数据科学中的统计学常识
在本章中, 我们将简述一些在数据科学课程中所涉及的基本统计学术语, 概念和定理.
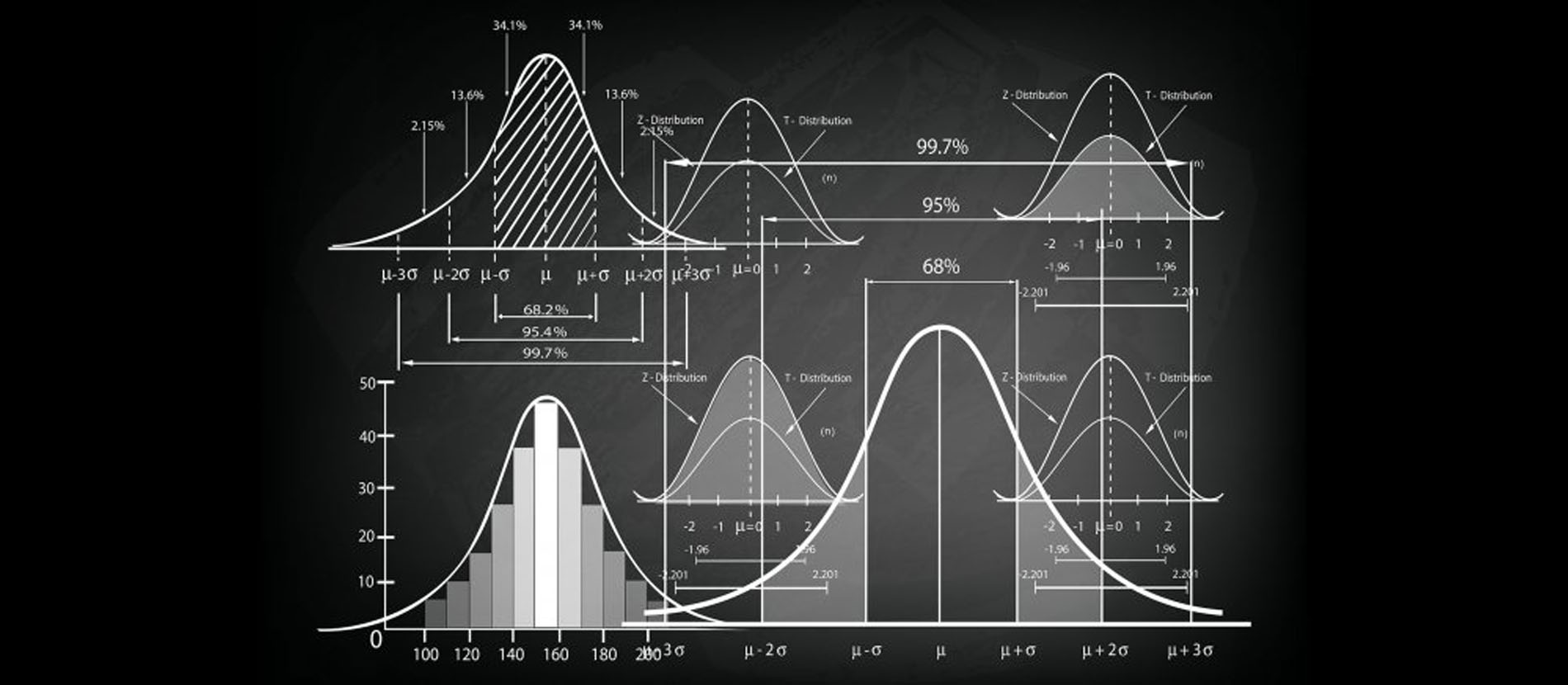
1. 数据的集中分布趋势
统计研究涉及大量数据的分析, 加工和处理. 在大多数情况下, 我们所收集的数据都会呈现基于某个 “中心” 而分布的趋势. 我们使用均值, 众数, 中位数描述和刻画数据的集中分布趋势.
1.1 均值 (mean)
最常用的均值是 算术平均值 (mean, arithmetic mean). 均值是平均数的一般度量, 也就是 调和平均值 的倒数. 其定义为:
同时, 我们称明显和其他数据偏离的, 极高或极低的数值为 异常值, 它们的存在会影响数据的分布态势. 当异常值将数据向中心数据的左边或右边 “拉” 时, 即会产生 偏斜数据.
我们继续介绍 几何平均值 (geometric mean). 它常用于计算增长率和收益率, 受异常值的影响更小, 但由于其定义, 被求平均的数值不可以包含零或负数.
1.2 众数 (mode)
众数是一组数据中出现次数最多的变量值, 体现数据的普遍性, 在数据刻画中往往反映一般水平和普遍水平.
1.3 中位数 (median)
中位数是一组数据按照大小顺序排列后, 恰好处于中间位置的数值, 也就是将全部数据均等地分为两半的变量值. 由于中位数是位置代表值, 它不受异常数据的影响.
1.4 准确度和精确度
我们再补充对于准确度 (accuracy) 和精确度 (precision) 的定义.
准确度一般用误差刻画, 所反映出的是测量值和误差之间的差距, 差距越小则测量准确度越高.
精确度一般用方差刻画, 所反映出的是全体测量值的离散程度, 精确度越高则离散程度越低, 越接近于某一个特定的点.
2. 假设检验: $u$ 检验和 $t$ 检验
我们从一个例子开始介绍假设检验的相关概念.
某厂生产一种保健食品, 在正常情况下每瓶食品的重量服从均值为 (单位: 克) $25.0$, 标准差 $0.1$ 的正态分布, 某日开工后随机抽取 $9$ 瓶, 测得其平均重量为 $24.94$, 试问该日生产是否正常.
在这个例子中, 我们用 $X$ 表示该日生产的一瓶保健食品的重量. 由于基于实际经验标准差较为稳定, 因此可将随机变量 $X$ 视为服从正态分布 $N(\mu, 0.1^2)$, 并只需判断抽样总体的均值 $\mu$ 是否为 $25$, 如果不是的话则说明该日生产不正常. 在这里, “$\mu = 25$” 就是我们所作出的一个 假设 (Hypothesis), 记为 $H_{0}:\mu = 25$.
2.1 假设
可以从上述例子中看出, 假设就是根据问题要求所实现提出的, 关于取样总体的一个命题, 我们需要经过样本来判断这个命题对于总体而言是否成立. 我们称对提出假设进行验证的过程为 检验. 如果经过检验得到的结果是我们所作的假设 $H_{0}$ 不成立, 则称 拒绝或否定假设 $H_{0}$, 反之称为 不能否定 $H_{0}$.
如果检验的假设仅仅涉及总体分布中的参数 (如上一个例子中提到的假设 $H_0$ 就是一个关于总体分布均值的假设), 则称对这样的假设所进行的检验为 参数假设检验, 而其他所有类型的检验都称为 非参数假设检验.
对于每一个假设 $H_0$, 其对立 $H_1$ 同样可以视为假设. 我们将这一对假设分别称为 原假设 (Null Hypothesis) 和 备择假设 (Alternative Hypothesis).
2.2 基本原理和思想
假设检验的基本原理是 实际推断原理. 根据大数定律, 任意事件 $A$ 在大量重复实验中所出现的 频率 稳定于该事件出现的 概率. 因而, 如果某事件出现的概率极小, 则它在大量重复实验中所出现的频率也同样应该是极小的, 由此在单次实验中, 概率极小的事件是几乎不可能发生的, 这就是 实际推断原理.
显著性水平 是针对不同的实际问题时所人为规定的参数, 在问题中, 我们认为出现概率 不超过 显著性水平的事件为 小概率事件, 也就是认为, 这样的事件不会在仅仅一次实验中发生. 显著性水平常取 $0.1, 0.01, 0.05$ 等, 一般记为 $\alpha$.
假设检验的基本思想是基于实际推断原理作为拒绝假设 $H_0$ 的依据: 在检验假设 $H_0$ 时, 我们首先假定 $H_0$ 正确, 并构造一个在该条件下概率不超过我们所规定的显著性水平的小概率事件 $A$, 然后检验所构造的这个小概率事件在一次实验中是否发生. 如果该事件发生, 则说明与实际推断原理产生矛盾, 假设不成立, 而如果它不发生, 则我们没有得出矛盾, 无法证伪 $H_0$. 由此, 我们可以接受这个假设. 这样的检验就被称为 显著性检验.
我们还是基于开头的例子简单描述解决实际问题的具体过程:
首先, 依照题意提出假设:
\[H_0 : \mu = \mu_0 = 25, ~~ H_1 : \mu \neq \mu_0 = 25.\]随后, 构造一个在 $H_0$ 为真时的小概率事件 $A$:
\[A = \{ \vert U \vert > u_{\alpha/2} \}\] \[U = \frac{\bar{X} - \mu_0}{\sigma / \sqrt{n}}\]这个小概率事件的构造方法如下:
我们在该例中使用样本数据检验 $H_0$, 因此所需要构造的事件 $A$ 要与样本有关. 由于需要检验的假设涉及总体均值 $\mu$, 而我们又知道样本均值 $\bar{X}$ 是 $\mu$ 的 无偏估计, 因此样本均值的大小一定程度上反映了 $\mu$ 的大小. 因此, 如果假设为真, $\vert \bar{X} - \mu_0 \vert$ 不会太大 (因为 $\bar{X}$ 和 $\mu$ 非常接近, 而 $\mu = \mu_0$). 由题目条件可知, $X$ 服从一个正态分布, 因此我们构造统计量
\[U = \frac{\bar{X} - \mu_0}{\sigma / \sqrt{n}}.\]可以看出, 若假设为真, 该统计量的绝对值同样不会太大. 因此, 对于给定的显著性水平 $\alpha$, 我们只需要选择一个适当大的常数 $\lambda$, 以 ${ \vert U \vert > \lambda}$ 作为用于作为检验依据的小概率事件 $A$.
由于在假设为真时, $U \sim N(0, 1)$ (正态分布的标准化), 我们可以将 $\lambda$ 选定为正态分布的双侧 $\alpha$ 分位数. 这样, 我们就得到了这个小概率事件. 在假设检验中, 我们将 $U$ 这样的, 用于构造小概率事件的统计量称为 检验统计量.
随后我们只需要根据小概率事件 $A$ 在一次试验中发生与否对假设进行判断. 我们抽取一次样本 (即进行一次随机试验), 若 $U$ 的观察值满足 $\vert U\vert > u_{\alpha / 2}$, 则认为小概率事件 $A$ 发生了, 拒绝假设 $H_0$, 反之接受它.
我们称 $u_{\alpha / 2}$ 为 临界值, 称集合 ${\vert U\vert > u_{\alpha / 2}}$ 为 检验的拒绝域.
更笼统地, 假设检验的基本步骤可以归纳如下:
- 根据实际问题需要构造 原假设 $H_0$ 和 备择假设 $H_1$
- 根据原假设构造一个合适的检验统计量 $U$, 并且该统计量满足, 在原假设为真时, 其分布已知且与未知参数无关.
- 根据给定或选定的显著性水平 $\alpha$, 确定检验的临界值和拒绝域.
- 进行一次随机试验, 并且根据样本观察值计算所构造的统计量 $U$ 的值.
- 最后基于所确定的拒绝域判断是否接受原假设.
2.3 单个正态总体均值的检验
我们首先介绍 $u$ 检验法. 其形式如下:
- 方差已知
- 原假设形如 $H_0: \mu = \mu_0$
- 备择假设形如 $H_1: \mu \neq \mu_0$
使用 $u$ 检验法进行检验时可使用
\[U = \frac{\bar{X} - \mu_0}{\sigma / \sqrt{n}}\]作为检验统计量, 注意当原假设成立时 $U \sim N(0, 1)$.
对给定的显著性水平 $\alpha$, 检验的拒绝域为:
\[W = \{ \vert U \vert = \frac{\vert \bar{X} - \mu_0 \vert}{\sigma_0 / \sqrt{n}} > u_{\alpha / 2}\}.\]该检验法由于所使用的检验统计量服从正态分布, 因此被称为 $u$ 检验法.
我们继续介绍 $t$ 检验法. 其形式如下:
- 方差 未知
- 原假设形如 $H_0: \mu = \mu_0$
- 备择假设形如 $H_1: \mu \neq \mu_0$
由于方差未知, 我们不能再沿用在 $u$ 检验法中使用的检验统计量. 相应地, 由于样本方差
\[S^2 = \frac{1}{n-1}\sum(X_i - \bar{X})^2\]是方差 $\sigma^2$ 的无偏估计, 因此 $S^2$ 和 $\sigma^2$ 相差不大, 可以用 $S$ 代替 $\sigma$ 得到检验统计量
\[T = \frac{\bar{X} - \mu_0}{S / \sqrt{n}}\]并且在一次随机试验中观测到 $\vert T \vert$ 的值较大时拒绝原假设.
由于原假设 $H_0$ 为真时 $T \sim t(n-1)$, 因此对于给定的显著性水平 $\sigma$, 有:
\[P \{ \vert T \vert > t_{\alpha /2}(n-1)\} = \alpha,\]其拒绝域为
\[\{ \vert T \vert > t_{\alpha /2}(n-1)\}.\]该检验法由于所使用的检验统计量服从 $t$ 分布, 因此被称为 $t$ 检验法.
3. 统计学中的模拟方法 (Simulation) 和自展取样法
对于一些特殊问题, 如判定某个规则复杂的游戏是否公平, 我们难以构造出合适的检验统计量. 我们可以使用蒙特卡罗方法求得一次随机试验的观测值, 并检验其是否符合原假设 (对于考虑游戏公平与否的情况, 我们只需要判定玩家输赢的概率是否相同; 在判定玩家是否作弊时, 我们只需计算达成玩家所得成绩的概率大小即可立即确定是否接纳原假设, 而无需认为规定明确的拒绝域和临界值).
上述方法具有明显的局限性, 仅使用于特殊情况.
下面, 我们对自展取样法进行介绍.
3.2 自展取样法 (Bootstrap)
自展取样法是一种使用小样本估计总体值的非参数方法, 也是统计学中的一种 重采样 方法, 其核心思想是对原始数据进行多次有放回抽样从而生成一系列伪样本, 称为 “Bootstrap 伪样本”, 并通过对伪样本进行计算得到统计量的分布. 在初始样本足够大的前提下, 通过使用 Bootstrap 抽样, 我们可以无偏得到接近总体的分布.
4. 极大似然估计和最大后验估计
极大似然估计和最大后验估计分属 频率学派 和 贝叶斯学派 的思想成果, 两个学派对世界的认知本质上存在不同.
频率学派认为世界是确定的, 因而对任何问题而言存在不变的本体, 在解决问题时要求出它的某个真值, 而这个真值是不变的, 因而问题的本质是通过多次重复实验找到这个唯一确定的真值, 或者确定它所在的范围.
而贝叶斯学派从观测者的角度对问题建模, 认为世界是不确定的, 观测者对世界的观察如何因其获取的信息不同而异. 观测者对世界先生成某个预判, 随后根据观测数据再对这个预判进行逐步调整, 最终得到一个在当前条件下最优化的结果. 因此问题的本质是找到最优的, 描述问题的概率分布.
4.1 极大似然估计 (MLE)
极大似然估计是频率学派常用的估计方法. 在求模型参数时, MLE 认为该参数是一个定值, 而要通过解方程组的方式从数据中求得该未知数. MLE 适合在大数据量的情形下使用, 而在数据量不足时可能出现偏差.
在正式介绍极大似然估计前, 我们首先明确 似然函数 的概念.
对于给定的一个函数 \(P(x \vert \theta),\) 其输入分别为某个具体的数据, 和模型的参数.
若 $\theta$ 为一个已知量而 $x$ 为变量, 则该函数即为 概率函数, 描述在参数 $\theta$ 为真时, 不同样本点 $x$ 所对应的概率.
若 $\theta$ 为变量而 $x$ 为已知量, 则该函数即为 似然函数, 描述对于不同的模型参数 $\theta$ 而言, 样本点 $x$ 出现的概率.
下面我们解释 MLE:
设数据 $x_1, x_2, \cdots, x_n$ 为 独立同分布 的一组抽样, 记 $X = (x_1, x_2, \cdots, x_n).$ 则 MLE 对待求的模型参数 $\theta$ 的估计方法为:
可见, 上述的函数仅与变量 $\theta$ 相关. 在该函数最优化时, 也就是函数值最大时, 所对应的 $\theta$ 值即为我们所要求的, 使得该似然函数取得极大值, 将已观测到的观测序列的似然最大化的模型参数, 由此我们完成了对 $\theta$ 的 极大似然估计.
4.2 极大后验估计 (MAP)
极大后验估计是贝叶斯学派的常用估计方法. MAP 的假设是 “待求的模型参数源于某种潜在分布, 而需要从数据中推得该分布”. 在先验假设可信的前提下效果显著, 而先验假设在计算模型参数过程中的主导作用会随着数据量的增加而被逐步削弱. 极端情形下, 如完全不考虑先验假设或先验假设满足均匀分布, 极大后验估计和极大似然估计没有差别.
设数据 $x_1, x_2, \cdots, x_n$ 为 独立同分布 的一组抽样, 记 $X = (x_1, x_2, \cdots, x_n).$ 则 MAP 对待求的模型参数 $\theta$ 的估计方法为: