
Ch9 汇编器和编译器
1. 汇编器 Assembler
汇编器的主要作用是将程序设计者使用助记符编写的汇编程序翻译为可以被硬件直接读取和执行的二进制码.
一个最简单的汇编器应该能做到:
- 识别并删去程序中的注释
- 识别标签和被定义的有名常量:
1 2
height_senpai EQU 170 ; "height_senpai" is a named constant compare SUB R0, R0, #height_senpai ; "#height_senpai" is a named constant, "compare" is a label
- 正确地识别表示指令的助记符
- 正确识别代表数据或位于内存中的变量空间的助记符
- 可以正确地为每一个指令, 数据等分配空间
- 正确指定每一个常量和标签的值
- …以及能够正确地将文字指令, 数据定义, 数据值等转换为二进制码
汇编器所生成的代码往往不是在计算机上独占运行的, 它的运行环境一般会受操作系统的限制和控制, 这导致对于汇编器而言, 它并不能确定编译出的程序将来在执行时, 自身所处的内存位置和所使用的数据, 程序内所执行的分支跳转所处的内存位置, 但二进制机器码一般需要具有可重定位性 (Relocatable), 可以在任何内存地址处执行. 这就需要汇编器在执行汇编时, 使用 相对内存地址.

在汇编过程中, 汇编器将会对使用文字编写的程序进行扫描和翻译. 对于顺序结构的程序而言, 这样的扫描只需要进行一次:
1
2
3
MOV R1, #17 ;E3A01011
MOV R2, #20 ;E3A02014
ADD R0, R1, R2 ;E0810002
而对于含有距离较远的变量调用, 向前分支, 以及诸如 ADRL 一类的, 基于地址的伪指令的复杂汇编程序, 就需要进行多次扫描和处理才能完成程序的二进制汇编过程:

下面以一个对向前分支的处理为例:
1
2
3
4
00000018: BA000001 ; BLT Lower
0000001C: E3A0002B ; MOV R0, #'+'
00000020: EA000000 ; B Print
00000024: E3A0002D ;Lower MOV R0, #'-‘
在对这段代码进行汇编时, 汇编器必须遍历整段代码两遍:
在第一遍中, 汇编器将为每一个指令或数据分配一个内存地址, 并将所遇到的每一个标签或变量名和对应的数值在 “符号表” (Symbol Table) 中关联起来, 并且检测符号定义是否重复.
在第二遍时, 汇编器才会将标签或变量名用对应的值替代, 并将每一条指令都转为二进制机器码.
下面以 ADRL 指令为例考虑一个更复杂的例子:
ADRL 是一个利用程序计数器 PC 的值实现更大范围数据读取的伪指令. 它将基于 PC 值的相对偏移的地址值读取至寄存器中:
1
2
3
4
5
ADRL R0, thestring
; if thestring is close to R0, then it will be converted into the instruction as follow:
ADD R0, PC, #(thestring-[PC]) ; #(thestring-[PC]) is the offset
; the offset is calculated by the assembler and put into ADD instruction...
; ...as an literal offset
显见, 汇编器需要至少两次代码遍历才能完成对 ADRL 伪指令的汇编:
在第一次汇编中, 伪指令所需要的偏移量暂时无法被计算. 在第一次代码扫描过程中得到了其中一个指令操作符的地址 thestring 后, 汇编器才能在第二遍代码扫描时计算和提供伪指令所需的偏移量.
若计算出的偏移值大到无法被作为一个 “文字” 放到单独的一条指令中, 就需要一条额外的指令实现对其访问; 而若使用两条指令都无法完成访问的话, 程序编译就会报错 (假定 ADRL 伪指令最多只能被编译成 $2$ 条指令的情况) 或需要更多的指令.
下面我们研究汇编器如何将人类所编写的汇编程序源码转换为机器码:
汇编器执行代码转换的过程基本分为以下四步:
- 词法分析 (
Lexical Analysis):
将字符串/字符序列转换为标记 (token) 序列 - 语法分析 (
Syntactic Analysis):
从标记序列中识别指令, 并判断识别出的指令是否合法 - 语义分析 (
Semantic Analysis):
为指令中所定义的有名变量找到对应值. - 机器码生成 (
Binary Code Generation):
生成最终的二进制机器码.
一段标准的汇编程序源码可能由标记, 助记符, 操作数, 常量或文字, 地址, 注释和分隔符组成. 在第一次扫描中, 汇编器将逐字扫描源码, 并基于空格, 逗号等汇编语言所定义的分隔符以及汇编语言语法识别出不同种类的标记和词法单位, 并按照语法规则判断代码是否合法.
在第二次扫描里, 汇编器将尝试找到在第一次扫描中识别出的符号所对应的值, 并将符号用找到的值所替代.
最终, 汇编器将使用语法分析和语义分析所得到的结果生成二进制机器码: 每一条指令中的每一个组成部分都唯一映射到一个二进制码.
2. 编译器 Compiler
下面我们研究编译器 (Compiler):
编译器是一种能够将一种计算机语言无损翻译为另外一种语言的程序, 其主要作用是通过实现从高级程序语言到汇编语言的翻译过程, 作为高级程序语言和较底层的汇编语言之间的桥梁, 它通过最小化高级程序设计语言的程序执行开销促进了这类语言的利用.

实际上, 除了编译器外, 我们还需要多个其他的程序才能实现高级程序语言的运行:
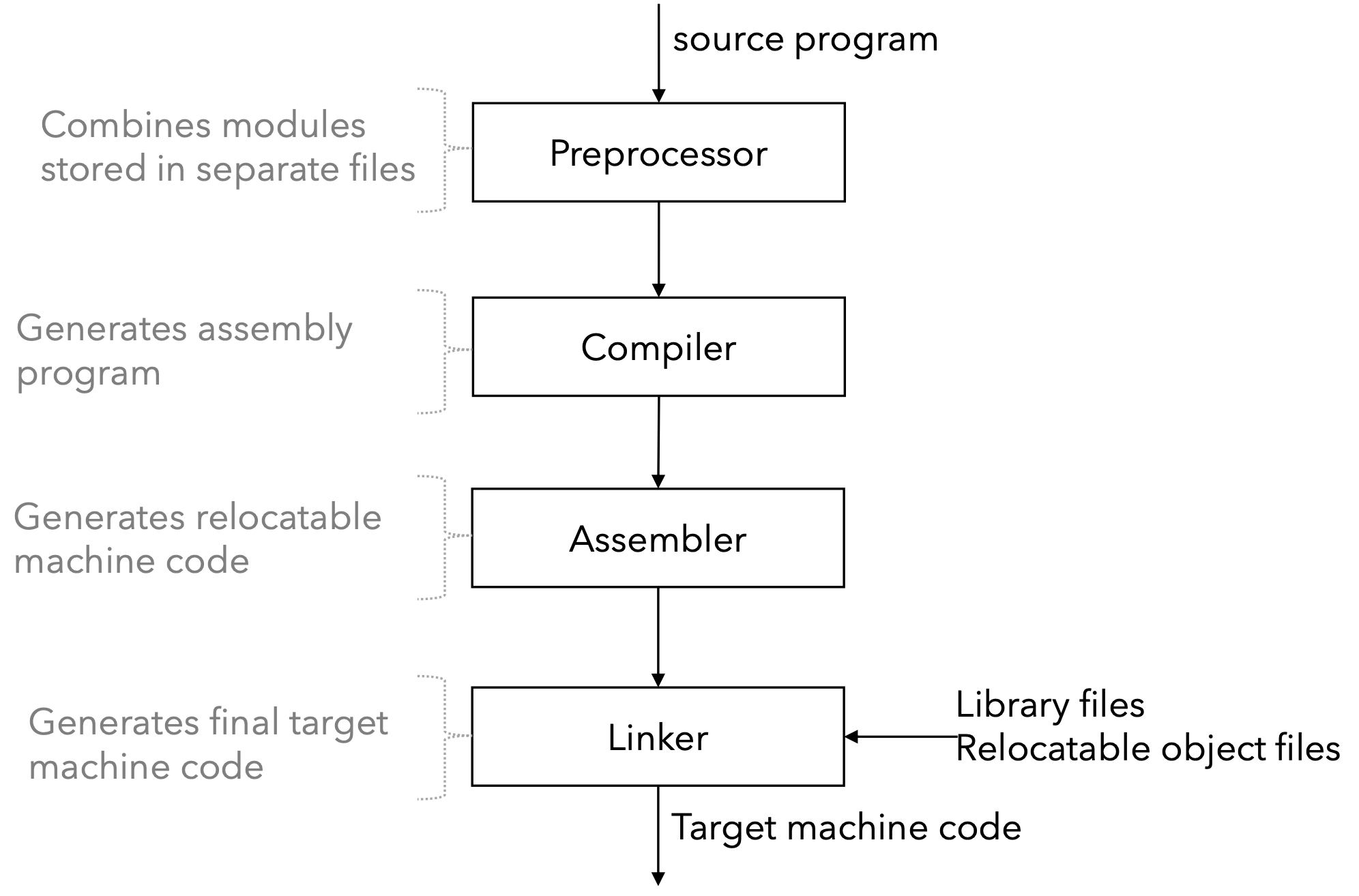
编译器由分析部分 (Analysis) 与合成部分 (Synthesis) 两部分构成:
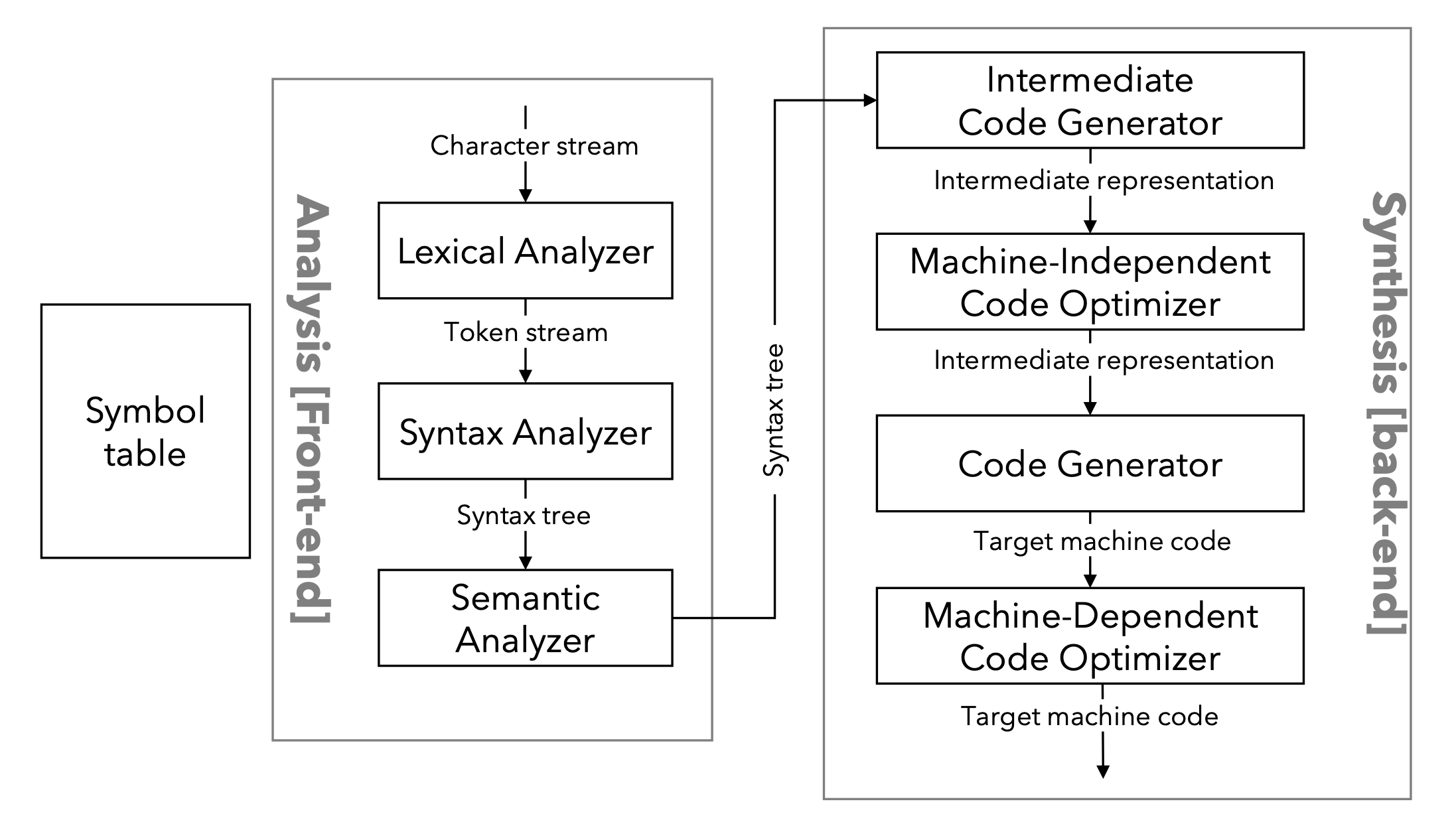
分析部分由 词法分析, 语法分析 和 语义分析 组成:
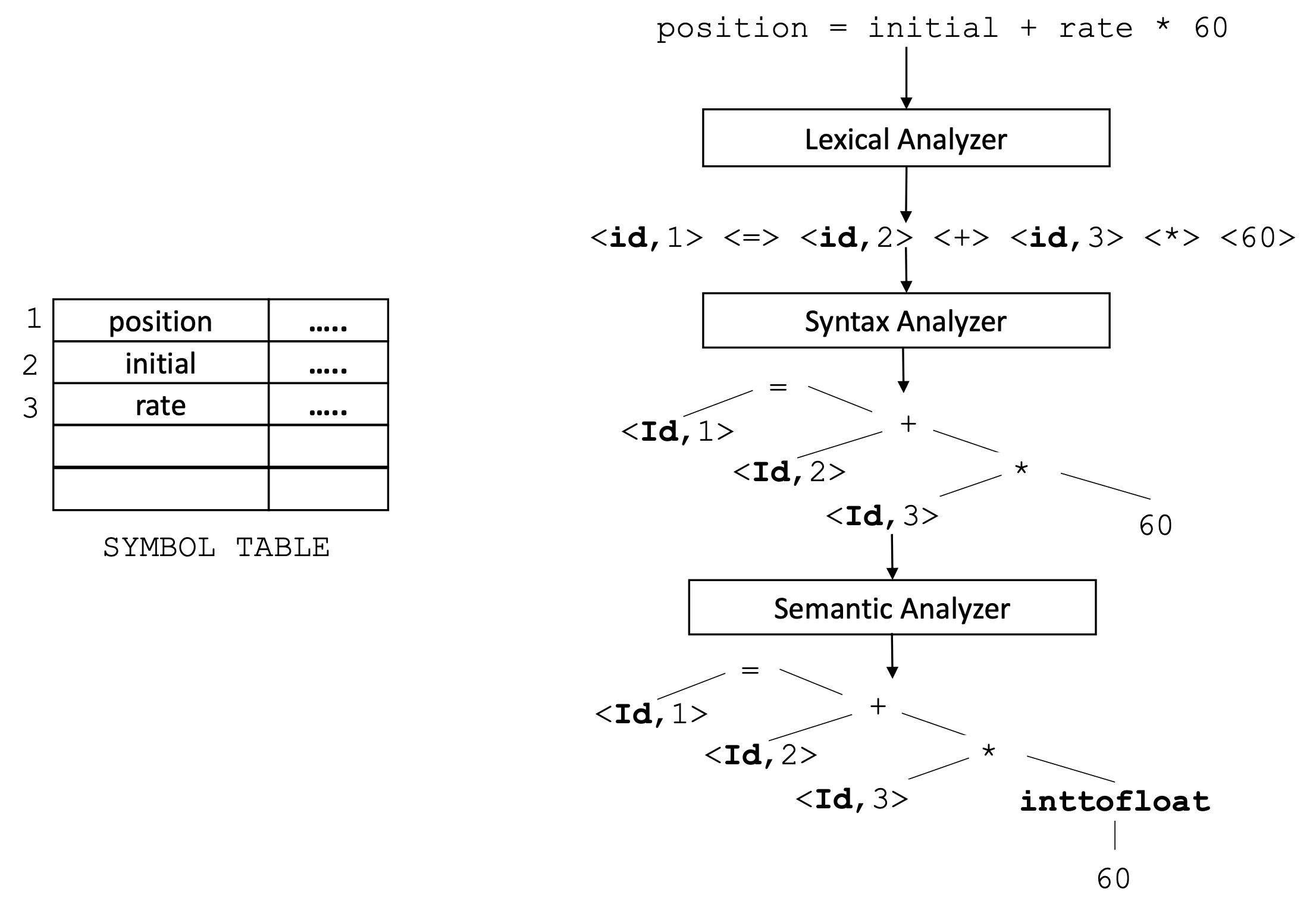
- 词法分析:
读取源程序的输入字符, 将它们分组为词素, 并为每个词素生成一系列形式为<token-name, attribute-value>的标记序列. - 语法分析:
使用在词法分析中得到的标记序列生成表示标记流token stream的语法结构的树状中间表示形式Tree-Like intermediate representation. - 语义分析:
使用语法树 (Syntax Tree) 和符号表 (Symbol Table) 中的信息, 基于程序语言的定义检查原程序的语义一致性.
合成部分由 中间层代码生成器, 代码优化 和 代码生成器 构成:
- 中间层代码生成器 (
Intermediate Code Generation):
生成易于被翻译为目标硬件机器码的精确伪机器码. (基于抽象的硬件生成的机器码) - 代码优化:
基于生成的, 与具体硬件无关的抽象机器码进行尽可能的性能优化. -
代码生成:
以经过优化的抽象机器码为源码, 基于目标语言生成最终的代码.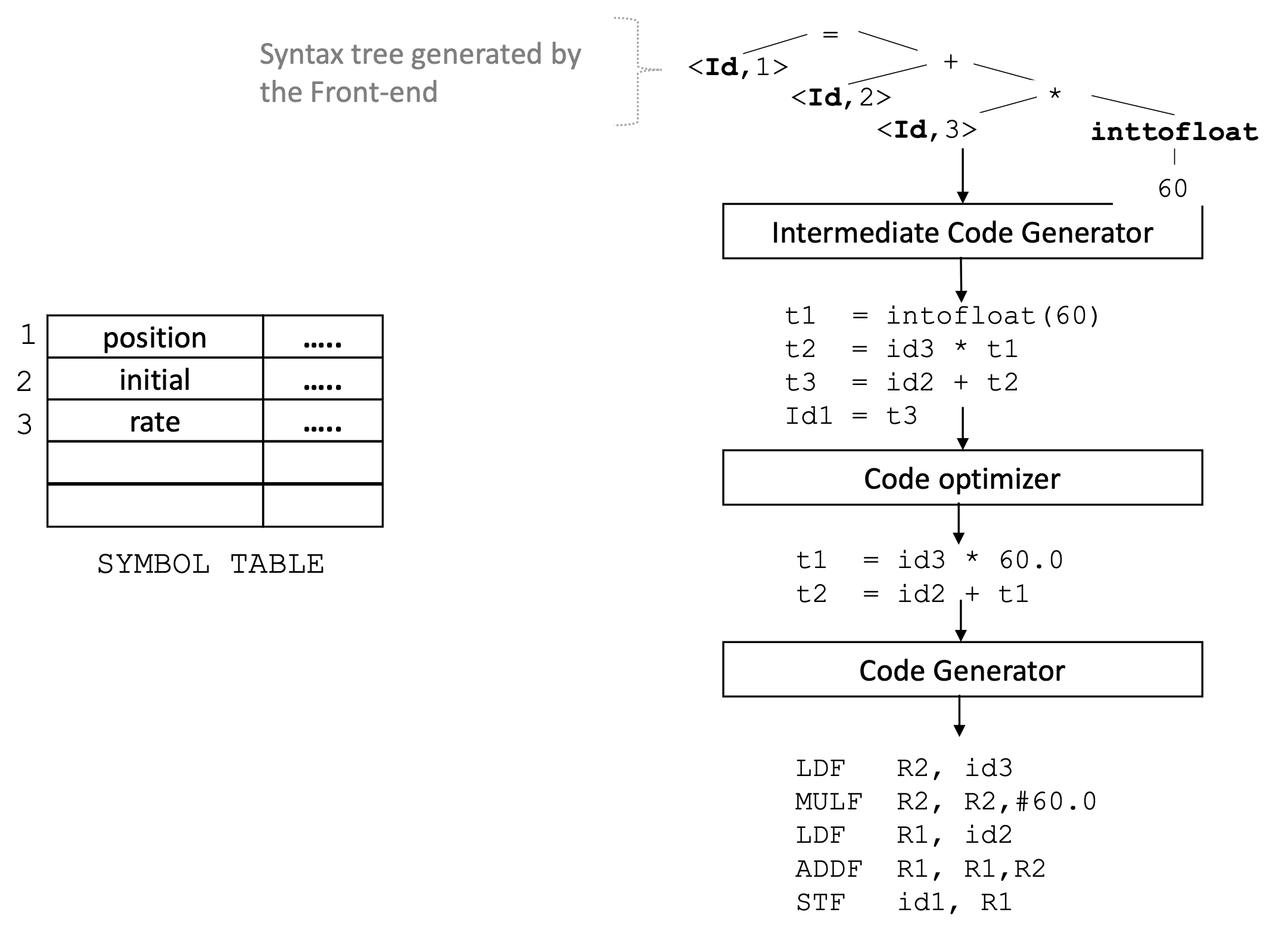
最后, 我们将汇编器和编译器的差别列表如下:
| - | 编译器 | 汇编器 |
|---|---|---|
| 职能 | 生成汇编程序码 | 生成机器码 |
| 输入 | (高级程序设计语言的)源代码 | 汇编程序码 |
| 处理流程 | 进行词法, 语法, 语义分析, 以及中间层代码生成和优化, 最终代码生成 | 通过几次全源码扫描实现汇编语言的转译, 不进行任何优化 |
| 输出 | 汇编程序码, 也就是机器码的助记符形式 | 二进制机器码 |