
COMP23111 REVISION Ch3
3. 数据库实现
本节讨论 SQL 语句和部分高级功能, 并介绍 数据库事务 的概念和其处理方式.
3.1 SQL 基础
3.1.1 选择运算: SELECTION
SELECT 语句用于从一个关系中选出 满足选择条件 的元组的一个子集, 我们可以将其视为一个 过滤器. 如果将一个关系视为一张表, 则 SELECT 操作相当于从这张表中按照条件选出一些行, 而丢弃另外一些行.
1
SELECT column1, column2, ..., FROM table_name;
以及
1
SELECT * FROM table_name;
我们可使用 SELECT 语句查询一个或多个属性, 并且可在语句中对属性进行数值运算:
1
2
SELECT u_name, u_score, u_score+10, u_score-10, u_score*2, u_score/2
FROM T_USER;
此外, 可使用 SELECT-WHERE 执行 条件查询, 在 WHERE 子句中使用下列的运算符:
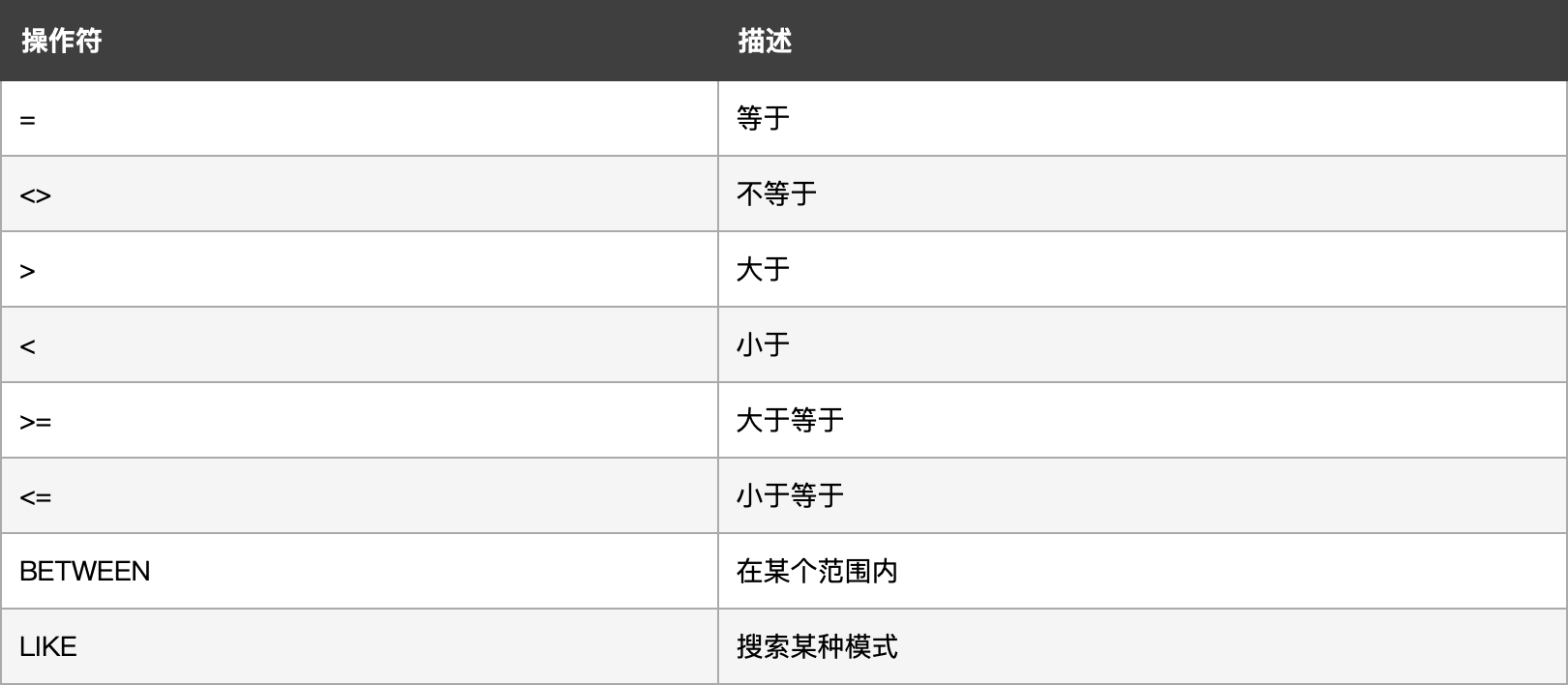
以及使用 与条件 (AND, BETWEEN) :
(查询 T_USER 表中成绩大于等于 $60$ 分且小于等于 $80$ 分的学生)
1
2
3
4
5
6
7
SELECT u_name, u_score
FROM T_USER
WHERE u_score >60 AND u_score <80;
SELECT u_name, u_score
FROM T_USER
WHERE u_score BETWEEN 60 AND 80;
使用 或条件 (OR, IN):
1
2
3
4
5
6
7
8
9
10
# 查询分数大于90分或者小于60分的记录 (用 OR)
SELECT u_name, u_score
FROM T_USER
WHERE u_score >90 OR u_score <60;
# 查询成绩为100, 98, 65的学生 (用 IN)
SELECT u_name, u_score
FROM T_USER
WHERE u_score IN (100,98,65);
使用 非条件 (!=, NOT):
1
2
3
4
5
6
7
8
9
10
# != 写法
SELECT *
FROM T_USER
WHERE u_name != `Axton Yao`;
# NOT 写法
SELECT *
FROM T_USER
WHERE u_name NOT LIKE `Ryan Xin`;
如果需要的话还可以为列名称和表名称指定别名:
1
SELECT `ID` AS `StudentID`, `Name` AS `StudentName` FROM `Students`;
在一些情况下, 我们可能希望从表中选取 不重复 的数据. 我们可以使用 DISTINCT 关键词:
1
SELECT DISTINCT Company FROM Orders;
3.1.2 投影运算: PROJECTION
和 SELECT 不同, 投影操作可以视为从表中 选出某些列 而 丢弃某些列.
我们可以使用 SELECT 语句从表中选出特定列作为表的 投影:
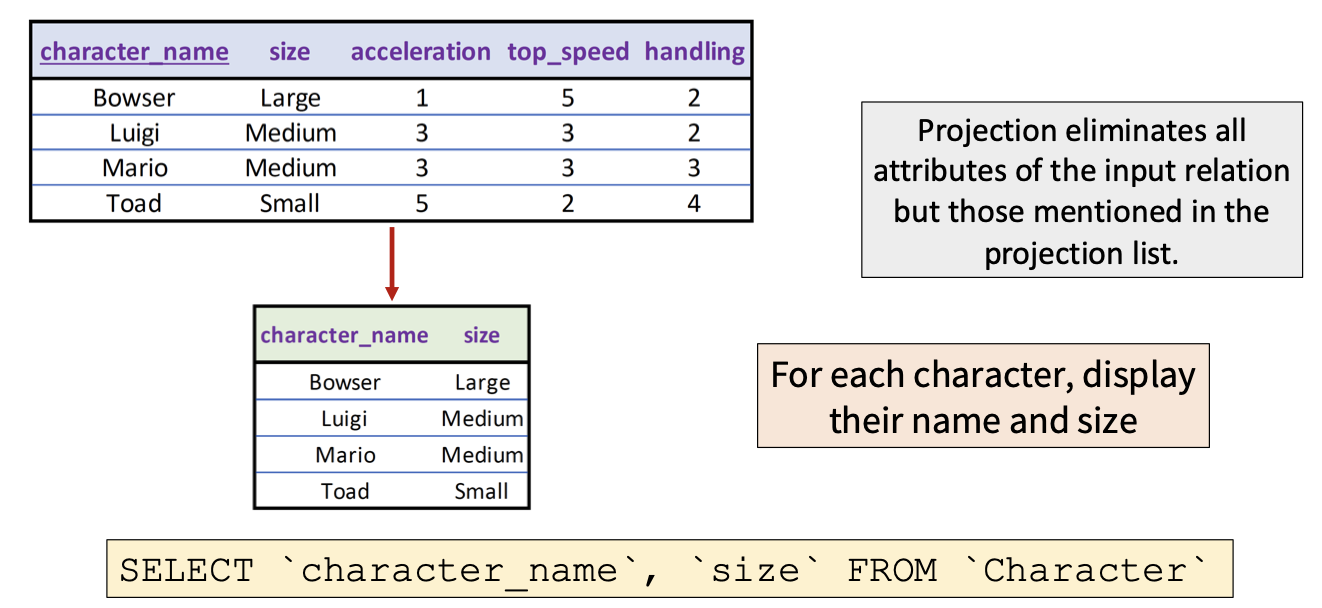
3.1.3 修改运算: ALTER/UPDATE
我们可以使用 ALTER 语句在 已有的表中 增/删表中属性, 修改属性的域, 修改属性名, 修改表名, 增/删主键:
- 在表中添加/删除列:
1 2 3 4 5 6 7
# 添加 ALTER TABLE table_name ADD column_name datatype; # 删除 ALTER TABLE table_name DROP COLUMN column_name;
- 修改属性域 (列的数据类型):
1 2
ALTER TABLE table_name ALTER COLUMN column_name datatype;
- 修改属性名 (列名):
1 2
ALTER TABLE table_name CHANGE COLUMN columm_name new_name
- 修改表名:
1 2
ALTER TABLE table_name RENAME TO new_name
- 增/删主键:
1 2 3 4 5 6 7
# 删主键 ALTER TABLE table_name DROP primary key # 增主键 ALTER TABLE table_name ADD CONSTRAINT pk_name PRIMARY KEY column_name
而 UPDATE 语句用于修改表中的数据:
1
UPDATE 表名称 SET 列名称=新值 WHERE 列名称=某值;
3.1.4 联合查询: UNION
我们可以使用 UNION 子句求两个不同表中两列的重复元素, UNION 的作用是将 两个 SELECT 语句的查询结果 作为一个 整体 展示出来.
使用 UNION 必须确保各个 SELECT 集合的结果的 列数必须相同, 且每个对应列的 数据类型必须相同, 但 列名可以不同.
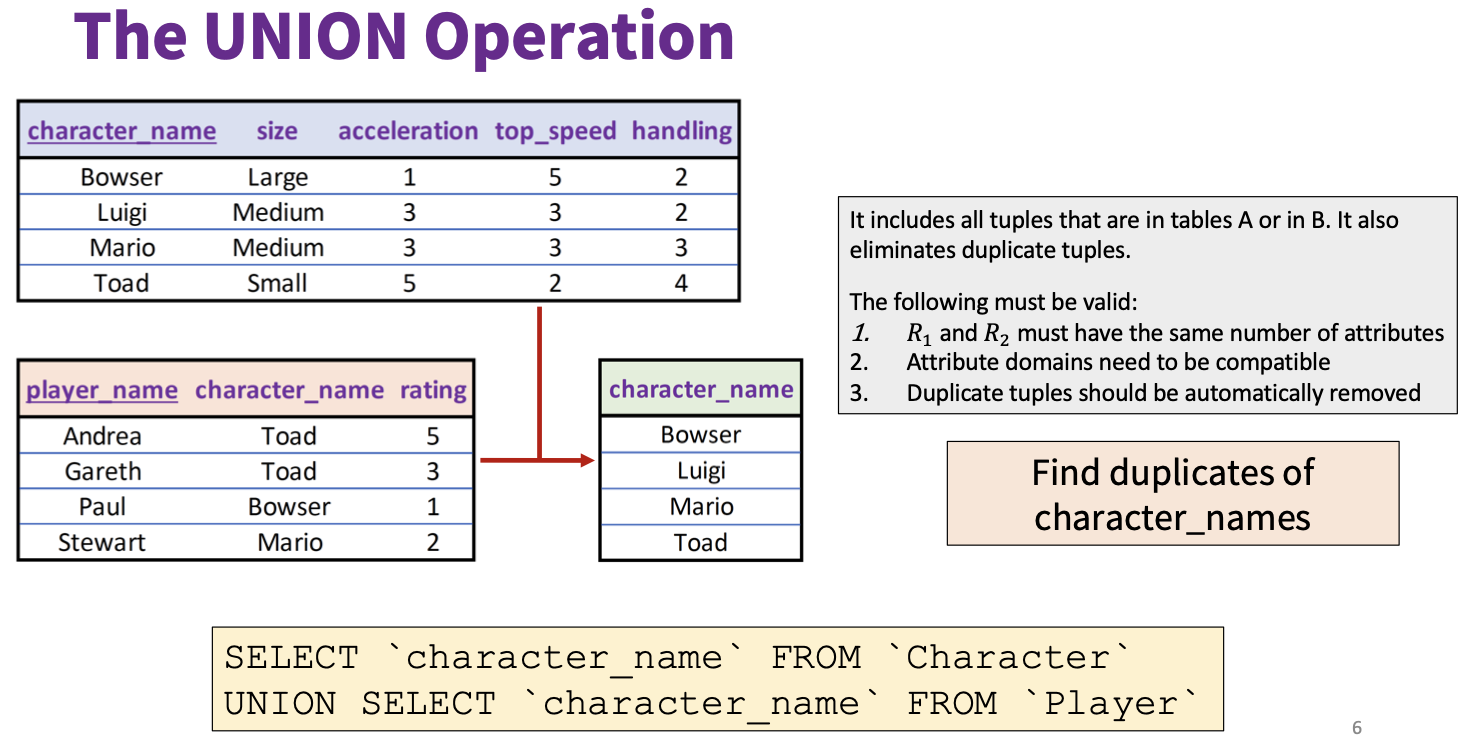
需要注意的是, UNION 执行的是对两个结果集的 并集 操作, 会筛选掉重复记录.
3.1.5 笛卡尔积运算: CARTESIAN PRODUCT
笛卡尔积可以视为对关系的 乘法, 它的效果是将 分别来自两个数据集合中的行 以 所有可能的方式 进行组合.
我们可以使用下列两种方式执行笛卡尔积:
1
2
3
4
SELECT * FROM table_1 CROSS JOIN table_2;
# 本质是第一种写法的语法糖
SELECT * FROM table_1, table_2;

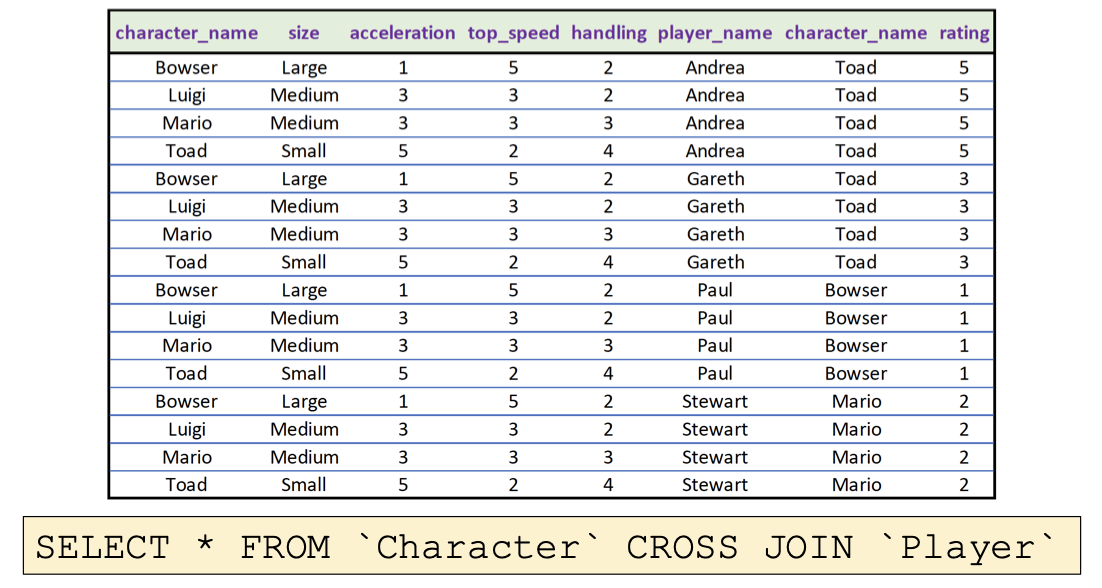
3.1.6 连接运算: JOIN
连接 运算可以视为 在水平方向上 对两个表的 合并, 其基本方法是: 将两个表中在共同数据项上相匹配的那些行合并.
连接运算本质是由 一个笛卡尔积运算 和 一个选取运算 所构成的:
-
首先用一个笛卡尔积完成对两个数据集合的乘法, 生成的结果集合包含两个数据集合中所有行的, 所有可能的组合.
-
然后对生成的结果集合进行 选取运算 , 确保只把 分别来自两个数据集合 并且 具有重叠部分 的行所 合并在一起.
SQL 提供的多种连接方式之间的区别在于: 它们在连接运算流程的第二步中 从 相互交叠的不同数据集合 中选取 用于连接的行 时所采用的方法不同:
| 连接类型 | 定义 |
|---|---|
内连接 INNER JOIN |
包含 Theta 连接, EQUI 连接 和 自然连接, 只连接满足匹配条件的行, 展现出的是两表 共同 的数据. |
左外连接 LEFT JOIN |
包含左边表中的全部行 (无论是否和右表匹配), 以及右边表中所有与左边表匹配的行. |
右外连接 RIGHT JOIN |
包含右边表中的全部行 (无论是否和左表匹配), 以及左边表中所有与右边表匹配的行. |
全外连接 FULL JOIN |
包含左右表的全部行, 不考虑匹配与否, 注意与交叉连接区分. |
交叉连接 CROSS JOIN |
生成笛卡尔积: 考虑数据集中任意行与另一数据集中任意行的两两组合. |
下面详细说明各种连接运算:
-
内连接:
内连接展现的是两表 共同 的数据.
内连接又因其匹配条件的不同而被区分为
Theta 连接,EQUI 连接和自然连接.-
Theta 连接是使用 等值以外的条件 (如大于等于, 小于等于, 不等于之类) 来匹配左右两表中行的内连接. -
EQUI 连接是使用 等值 (==) 条件 来匹配左右两表中行的内连接. -
自然连接是SQL中一种预定义的内连接, 可以视为语法糖, 它在匹配左右两表好似 自动判断 两表中相同名称的列, 而后形成匹配.我们无法在自然连接中人为指定哪些列被用于匹配, 但用于指定查询结果包含哪些列.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# Theta连接的例子 SELECT t1.prop, t2.char FROM table_1 t1 INNER JOIN table_2 t2 ON t1.axton != t2.axton; # EQUI连接的例子 SELECT t1.prop, t2.char FROM table_1 t1 inner JOIN table_2 t2 ON t1.axton=t2.axton; # 注: 上面的内连接相当于: SELECT t1.prop, t2.char FROM table_1 t1, table_2 t2 WHERE t1.axton=t2.axton; # 自然连接的例子 SELECT t1.prop, t2.char FROM table_1 t1 NATURAL JOIN table_2 t2;
-
-
外连接:
外连接不但返回符合连接和查询条件的数据行, 还 返回不符合条件的一些其他行. 外连接分三类: 左连接
LEFT JOIN, 右连接RIGHT JOIN和完整外部连接FULL JOIN:-
左连接除了返回两表中符合连接条件的数据行外, 还返回 左表中不符合连接条件但符合查询条件的数据行.
如果左表的某行在右表中没有匹配行, 则将右表对应的行处返回 空值 并与其连接.
-
右连接除了返回两表中符合连接条件的数据行外, 还返回 右表中不符合连接条件但符合查询条件的数据行.
如果右表的某行在左表中没有匹配行, 则将左表对应的行处返回 空值 并与其连接.
-
完整外部链接返回左表和右表中的所有行. 若某行在另一个表中没有匹配行, 则另一个表的对应列包含 空值, 否则这一整行包含对应的数据值.
1 2 3 4 5 6 7 8 9 10 11 12 13
# 左连接 # 以左表为主表, 右表没数据则为null SELECT m.Province,S.Name FROM member m LEFT JOIN ShippingArea s ON m.Province=s.ShippingAreaID; # 右连接 # 以右表为主表, 左表没数据则为null SELECT m.Province,S.Name FROM member m RIGHT JOIN ShippingArea s ON m.Province=s.ShippingAreaID; # 全外连接 SELECT m.Province,S.Name FROM member m FULL JOIN ShippingArea s ON m.Province=s.ShippingAreaID;
-
3.2 SQL 进阶
3.2.1 空值: NULL
在 SQL 中, 任何 未指定 的数据值称为 NULL, 它实际上应当被视为 一种状态 而非属性的值:

属性在下列的情况下可能被视为 NULL:
- 数据值 未知
- 数据值 不可取得
- 数据值 被隐藏
- 数据值 不适用 (坦白说我也没搞懂不适用是什么意思)
需要注意的是, NULL是独立于 True, False 之外的. 执行逻辑运算时需要遵循下列的 三值逻辑 规则:

注意, 我们不可使用 = 检测某个参数是否为 NULL. 要进行这样的检测, 需要使用关键字 IS:
1
2
3
4
5
6
7
# 返回的查询结果为空
SELECT name FROM VIPs
WHERE flat = NULL;
# 返回的查询结果是正常的
SELECT name FROM VIPs
WHERE flat IS NULL;
3.2.2 排序, 取极值, 求和与计数
我们可以使用 ORDER BY 语句对查询的结果集进行 排序:
1
2
3
4
5
# ORDER BY 默认按照升序对记录进行排序
SELECT col_1, col_2 FROM table ORDER BY attribute;
# 如果需要按照降序排序记录, 需要使用 DESC 关键字
SELECT col_1, col_2 FROM table ORDER BY attribute DESC;
注意: ORDER BY 子句可 同时使用多个列 作为排序条件, 但是必须确保 作为排序条件的每个列都在表中存在.
我们可以使用 MAX() 和 MIN() 取表中数据列的 极值:
1
2
3
4
5
# 取极大值
SELECT MAX(column_name) FROM table_name;
# 取极小值
SELECT MIN(column_name) FROM table_name;
我们使用 SUM() 函数返回 数值列的总数:
1
SELECT SUM(column_name) FROM table_name;
我们使用 COUNT() 函数返回 查询结果某一列项的数目:
1
2
3
4
5
# 若考虑重复结果:
SELECT COUNT(column_name) FROM table;
# 若要求不重复结果的数目:
SELECT COUNT(DISTINCT column_name) FROM table;
3.2.3 聚合函数 GROUP BY
聚合函数/集合函数 (COUNT, MAX, MIN, SUM, AVG) 往往需要搭配 GROUP BY 语句. 它用于 结合合计函数, 根据 一个或多个列 对结果集进行分组:
1
2
3
4
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
对聚合函数的理解如下: 考虑表
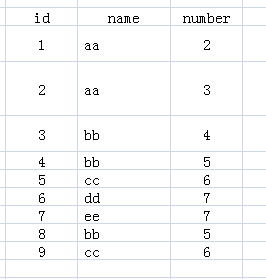
执行 SQL 语句
1
2
SELECT `name` FROM 'test'
GROUP BY `name`
则其查询结果的生成过程可视为:
-
首先 “执行” 语句中的
FROM 'test'得到一张和原表一模一样的新表. -
然后在这张表上执行
GROUP BY语句进行聚合分组, 在本例中需要基于name进行分组, 显然分组依据是将所有在name属性相同的行全部 “合并”, 此时执行结果是这样的一个虚拟的表: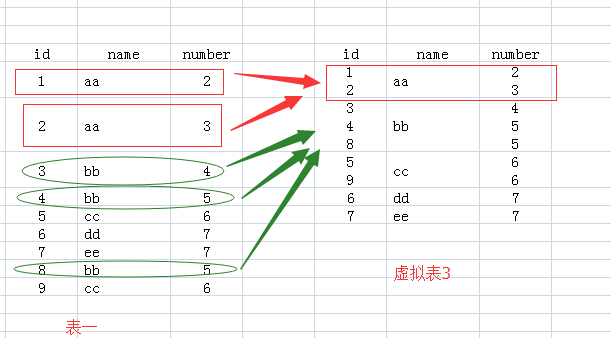
-
接下来才需要对这个虚拟表执行
SELECT后面的语句 (在此处是name).在这个例子中, 由于
name列被用于GROUP BY, 因此该列必然不存在重复值, 所以简单执行SELECT name就不会出错.但如果我们需要选择那些在虚拟表中有多个数据的单元格, 如
id,number, 就不能直接选择它们, 而需要使用 以多个数据作为输入, 输出单个数据的 聚合函数, 将这些多数据的单元格作为输入.假如我们执行了
1 2
SELECT name, SUM(number) FROM test GROUP BY name;
则结果就是在
虚拟表3的基础上, 对number列的每个单元格都执行SUM()聚合函数, 返回的表就是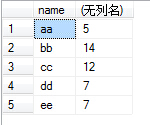
注: 对于 GROUP BY 多个字段的情况, 我们只需要将作为聚合分组依据的多个字段 视为整体字段 即可.
需要注意的是, 用于对表进行筛选的关键字 WHERE 无法和聚合函数 GROUP BY 一起使用. 我们需要使用 HAVING 子句:
1
2
3
4
5
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name
HAVING aggregate_function(column_name) operator value;
HAVING 子句的作用是 筛选满足条件的组, 在 分组之后 过滤数据, 而 WHERE 搜索条件在 执行分组操作前 应用.
注:
在语句中 同时含有 WHERE, GROUP BY, HAVING子句和聚合函数 时, SQL 语句的执行顺序如下:
- 先执行
WHERE子句查找符合条件的数据. - 执行
GROUP BY子句对数据进行分组, 并对GROUP BY子句执行形成的组运行聚集函数从而计算对应的值. - 最后执行
HAVING子句: 基于第二步中聚集函数的运算结果, 过滤掉不符合条件的组.
HAVING 子句和 WHERE 子句都可以让查询结果满足一定的条件限制, 但 WHERE 子句中限定的是 行, HAVING 子句中限定的是 组, 由此 WHERE 子句中 不能使用聚集函数.
3.2.4 嵌套查询语句
嵌套查询 指某个查询语句可以 嵌套 在另外一个查询语句的 WHERE 子句 中. 我们称外层的查询为 主查询, 而内层的查询为 从查询.
在执行含嵌套查询的语句时, 其语句的方向是 由内向外 的: 首先进行内层查询, 而外层查询 利用内层查询的结果集 作为条件进行查询.
如果子查询返回的结果是 单个值, 则它可以在任何涉及到表达式的地方作为常量使用.
若某个表只出现在子查询中而不在外查询中, 则该表的列 无法包含在输出中 (要想提取出子查询的结果集中的数据, 就只能依靠外层查询中的相关语句).
嵌套查询主要分为下列三类:
-
简单子查询 若子查询的结果是 单个值, 则这样的查询为 简单子查询.
-
IN嵌套查询 若查询的WHERE语句内包含IN关键字 (用于判断查询的表达式是否在多个值的列表中), 则该查询为IN嵌套查询: -
SOME嵌套查询 若查询的WHERE语句内包含SOME关键字 (用于判断查询的表达式是否满足SOME后的某一个条件), 则该查询为SOME嵌套查询: -
ALL嵌套查询 若查询的WHERE语句内包含ALL关键字 (用于判断查询的表达式是否满足ALL后的全部条件), 则该查询为ALL嵌套查询: -
EXISTS嵌套查询 若查询的WHERE语句内包含EXISTS关键字 (用于判断子查询是否返回了结果集), 则该查询为EXISTS嵌套查询:1 2 3 4 5
# 如果不存在Person_Id的记录, 则子查询没有结果集返回, 主语句不执行 SELECT * FROM Person WHERE exists ( SELECT * FROM Person WHERE Person_Id = 114514 );
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# IN 嵌套查询
SELECT NAME FROM person
WHERE countryid IN (
SELECT countryid FROM country
WHERE countryname = '下北沢'
);
# SOME 嵌套查询
SELECT NAME FROM person
WHERE countryid = SOME (
SELECT countryid FROM country
WHERE countryname = '下北沢'
);
# ALL 嵌套查询
SELECT NAME FROM person
WHERE countryid > ALL (
SELECT countryid FROM country
WHERE countryname = '下北沢'
);
3.2.5 视图
在 SQL 中, 视图 是基于 查询结果 的, 可视化的表. 它包含行和列, 且字段实际上来自于被查询的一个或多个数据库中真实存在的表中.
我们可以根据需要向视图中添加 SQL 函数和语句, 视图中的函数和语句不会影响被查询数据库的设计和结构.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 创建 View 语法
CREATE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
# 在创建后我们可以像查表一样查询这个View中的数据
SELECT * FROM [view_name]
# 视图可以被更新
CREATE OR REPLACE VIEW view_name AS
SELECT column_name(s)
FROM table_name
WHERE condition
# 也可以被撤销
SQL DROP VIEW Syntax
DROP VIEW view_name
3.2.6 存储过程
存储过程 本质是一段 预先编译好, 可供复用 的声明式 SQL 语句.
SQL 语句需要 先编译然后执行, 而存储过程(Stored Procedure) 是一组 经编译后 存储在数据库中, 可完成特定功能的 SQL 语句集, 可通过指定存储过程的名字并给定参数 (若它含有参数) 来调用执行.
存储过程的实质是 函数, 由 SQL语句 和 控制结构 组成. 数据库中的存储过程可以看做是对编程中面向对象方法的模拟, 它允许我们控制数据的访问方式.
存储过程的优点包括:
- 增强
SQL语言的功能和灵活性. - 可增强 可复用性.
- 由于已经预先编译, 因此存储过程具有 较快的执行速度.
- 针对数据库对象的操作可以被简化为 对某个存储过程的调用语句, 从而在传输
SQL指令时 减少对网络带宽的消耗. - 可以通过 限制执行某个存储过程的权限 实现对相应数据 访问权限的控制, 提升 数据安全性.
存储过程的创建语法形如:
1
2
3
4
5
6
7
8
9
10
11
DELIMITER //
CREATE PROCEDURE myproc(
IN p varchar,
OUT q int,
INOUT r boolean)
BEGIN
SELECT COUNT(*) INTO q FROM table;
END //
DELIMITER ;
其删除语法为:
1
DROP PROCEDURE myproc;
需要注意: MySQL 默认以 “;” 为分隔符, 若未声明分割符, 则编译器会把存储过程视为 SQL 语句, 因此编译过程会报错.
因此, 要事先用 “DELIMITER //” 声明作为 前段分隔符, 让编译器把两个 “//” 之间的内容视为 存储过程的代码, 从而避免执行它们. 最后一行 “DELIMITER ;” 的作用是把 分隔符还原.
根据需要, 存储过程可能会有 输入 (IN), 输出 (OUT) 或 既作为输入又作为输出 (INOUT) 的参数:
IN参数的值必须在调用存储过程时指定, 在存储过程中修改该参数的值不能被返回.OUT参数的值可在存储过程内部被改变, 并可返回.INOUT参数的值在调用时指定, 并且可被改变和返回.
我们还可在存储过程中 定义并赋值局部变量:

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
DELIMITER //
CREATE PROCEDURE GetTotalOrder()
BEGIN
# 声明变量时需要同时指定其名称, 数据类型, 默认值
DECLARE totalOrder INT DEFAULT 0;
SELECT COUNT(*)
INTO totalOrder -- 可使用 INTO 将查询的结果赋值给变量
FROM orders;
SELECT totalOrder;
END //
DELIMITER;
CALL GetTotalOrder(); -- 调用所定义的存储过程
需要注意: 存储过程在数据库中是经过 预编译 后被存储在 information_schema 库 中的 routines 表 中的. 我们可以使用下列命令查询数据库中的所有 Stored Procedure:
在本课程中, Slides 里出现了在 Stored Procedure 中定义和使用 局部变量 以及 直接使用用户变量 的例子. 此处简单说明 局部变量 和 用户变量:
- 用户变量可以 直接使用, 形如
@var. 其有效生命周期在 单次数据库连接 中, 断开连接时变量消失. - 局部变量需要 先定义, 后使用, 定义时必须 声明变量名和数据类型, 其有效生命周期在函数或存储过程的作用域中.
1
2
SELECT `routine_name` FROM `information_schema`.`routines`
WHERE `routine.type`=`PROCEDURE` AND `routine_schema`=`classicmodels`;
此外, 我们可以在存储过程中应用 条件函数体, 循环函数体 等控制语句:

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 使用 IF-THEN 条件语句的存储过程样例
CREATE PROCEDURE GetCustomerLevel(
IN pCustomerNumber INT,
OUT pCustomerLevel VARCHAR(20)
)
BEGIN
DECLARE credit DECIMAL(10,2) DEFAULT 0;
SELECT creditLimit INTO credit FROM customers
WHERE customerNumber = pCustomerNumber;
IF credit > 50000 THEN
SET pCustomerLevel = 'PLATINUM';
END IF;
END
# 使用 CASE 条件语句的存储过程片段样例, 注意对默认情形 “ELSE” 的声明
CASE customerCountry
WHEN 'USA' THEN
SET pShipping = '2-day Shipping';
WHEN 'Canada' THEN
SET pShipping = '3-day Shipping';
ELSE
SET pShipping = '5-day Shipping';
END CASE;
我们可以在存储过程中定义 游标 (Cursor), 它是使我们能够在存储过程中对查询得到的表中的数据 逐行处理 的工具.
游标的一般使用方法是: 声明游标 - 打开游标 - 取出结果 - 关闭游标.
我们一般用 FOR 循环操作游标.
注意; 游标具备下列的性质:
- 只读: 在
MySQL中我们只能使用游标 遍历访问表的每一行, 而不能对这一行的数据进行修改. - 不可滚动: 游标只能 逐行地 遍历表, 不可跳过任意一行.
- 数据敏感: 游标所访问的是数据表本身而非表的某个
Buffer, 若游标指向的表中的某个数据被修改, 则该修改会立刻体现在游标提出的数据上.
(实在是写不下去了, 游标剩下的部分不写了, 开摆!)
3.2.7 触发器
触发器的实质是一段预先存储的 SQL 程序, 在监听到发生对应的数据库操作 (如插入, 表更新和表删除) 时会被唤起调用 (Invoked), 一般在 SQL 查询执行前或执行后 运行.
同时, 触发器也可被编程于执行 计划任务 (Scheduled Tasks).
由于其先天具备 Watchdog 的特性, 触发器常被用于检验和审核数据库中执行的操作, 维护数据库的完整性, 避免异常发生.
触发器的创建语法如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
CREATE TRIGGER
# 标识触发器名称, 用户自行指定
trigger_name
标识触发时机, 取值为 BEFORE 或 AFTER;
trigger_time
# 标识触发事件, 取值为 INSERT, UPDATE 或 DELETE;
trigger_event
ON tbl_name -- 标识建立触发器的表名, 即在哪张表上建立触发器.
FOR EACH ROW
BEGIN
trigger_stmt -- 触发器程序体, 可以是一句SQL语句, 或者由 BEGIN 和 END 包络的语句段.
END
触发器的信息查询和删除如下:
1
2
3
4
5
# 查询触发器信息
SHOW TRIGGERS;
# 删除某个触发器
DROP TRIGGER trigger_name;
需要注意:
-
和存储过程类似, 为了避免
SQL将在BEGIN和END间, 每一行由分号;结束的语句段错误解析导致触发器被视为不完整的SQL语句, 需要使用分隔符DELIMITER标记整个Trigger语句段. -
触发器一般被分为三类:
-
INSERT 型触发器
插入某一行时激活触发器, 可能通过 INSERT, LOAD DATA, REPLACE 语句触发.
-
UPDATE 型触发器
更改某一行时激活触发器, 可能通过 UPDATE 语句触发.
-
DELETE 型触发器
删除某一行时激活触发器, 可能通过 DELETE, REPLACE 语句触发.
-
-
在
INSERT型触发器中,NEW用来表示将要(BEFORE) 或已经 (AFTER) 插入的新数据.在
UPDATE型触发器中,OLD用来表示将要或已经被修改的原数据,NEW用来表示将要或已经修改为的新数据.在
DELETE型触发器中,OLD用来表示将要或已经被删除的原数据. -
我们可以使用
FOLLOWS和PRECEDES实现触发器的 菊链式调用:FOLLOWS允许新触发器在旧的触发器 执行完成后 被激活.PRECEDES允许新触发器在旧的触发器 执行之前 被激活. -
我们也可以对触发器进行编程, 令其在被激活时调用某个 存储过程.
1 2 3 4 5 6 7 8 9
CREATE TRIGGER before_accounts_update BEFORE UPDATE ON accounts FOR EACH ROW BEGIN CALL CheckWithdrawal ( OLD.accountId, OLD.amount - NEW.amount ); END
3.3 数据库事务的概念和处理
数据库事务是 构成某个单一逻辑单元 的 一系列操作 组成的 集合. 一个典型的数据库事务形如:
1
2
3
4
5
6
BEGIN TRANSACTION # 某个事务的开始
sql_clause_1;
sql_clause_2;
...
sql_clause_n;
COMMIT/ROLLBACK # 事务执行完毕, 提交对数据库进行的修改或回滚至原来的状态
需要注意:
- 数据库事务中包括的一条或多条数据库操作构成了一个 逻辑上的整体.
- 由于它们在逻辑上被组织成一个整体, 这些数据库操作要么 全部成功, 要么 全部不执行.
- 构成数据库事务的所有操作要么 全部对数据库产生影响, 要么 全都不产生影响.
- 上述性质恒成立, 无论数据库是否出现故障或是否存在并发事务.
事务的执行过程可以被简化为:
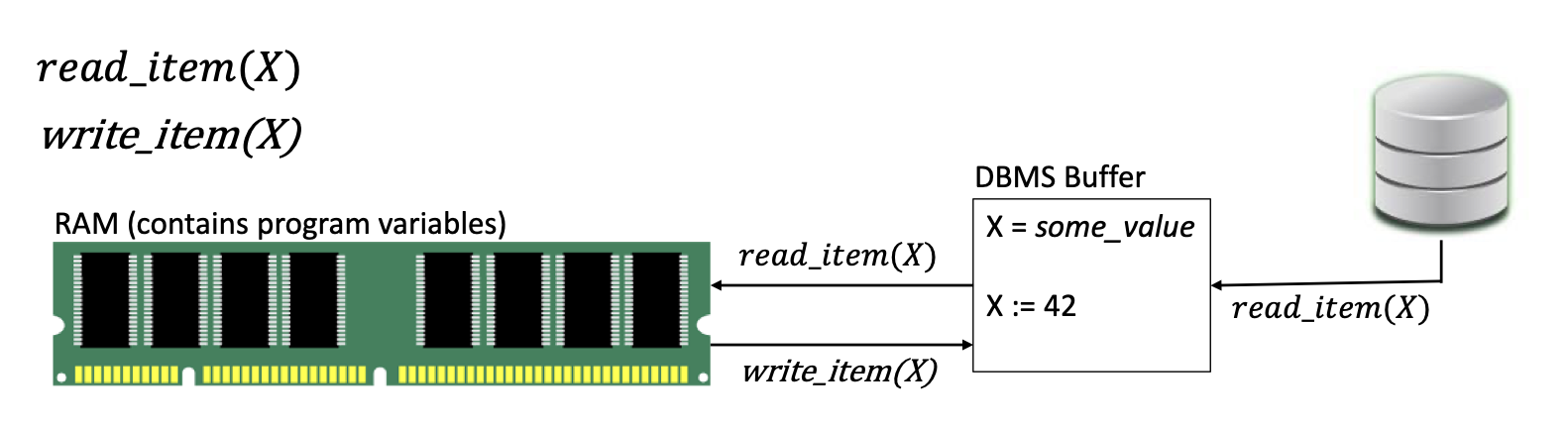
- 系统为每个事务开辟一个 私有的缓冲区 .
- 事务读操作 将数据从主存中复制到缓冲区内.
- 事务写操作 修改缓冲区内的数据.
- 若执行
COMMIT(提交), 则缓冲区内的数据 覆盖主存中的对应原版 . - 若执行
ROLLBACK(回滚), 则 缓冲区内的数据被丢弃.
为了确保关键操作的必然可靠性, 数据库事务的存在是必要的. 考虑下列的例子:
Axton 给 Derek 转账 $114514$ 元, 这个操作在形式上显然是一个单一的操作, 但在银行的数据库系统中会被至少 拆分为两个步骤:
- 将
Axton的账户余额减少 $114514$ 元. - 将
Derek的账户余额增加 $114514$ 元.
而显然在这两个单独的过程中可能会出现下列的问题:
- 第一步执行成功, 但第二步执行失败或系统在执行第二步之前突然崩溃, 由此导致
Derek并没有成功收款. - 系统在第二步刚刚执行成功时崩溃, 而重启时崩溃前的转账记录丢失.
- 在
Axton向Derek转账的同时, 还有多人也在向Derek转账, 由此导致Derek的账户余额出现异常.
其中, 我们一般称第二类 导致对数据库执行的修改丢失 的问题为 暂更新问题 (Temporary Update Problem):

而称第三类 导致对数据的更新异常的 问题为 丢更新问题 (Lost Update Problem):

而若将上述的转账流程涉及的所有操作包含在同一个数据库事务中, 则会:
- 若数据库操作失败或系统崩溃, 系统能够 以事务为单位进行数据恢复 , 从而避免了第一, 二类问题;
- 若有多个用户同时操作数据库, 数据库能够 以事务为单位进行并发控制, 从而将多个转账操作进行隔离, 避免了第三类问题.
为了实现对上述问题的预防和避免, 数据库事务需要具备所谓的 ACID 特性:
-
A: Atomicity原子性:事务中的所有操作要作为一个整体, 如同原子一般不可再分: 要么全部执行成功, 要么全部执行失败.
-
C: Consistency一致性:事务的执行结果必须使数据库 从某个一致性状态 转化到 另一个一致性状态. 而一致性状态指:
- 满足 数据库的完整性约束
- 正常反映数据库所描述的现实世界的真实状态, 如转账前后两个账户的金额总和需保持不变.
-
I: Isolation隔离性:并发执行的事务被彼此隔离, 不会相互影响: 它们对数据库的影响和它们一个接一个地串行执行时相同.
-
D: Durability持久性:事务一旦提交, 它对数据库的更新就是 持久的, 任何故障和意外事件都不会导致数据丢失.
事务的 ACID 特性中, C, 数据库一致性, 是 事务的根本追求. 一般地, 对一致性的破坏主要来源于事务的并发执行或事务/系统故障. 在本课程中, 我们只关心防止并发执行破坏数据库一致性的基本原理和方法:
在并发执行数据库事务时, 必须通过 调度 (Scheduling) 解除不同并发执行的事务之间可能造成的冲突, 否则就会出现各种异常, 破坏事务间的隔离性, 影响数据库的一致性.
一般来说, 异常被分为下列四种:
Lost Update丢更新异常Temporary Update暂更新异常Dirty Write脏写异常
在本课程中, 我们介绍了前两种异常:
Lost Update 丢更新异常的成因是: 在某个调度中, 事务 $T_1$, $T_2$ 读入相同的数据值 $X$, 进行不同的计算, 并先后修改并提交对 $X$ 的改动. 则此时后提交的事务会将先提交的事务对 $X$ 进行的修改覆盖掉.

Temporary Update 暂更新异常的成因是: 在某个调度中两个数据库事务共享一片 Database Buffer, 对同一个数据进行读写操作.
若第一个事务 $T_1$ 对 数据 $X$ 的修改 被第二个事务 $T_2$ 读取, 进一步修改并提交, 而 $T_1$ 所做更改在 $T_2$ 读取了 $X$ 后回滚, 则会出现 “$T_2$ 读取了本不该出现的, 被 $T_1$ 修改过的数据” 的情况.

定义 (调度, Schedule)
调度 定义为对数据库不同事务中语句的 交错穿插安排.
下面考虑 包含 $n$ 个事务 $T_1, \cdots, T_n$ 的调度 $S$.
$S$ 可以进一步地表示为调度指令执行的简写序列, 其中:
b:begin, 开始一系列事务的调度r:read, 读操作.w:write, 写操作.e:end, 表示事务调度的终止.c:commit, 表示提交对缓存中数据的修改到主存.a:abort, 终止调度序列.
注意: r, w 操作涉及对数据库项的操作, 在实际表示时常常使用下标表明该操作是属于哪个事务的.
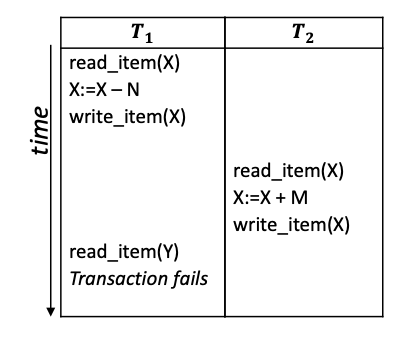
举例, 调度序列
\[S_a: r_1(X);~ w_1(X);~r_2(X);~w_2(X);~r_1(Y);~a_1;\]表示如下表所示的调度:
定义 (冲突, Conflict)
称调度序列中的某两个操作是 冲突(
Conflict) 的, 若它们满足下列特征:
- 这两个操作分属 不同的事务.
- 这两个操作访问了 同样的数据.
- 这两个操作中至少有一个是 写操作.
由于调度中的冲突操作会导致 数据不一致, 我们需要构造 完备调度:
定义 (完备调度, Complete Schedule)
称满足下列条件的调度为 完备调度:
- 调度 $S$ 中的指令恰好是 $n$ 个事务 $T_1, \cdots, T_n$ 中的.
- $T_1, \cdots, T_n$ 里任何事务中的任意一对指令的 相对顺序 在 $S$ 中均 保持.
- 调度中任意两个冲突操作都 不能同时被执行.
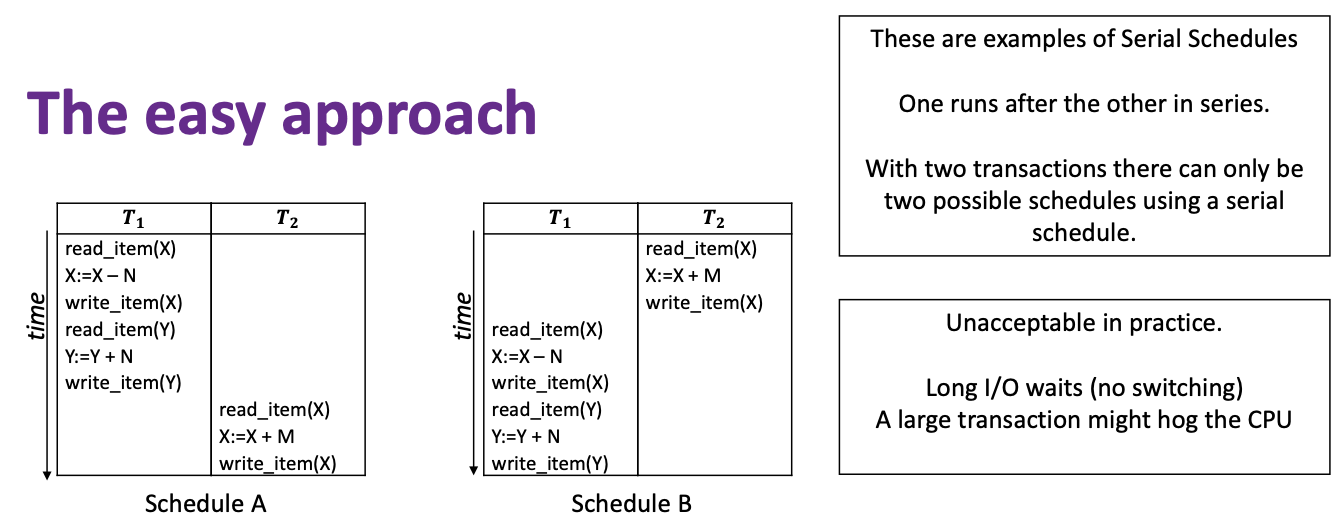
构造完备调度最简单的方法是不考虑穿插, 让所有事务 串行执行:
但为了避免过大的性能损失, 在实际情况下我们必须穿插事务指令, 构造并行调度 (Allow Interleaving). 由此, 我们需要明确: 如何确定某个并行调度不会导致异常:
定义 (可序列化调度, Serializable Schedule)
称某个包含 $n$ 个事务的调度 $S$ 为 可序列化的, 若它 等价于 (一般认为是冲突等价) 某个包含同样 $n$ 个事务的串行调度.
为了确保我们将要构造的并行调度是可序列化的, 我们还要引入 冲突等价 的概念: (显然, 如果只考虑输出值等价的话很容易出现问题)
定义 (冲突等价, Conflict Equivalence)
称两个不同顺序, 包含相同的 $n$ 个事务的调度是 冲突等价 的, 若对任意一对冲突操作, 这对冲突操作在两个不同调度中的 相对顺序 相同, 反之则称其为 冲突不等价 (
Not Conflicting Equivalence) 的.
因此, 我们现在可以给出 真正可用的 可序列化调度 的定义: 若某个调度 $S$ 和某个串行调度 冲突等价, 则称 $S$ 是 可序列化 的.
本课程中教授了如下的, 快速判断调度是否为可序列化的:
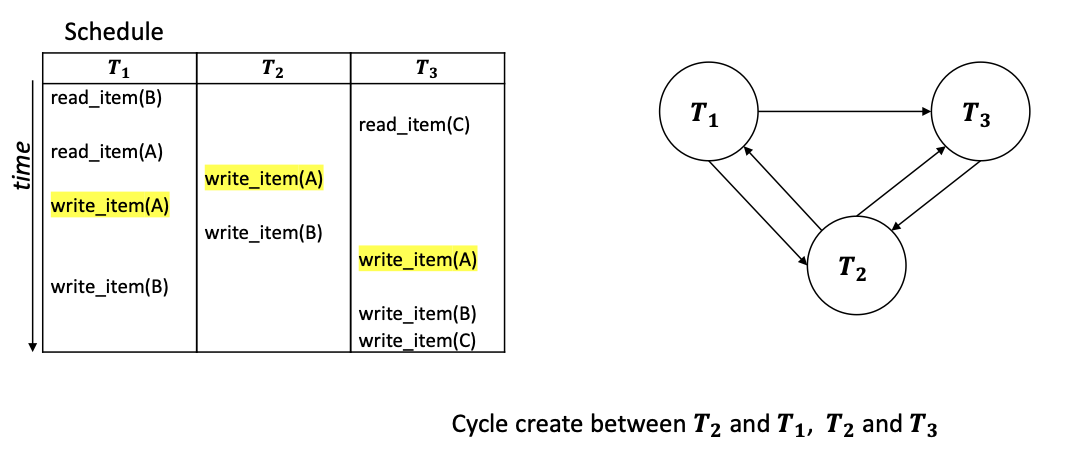
使用有向图判断: 只考虑读写操作, 依次检查调度中涉及的每个事务 $T_i$.
-
将每个事务用一个节点表示,
-
对调度中涉及的每一对冲突操作 $o_1, o_2$, 画一条从 更早发生的操作所属事务节点 到 更晚发生的操作所属的事务节点 的 有向边.
最后检查构造的图. 若图是 无圈的, 则该调度为 可序列化的.
REFERENCE:
left join 和 left outer join 的区别
Understanding cartesian product in SQL
Advantages and Disadvantages of Using Stored Procedures – SQL