyword, wildcard fild
-
语句改错: 无脑
-H 'Content-Type: application/json'
架构类比:

正确语法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 1. A correct curl command for creating a mapping for the index movie with the property year as date
# 注意 “-H 'Content-Type: application/json'” 非常重要!
curl -X PUT 'localhost:9200/movies' -H 'Content-Type: application/json' -d '{"mappings": {"properties" : {"year" : {"type": "date"}}}}'
# 2. check if the mapping for the index movies was created correctly
curl -XGET localhost:9200/movies/_mapping
# 3. import one document in the index movie
curl -X PUT 'localhost:9200/movies/_doc/109487?pretty' -H 'Content-Type: application/json' -d '{"genre" : ["IMAX","Sci-Fi"],"title" : "Interstellar","year" : 2014}'
# 4. How to import many documents in the index `movies':
# i. create a JSON file with correct context (make sure there's a new empty line at the end)
# ii. get the name and the location of that JSON file, for example "/home/csimage/m2.json"
# iii. execute the curl command:
curl -XPOST "localhost:9200/movies/_bulk?pretty&refresh" -H "Content-Type: application/x-ndjson" --data-binary "@/home/csimage/m2.json"
# 5. delete the document with identifier `58559'
# this time no "-H 'Content-Type: application/json'"
curl -XDELETE 'http://localhost:9200/movies/_doc/58559'


curl 常用语法 (http)
1、get请求
1
curl http://xxx.xxx.xxx.xxx:port/xxxxxxxx
2、post请求
1
curl -XPOST http://xxx.xxx.xxx.xxx:port/xxxxxxxx --data '{"xxxx" : "xxxx", "xxxx" : "xxxxx"}' -H "Content-Type: application/json"
1
2
3
4
5
-H表示自定义header (一般是: -H "Content-Type: application/json")
--data表示body
-X表示请求方式
3、put请求
1
curl -XPUT http://xxx.xxx.xxx.xxx:port/xxxxxxxx --data '{"xxxx" : "xxxx", "xxxx" : "xxxxx"}' -H "Content-Type: application/json"
4、delete请求
1
curl -XDELETE http://xxx.xxx.xxx.xxx:port/xxxxxxxx --data '{"xxxx" : "xxxx", "xxxx" : "xxxxx"}' -H "Content-Type: application/json"
REFERENCE: