
不确定性的量化和概率推理
在本章中, 我们将借助概率论考虑 Agent 在不确定环境下的行动问题, 并引入贝叶斯网络构造 Agent 在不确定性下进行推理的网络模型.
4.1 不确定性
我们首先对 不确定性问题 给出定义.
定义 4.1.1 (不确定性)
我们称满足下列特性的问题为 不确定性问题:
- 要得到该问题的确定没有任何意外情况的规则需要列出前提和结论的完整集合, 而为了列出这个集合需要极为庞大的工作量, 给出的规则也难以使用.
- 对于问题涉及的领域, 并不存在完整的结论能够支撑我们给出完备的规则.
- 即便在给出了完备规则的前提下在一些情形下我们也无法进行完整的测试, 因此不能通过逻辑联系得出结论.
在具有确定性的问题中, 世界是由一系列 在某种特定情形下, 或成立或不成立的事实 构成的, 而在这样的不确定性问题下, Agent 的知识只能提供对相关语句的 信念度 (Degree of belief): 也就是一个介于 $0-1$ 之间的数值, 作为对这一语句实际发生的可能性的信念, 本质上是概率值, 因而我们需要使用概率论处理信念度.
在真实世界中, 实际上并不具备 “不确定性”. 对 Agent 而言, 概率声明之所以具备不确定性是因为它对现实世界的了解是有限的, 只能够通过已知的一系列有限的知识状态作出推断.
4.2 概率语法规则
为了让 Agent 表示并使用概率信息, 我们下面给出一种 形式语言 的定义.
逻辑断言所考虑的是要严格地排除那些断言不成立的情形, 而概率断言考虑的是各种情形发生的可能性.
所有可能情形所组成的集合称为 样本空间, 样本空间中的不同情形是 互斥的 和 完备的, 每个情形 $\omega$ 都被赋予一个对应的数值概率 $P(\omega)$. 并且满足:
\[\text{for each }\omega, ~~0 \leqslant P(\omega) \leqslant 1, ~~ \sum_{\omega \in \Omega} P(\omega) = 1.\]我们称 先验概率 (Prior probabilities) (或无条件概率) 为 在不知道其他信息的情况下对命题的信念度, 而认定 后验概率 (Posterior probabilities) (或条件概率) 为 给定一些已知的信息 (证据) 的情况下对命题的信念度.
我们将结合 命题逻辑中的元素 和 约束满足问题语法中的记号 描述命题. 在概率论中, 变量被称为 随机变量 (Random Variables), 而每个随机变量都具有一个 定义域 (Domain), 由该随机变量能取的所有值组成. 随机变量本身可以表示基本命题, 而将基本命题用命题逻辑中的逻辑链接符相连就组成了更为复杂的命题. 如, 我们可以将 “如果一个人叫 Axton, 他又很强, 那么他是姚老师的概率是 $0.9$” 表示为:
我们还可以使用逗号分隔多个变量, 表示多个变量的分布. 变量 Weather 和 Cavity 的所有可能取值的乘法规则可以被精炼为下述的单一等式
4.3 使用完全联合分布进行推理
我们可以通过 已观察到的证据计算命题的后验概率: 使用完全联合概率分布作为 “知识库”, 就可以从中导出关于问题域的所有相关问题的答案:
考虑一个由三个布尔变量 $\text{Toothache}, \text{Cavity}$ 和 $\text{Catch}$ 组成的分问题域, 其完全联合分布为一个 $2 \times 2 \times 2$ 的表格:

-
首先, 最常见的任务是 提取关于随机变量的 某个子集 或 某个变量 的概率分布, 这样的过程一般称为 边缘化 (
Marginalization) 或 求和消元 (Summing Out).对任何两个变量集合 $Y, Z$, 有下列的 通用边缘化规则:
\[P(Y) = \sum_{z \in Z} P(Y, z)\]其中 $\sum_{z \in Z}$ 指针对变量集合 $Z$ 的所有可能取值组合进行求和. 我们还可以使用条件概率将上述规则变形如下:
\[P(Y) = \sum_{z \in Z} P(Y \vert z) P(z).\] -
在一些情况下, 我们还需要基于一些已知的变量证据而计算另一些变量的条件概率. 设 $E$ 为证据变量集合, $e$ 为其观察值, 并设 $Y$ 为其余的未观测变量, 查询为 $P(X \vert e)$, 则其值为:
\[P(X \vert e) = \alpha P(X, e) = \alpha \cdot \sum_{y \in Y} P(X, e, y).\]其中 $\alpha = \frac{1}{P(e)}$, 对于 $\forall y \in Y$ 是不变的, 因此可以视为一个归一化常数.
4.4 应用贝叶斯规则
从概率的乘法规则和条件概率公式可得:
\[P(b \vert a) = \frac{P(a \vert b) P(b)}{P(a)}.\]对于多值变量的更一般情况, 可以表为
\[P(Y \vert X) = \frac{P(X \vert Y) P(Y)}{P(X)}.\]4.5 不确定性问题域中的知识表示
我们已经知道, 使用完全联合概率分布就可以 使用不同的公式或定理, 结合给定概率表中的数据, 回答关于问题域的任何问题. 但随着变量数目不断增加, 概率表和公式都会相应地变得更加复杂, 最终复杂度增加到对我们而言完全无法操作的程度. 除此之外, 对每种可能的情形都分别指定概率也是不自然的.
我们同时了解, 变量之间的独立性与条件独立关系可以减少为 定义完全联合概率分布所需指定的概率数目. 我们将使用 贝叶斯网络 (Bayesian Network) 表示变量间的依赖关系:
定义 4.5.1 (贝叶斯网络)
贝叶斯网络是一个每个节点上都标注了 定量的概率信息 的有向图. 它满足:
- 每个节点对应概率问题中的一个随机变量, 该变量既可以是离散的, 也可以是连续的.
- 使用 一组有向边或箭头 连接节点对. 若有从 $X$ 指向 $Y$ 的箭头, 则称 $X$ 为 $Y$ 的一个父节点, 图中无圈 (也就是说这个图是一个有向无圈图,
DAG).- 每个节点 $X_i$ 都有一个条件概率分布 $P(X_i ~\vert~ \text{Parents}(X_i))$ 用以 量化其父节点对该节点的影响.
可以看出, 在表示贝叶斯网络的图中, 图的拓扑结构: 节点和边的集合, 精确简洁地描述了 在问题域中成立的条件独立关系. 箭头的直观含义表示 $X$ 对 $Y$ 有直接的影响, 也就是说 原因应该是结果的父节点. 在基于现有知识确定贝叶斯网络的拓扑结构 (也就是构造出变量之间的关联) 后, 只需要 为每个变量指定它相对其父节点的条件概率 即可.
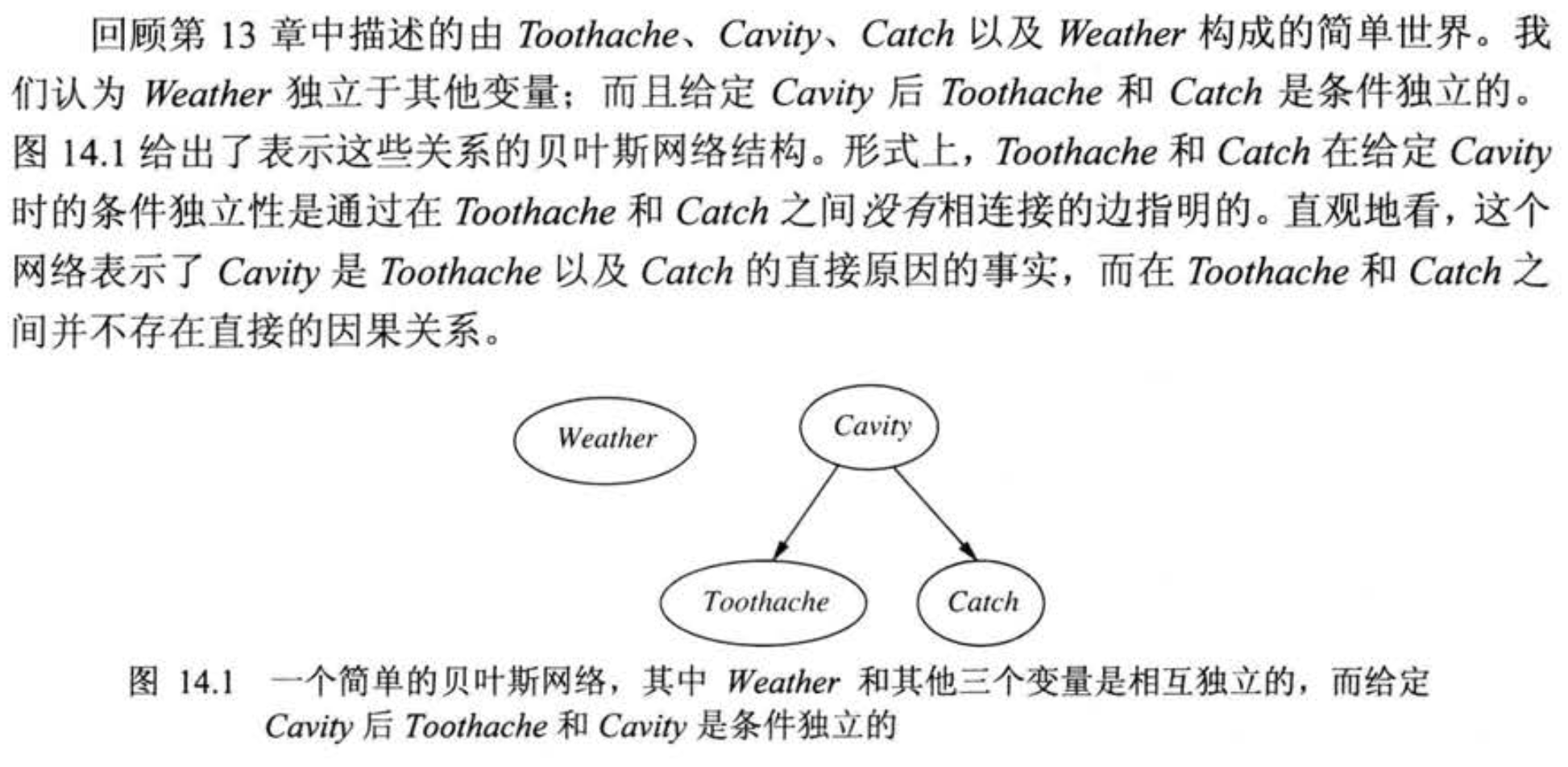
我们下面说明贝叶斯网络的含义. 我们可以通过下列两种方式理解贝叶斯网络的语义:
- 将贝叶斯网络视为 对联合概率分布的表示.
- 将贝叶斯网络视为 对一组条件依赖性语句的编码.
上述两种理解方式在事实上等价. 第一种理解方式有助于更好地构造贝叶斯网络, 而后者有助于我们设计推理过程.
我们首先看第一种理解方式. 从语法上看, 贝叶斯网络就是一个 每个节点都附有数值参数的有向无环图. 每个节点上的数值参数在我们对网络赋予语义之后, 就和条件概率一一对应.
在联合分布中, 任一个一般条目是对 每个变量赋予一个特定值的合取概率, 如
\[P(X_1 = x_1 \wedge X_2 = x_2 \wedge \cdots \wedge X_n = x_n).\]它一般被简化为 $P(x_1, x_2, \cdots, x_n)$. 这个条目的值可由公式
\[P(x_1, x_2, \cdots, x_n) = \prod_{i=1}^{n} \theta(x_i ~ \vert ~ \text{parents}(X_i))\]给出, 其中 $\text{parents}(X_i)$ 表示为 $\text{Parents}(X_i)$ 的变量的出现在 $x_1, x_2, \cdots, x_n$ 中的取值. 因此, 联合概率分布中的每个条目 都可表为贝叶斯网络的条件概率表中适当元素的乘积.
不难看出, 参数 $\theta(x_i ~ \vert ~ \text{parents}(X_i)$ 就是 联合分布蕴含的条件概率 $P(x_i ~ \vert ~ \text{parents}(X_i)$. 因此上面的公式可以写为
\[P(x_1, x_2, \cdots, x_n) = \prod_{i=1}^{n} P(x_i ~ \vert ~ \text{parents}(X_i)).\]我们下面解释 如何构造贝叶斯网络. 首先基于条件概率, 利用概率的乘法规则重写联合概率分布:
\[\begin{aligned}P(x_1, x_2, \cdots, x_n) &= P(x_n ~\vert~ x_{n-1}, \cdots, x_1) \cdot P(x_{n-1} ~\vert~ x_{n-2}, \cdots, x_1) \cdots P(x_2 ~\vert~ x_1)\cdot P(x_1) \\ &=\prod_{i=1}^{n} P(x_i ~\vert~ x_{i-1}, \cdots, x_1). \end{aligned}\]上述等式称为 链式规则, 它对于任一个随机变量集合都成立. 实际上, 联合分布的描述就等价于下列的断言:
对网络中的每个变量 $X_i$, 若 $\text{Parents}(X_i) \subseteq {X_{i-1}, \cdots, X_1}$, 则
\[P(X_i ~\vert~ X_{i-1}, \cdots, X_1) = P(X_i ~\vert~ \text{Parents}(X_i)).\]而只要按照 与蕴含在图结构中的偏序一致的顺序对节点编号, 条件 $\text{Parents}(X_i) \subseteq {X_{i-1}, \cdots, X_1}$ 就能得到满足.
上述公式说明: 只有在 给定父节点后, 每个节点条件独立于节点排列顺序中的其他父=祖先节点 时, 贝叶斯网络才是问题与的正确表示. 我们可用下列的贝叶斯网络构造方法满足这个条件:
- 给定节点 (
Nodes): 确定对 问题域建模所需的变量集合, 对变量排序得一个序列 ${X_1, \cdots, X_n}$. 注意, 若在排序时让原因排列在结果前, 则我们得到的网络会更致密. -
给定边: 从 $1$ 到 $n$ 遍历变量 $i$, 对每个 $i$, 执行:
2.1 从 $X_1, \cdots, X_{i-1}$ 中选择 $X_i$ 的父节点的最小集合使得
\[P(X_i ~\vert~ X_{i-1}, \cdots, X_1) = P(X_i ~\vert~ \text{Parents}(X_i)).\]得到满足.
2.2 在每个父节点和 $X_i$ 之间插入一条边.
2.3 写出条件概率表 $P(X_i ~\vert~ \text{Parents}(X_i)).$
注意, 直观上节点 $X_i$ 的父节点应该包含 $X_1, \cdots, X_{i-1}$ 中 所有直接影响 $X_i$ 的节点.
由于每个节点 只和排在它前面的父节点相连, 因此用这种构造方法构造出的网络一定是无圈的.
4.6 贝叶斯网络的精确推理
概率推理系统的基本任务是, 在给定某个已观察到的事件 (也就是 证据变量 (Evidence Variables)) 后, 计算一组 查询变量 (Query Variables) 的 后验概率分布.
规定以下记号:
- 查询变量用 $X$ 表示.
- 证据变量集 $E_1, \cdots, E_m$ 用 $E$ 表示.
- 观察到的特定事件用 $e$ 表示.
- 非证据, 非查询变量 (隐藏变量) 集 $Y_1, \cdots, Y_l$ 用 $Y$ 表示.
这样, 全部变量的集合表为:
\[X = \{X\} \cup E \cup Y.\]而典型的查询是询问后验概率 $P(X ~\vert~ e)$.
我们已经知道, 任何条件概率都可通过 将完全联合概率分布 中的某些项 相加 而计算得出. 回顾 4.3 节中引入的公式:
由于贝叶斯网络给出了完全联合概率分布的完整表示, 联合概率分布中的项 $P(X, e, y)$ 可被写为 网络中的条件概率的乘积 的形式. 由此, 我们可以 在贝叶斯网络中通过计算条件概率的乘积 再求和, 得到所需要的结果.